新しい非同期ノンブロッキングフレームワークの出現のプレッシャーの下では、ブロックされた呼び出しは過去の遺物であり、すべての新しいサービスは完全に非同期のアーキテクチャで記述される必要があるように思われるかもしれません。 この投稿では、通常のブロッキング呼び出しを優先して、非ブロッキング非同期バックエンド呼び出しを放棄することにした方法を説明します。
HeadHunterアーキテクチャには、他のサービスからデータを収集するサービスがあります。 たとえば、検索クエリの空席を表示するには、次のものが必要です。
- 空席の「アイデンティティ」の検索バックエンドに移動します。
- 説明については、ジョブバックエンドにアクセスしてください。
これは最も単純な例です。 多くの場合、このサービスには多くのロジックがあります。 私たちはそれを「ロジック」と呼んでさえいました。
もともとはpythonで書かれていました。 論理の存在の数年の間、それらはすべてそれで蓄積しました。 借金。 また、開発者は、ほとんどのバックエンドを作成したpythonとjavaの両方を掘り下げる必要性に熱心ではありませんでした。 そして、なぜJavaでロジックを書き換えないのかと考えました。
さらに、Pythonロジックはプログレッシブで、非同期の非ブロッキングトルネードフレームワーク上に構築されています。 「バックエンドに行くときにブロックするかしないか」という問題は解決しませんでした。PythonのGILのため、スレッドの実際の並列実行はありません。
しかし、javaに切り替えると、反転したコールバックコードを書き続けるかどうかをもう一度評価することにしました。
def search_vacancies(query): def on_vacancies_ids_received(vacancies_ids): get_vacancies(vacancies_ids, callback=reply_to_client) search_vacancies_ids(query, callback=on_vacancies_ids_received)
もちろん、コールバックの地獄は滑らかにすることができます。 たとえば、Java 8ではCompletableFutureが登場しました。 まだAkka、Vert.x、Quasarなどの方向を見ることができます。しかし、新しいレベルの抽象化は必要ないかもしれません。通常の同期ブロッキング呼び出しに戻ることができますか?
def search_vacancies(query): vacancies_ids = search_vacancies_ids(query) return get_vacancies(vacancies_ids)
この場合、各リクエストを処理するためのストリームを割り当て、バックエンドに行くと、結果を受信するまでブロックされ、実行を続けます。 リモートサービスが呼び出されたときにスレッドをブロックすることについて話していることに注意してください。 要求を減算し、結果をソケットに書き込むことは、ブロックせずに実行され続けます。 つまり、ストリームは接続ではなく、準備完了リクエストに割り当てられます。 スレッドブロッキングが潜在的に悪いのはなぜですか?
- 各スレッドはスタック用のメモリを必要とするため、大量のメモリが必要になります。
- スレッドコンテキスト間の切り替えは無料の操作ではないため、すべてが遅くなります。
- バックエンドが鈍い場合、プールに空きスレッドはありません。
必要なスレッド数を把握し、これらの問題に気付くかどうかを評価することにしました。
いくつのスレッドが必要ですか?
