UAEにあるアザドイスラム大学のコンピューターテクノロジー学部の科学者は、ニューラルネットワークテクノロジー、遺伝的アルゴリズム、参照ベクトルを使用したデータマイニングに基づいて株価指数の挙動を予測する論文を発表しました。 このドキュメントの主な考えに注目してください。
はじめに
近年の財務分析で最も人気のある分野の1つは、過去の取引期間のデータに基づいて株価と株価指数の動きを予測することです。 関連する結果を得るには、適切なツールと正しいアルゴリズムの使用が必要です。
科学者は、予測アルゴリズムと数学ルールを使用して株価指数の振る舞いの予測を生成できる特別なソフトウェアの開発を目標として設定しました。
株価指数自体は、経済的な出来事に依存するだけでなく、世界のさまざまな地域の政治状況の影響を受けるため、予測不可能です。 したがって、このような予測不可能な非線形のノンパラメトリックな時系列を処理するための数学モデルを開発することは非常に困難です。
株式市場で働く場合、2種類の分析が使用されます。
1)テクニカル分析
短期的な財務戦略に使用されます。 過去の同様の方法で、パターンと価格の変化に基づいて価格の変化を予測するために使用されます。 原則として、価格チャートが分析され、価格ダイナミクスの特定のパターンのパターンが強調表示されます。 テクニカル分析では、価格変動のダイナミクスの研究に加えて、取引量に関する情報やその他の統計データを使用します。
2)基礎分析
長期投資戦略では、ファンダメンタル分析が使用されます。 特定の会社の株価を予測するために、その活動の金融および産業指標に関する情報を使用することを意味します。
また、起こりうる価格の動きを予測する際には、金融市場に存在するリスクを理解する必要があります。
- 取引リスク -トレーダーがリスクを負う資金の量。 たとえば、1,000ドル相当の金融資産を購入した場合、取引リスクはこの金額に等しくなります。
- 市場リスク -とりわけ、世界的な経済的出来事または金融市場が位置する特定の国の出来事、または証券取引所で取引されている企業の株式の影響下で、市場で起こりうること。
- マージンリスク -借入資金を使用して取引を完了すると、限界リスクが発生します。 たとえば、ブローカーから借りたお金は最終的に返済する必要があり、トレーダーがこれのための口座に十分な自由資金がない場合、彼の取引戦略によって暗示されていなくても彼のポジションは強制的に閉じられます。
- 流動性リスク -すべての金融商品がすぐに「終了」できるわけではありません。
- トレーダーは取引所が機能していないときに何が起こるかを知ることができないため、 ポジションのオーバーナイト移転のリスク -トレーディング日またはトレーディング日の間のポジションの維持はリスクを伴います。 おそらく、何らかのイベントが取引日の開始に影響を及ぼし、投資家にとって株価はすぐに好ましくない方向にシフトします。
- ボラティリティのリスク -株価は特定の範囲で変動します。 価格変動の範囲が広いほど、特定の金融商品のボラティリティが高くなります。
株価指数の振る舞いを予測する
株価の予測の問題を解決するために使用される一般的なツールの1つは、決定木です。 同様に、データを収集および分析する最も効果的な方法は、データマイニングです。 データマイニングの使用にはいくつかのモデルがあり、受信した情報の収集と分析に対するさまざまなアプローチを実装しています。
私たちのケースでは、研究者はCRISP-DM(データマイニングのクロスID標準プロセス)モデルを選択しました。 この方法は、前世紀の90年代半ばにヨーロッパ企業のコンソーシアムによって開発されました。 モデルには7つの基本的な手順が含まれます。
- 情報検索の目標の定義(必要な在庫に関するデータ)。
- 必要なデータを検索します。
- 分類モデルのデータの順序付け。
- モデルの実装のための機器の選択。
- 既知の方法を使用したモデル評価。
- 現在の市場条件でのモデルの適用。たとえば、株式の売買など、ターゲットアクションに関する推奨事項を生成します。
- 結果の評価。
データを収集した後、分類ツリーを使用して決定を下します。 このアプローチには、3つの主な利点があります。高速でシンプルであり、高精度を実現できます。 この場合、前の価格、始値、最大値、最小値、終値、およびターゲットアクション(前、始値、最大値、最小値、最後のアクション)がモデルパラメーターとして選択されました。
遺伝的アルゴリズムは予測にも使用されます。 関係する要素間の正確な関係が不明であり、原則として存在しない場合に、複雑な問題を解決するために使用されます。
問題は形式化されているため、その解決策は遺伝子のベクトル(「遺伝子型」)の形式でエンコードでき、各遺伝子はビット、数、またはその他のオブジェクトを表すことができます。 次に、初期の「集団」の多くの遺伝子型がランダムに作成され、特別なフィットネス関数を使用して評価されます。 その結果、各遺伝子型には「適合性」の値が割り当てられます。問題をどの程度うまく解決できるかが決定されます。
取引戦略に含まれるパラメーターを常に最適化するには、最適化手法が使用されます。 たとえば、遺伝子はベクターとして表すことができ、対応する最適化アルゴリズムは中間組換えメカニズムを適用します。
将来の価格変動に関する予測を生成する方法の1つは、機械学習です。 この場合、研究者はサポートベクター法を使用しました。 研究者は、NASDAQ取引所からいくつかの金融商品とインデックスに関する財務データを収集しました。 NASDAQの結果、システムによって生成された予測の精度は、74.4%、DJIAインデックスで77.6%、S&P500で76%でした。
機械学習では、次の式が使用されました。
まず、x i (t)が決定されました。ここで、i∈{1、2、...}です。
F =(X 1 、X 2 、... X n ) T 、ここで

使用したモデルを評価するために、二乗平均平方根誤差の計算方法(RMSE、二乗平均平方根誤差)を使用しました。

マルチクラス分類
リスクを最小限に抑え、利益を増やすために、サポートベクターモデルが使用されます。 これには、データをポジティブ、ネガティブ、ニュートラルの3つのカテゴリに分類することが含まれます。 これは、最もリスクの高い予測を特定して拒否するのに役立ちます。 このようなマルチクラス分類器を作成するには、中央ゾーンの幅を決定する必要があります。

tp:真陽性
fp:誤検知
fn:偽陰性
提案モデル
上記のように、収集されたデータには6つの属性がありました。 決定木で使用するには、データを離散値に変換する必要があります。 これを行うには、市場終値に基づく基準を使用できます。 現在の取引日にopen、max、min、lastの値が前の属性値を超える場合、正の値は前の属性に置き換えられます。 反対に、前の属性の代わりに負の値が設定され、値が等しい場合、対応する属性が設定されます。
これは、6つの属性のデータセットが離散値に変換される前の様子です。