下限を評価することは難しくありません。
pythonロジックに次のログがあると仮定します。
15:04:00 400 ms GET /vacancies 15:04:00 600 ms GET /resumes 15:04:01 500 ms GET /vacancies 15:04:01 600 ms GET /resumes
2番目の列は、要求の受信から応答までの時間です。 つまり、処理されるロジック:
15:04:00 - 1000 ms 15:04:01 - 1100 ms
各リクエストを処理するためにストリームを割り当てると、次のようになります。
- 15:04:00に、理論的には1つのスレッドで処理できます。最初にGET / vaccanciesリクエストを処理し、次にGET /再開リクエストを処理します。
- ただし、15:04:01には少なくとも2つのスレッドを割り当てる必要があります。1秒間に1つのスレッドが1秒以上のリクエストを処理できないためです。
実際、Pythonロジックで最も忙しい時間では、このような合計リクエスト期間は次のようになります。
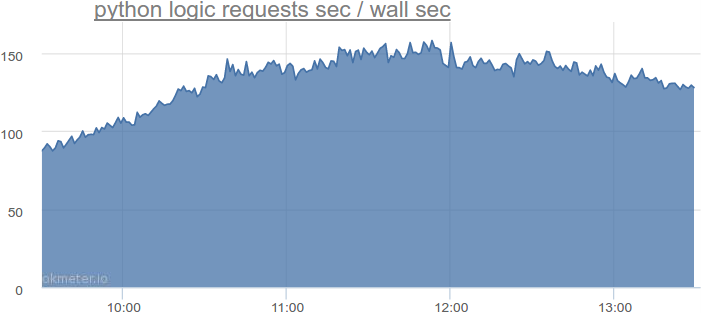
1秒あたり150秒を超えるクエリ。 つまり、150を超えるスレッドが必要です。 この番号を覚えておいてください。 しかし、リクエストが不均等に着信すること、リクエストを処理した直後にスレッドがプールに返されないこともありますが、少し遅れることなども考慮に入れる必要があります。
データベースにアクセスするときにブロックされる別のサービスを使用して、必要なスレッド数を確認し、数値を推定しましょう。 たとえば、招待および応答サービスは次のとおりです。
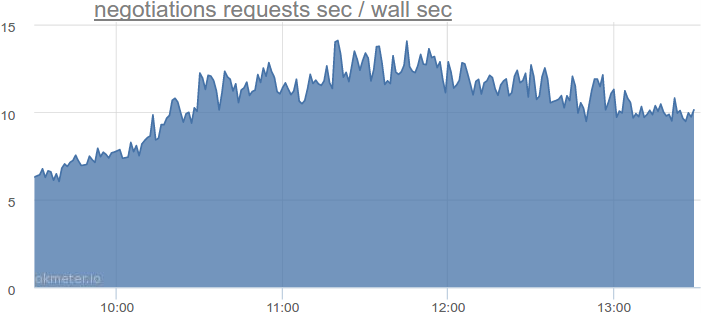
1秒あたり最大14秒のクエリ。 スレッドの実際の使用はどうですか?
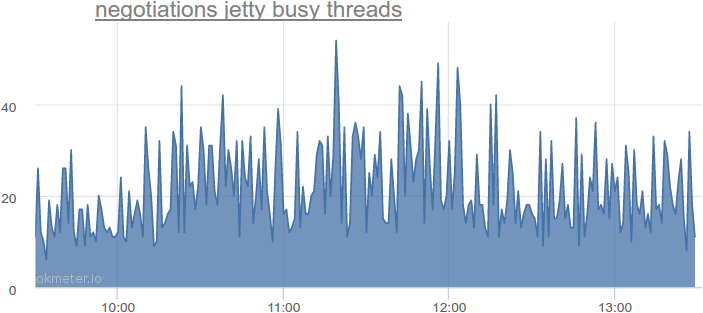
同時に使用される最大54のフロー。これは、理論上の最小量と比較して2〜4倍です。 私たちは他のサービスを見ました-同様の写真があります。
ここでは、少し余談します。 HeadHunterはhttpサーバーとしてjettyを使用しますが、他のhttpサーバーは同様のアーキテクチャを使用します。
- すべてのリクエストはタスクです。
- このタスクは、スレッドプールの前にキューに入れられます。
- プールに空きフローがある場合、キューからタスクを取得して実行します。
- フリーフローがない場合、タスクはフリーフローが現れるまでキューに置かれます。
リクエストがしばらくキューに置かれることを恐れない場合は、計算された最小値よりも少し多くのスレッドを割り当てることができます。 ただし、遅延を最小限に抑えるには、より多くのスレッドを割り当てる必要があります。
4倍のスレッドを割り当てましょう。
つまり、すべてのPythonロジックをロックアーキテクチャを備えたJavaロジックに転送する場合、150 * 4 = 600スレッドが必要です。
負荷が2倍に増加すると想像してみましょう。 次に、CPUに実行しない場合、1200のスレッドが必要になります。
バックエンドが愚かであり、リクエストの処理に2倍の時間がかかることを想像してください。2400のスレッドがありますが、それ以降はさらに時間がかかります。
pythonロジックは4つのサーバーで回転しています。つまり、それぞれに2400/4 = 600のスレッドがあります。
600スレッドは多いですか?
数百のスレッド-それはたくさんですか、それとも少しですか?
デフォルトでは、64ビットマシンでは、javaはストリームスタックに1 MBのメモリを割り当てます。
つまり、600スレッドには600 MBのメモリが必要です。 災害ではありません。 さらに、これは600 MBの仮想アドレス空間です。 物理RAMは、このメモリが本当に必要な場合にのみ使用されます。 1 MBのスタックはほとんど必要なく、多くの場合512 KBに固定されます。 この意味で、600スレッドも1000スレッドも問題ではありません。
スレッド間のコンテキスト切り替えのコストはどうですか?
以下に簡単なJavaテストを示します。
- サイズ1、2、4、8 ... 4096のスレッドのプールを作成します。
- 16 384個のタスクを投入します。
- 各タスクは、乱数を追加する600,000回の反復です。
- すべてのタスクの完了を待っています。
- テストを2回実行してウォームアップします。
- テストをさらに5回実行し、平均時間を取ります。
static final int numOfWarmUps = 2; static final int numOfTests = 5; static final int numOfTasks = 16_384; static final int numOfIterationsPerTask = 600_000; public static void main(String[] args) throws Exception { for (int numOfThreads : new int[] {1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096}) { System.out.println(numOfThreads + " threads."); ExecutorService executorService = Executors.newFixedThreadPool(numOfThreads); System.out.println("Warming up..."); for (int i=0; i < numOfWarmUps; i++) { test(executorService); } System.out.println("Testing..."); for (int i = 0; i < numOfTests; i++) { long start = currentTimeMillis(); test(executorService); System.out.println(currentTimeMillis() - start); } executorService.shutdown(); executorService.awaitTermination(1, TimeUnit.SECONDS); System.out.println(); } } static void test(ExecutorService executorService) throws Exception { List<Future<Integer>> resultsFutures = new ArrayList<>(numOfTasks); for (int i = 0; i < numOfTasks; i++) { resultsFutures.add(executorService.submit(new Task())); } for (Future<Integer> resultFuture : resultsFutures) { resultFuture.get(); } } static class Task implements Callable<Integer> { private final Random random = new Random(); @Override public Integer call() throws InterruptedException { int sum = 0; for (int i = 0; i < numOfIterationsPerTask; i++) { sum += random.nextInt(); } return sum; } }
以下は、クアッドコアi7-3820、ハイパースレッディングが無効、Ubuntu Linux 64ビットでの結果です。 最適な結果は、4つのスレッド(コアの数)を持つプールで表示されると予想されるため、残りの結果と比較します。
| スレッド数 | 平均時間、ミリ秒 | 標準偏差 | 差% |
|---|---|---|---|
| 1 | 109152 | 9.6 | 287.70% |
| 2 | 55072 | 35.6 | 95.61% |
| 4 | 28153 | 3.8 | 0.00% |
| 8 | 28142 | 2,8 | -0.04% |
| 16 | 28141 | 3.6 | -0.04% |
| 32 | 28152 | 3,7 | 0.00% |
| 64 | 28149 | 6.6 | -0.01% |
| 128 | 28146 | 2,3 | -0.02% |
| 256 | 28146 | 4.1 | -0.03% |
| 512 | 28148 | 2.7 | -0.02% |
| 1024 | 28146 | 2,8 | -0.03% |
| 2048 | 28157 | 5,0 | 0.01% |
| 4096 | 28160 | 3.0 | 0.02% |
4と4096のフローの違いは、エラーに匹敵します。 したがって、コンテキストの切り替えのオーバーヘッドという点では、600スレッドは問題ではありません。
そして、バックエンドが鈍い場合は?
バックエンドの1つが私たちを鈍らせ、今ではそれへのリクエストに2、4、10倍の時間がかかると想像してください。 これにより、すべてのスレッドがブロックされ、このバックエンドを必要としない他のリクエストを処理できなくなります。 この場合、いくつかのことができます。
まず、さらに多くのスレッドを予約しておきます。
次に、ハードタイムアウトを設定します。 タイムアウトを監視する必要があります。これは問題になる可能性があります。 非同期コードを書く価値はありますか? 質問は公開されています。
第三に、誰も私たちにすべてを同期スタイルで書くことを強制しません。 たとえば、バックエンドの問題が予想される場合、非同期スタイルでいくつかのコントローラーを作成できます。
したがって、負荷のかかるバックエンドハイキングサービスでは、主にロックアーキテクチャを選択しました。 はい、タイムアウトを監視する必要があり、100倍に迅速にスケーリングすることはできません。 しかし、一方で、シンプルでわかりやすいコードを記述し、ビジネス機能をより迅速にリリースし、サポートに費やす時間を減らすことができます。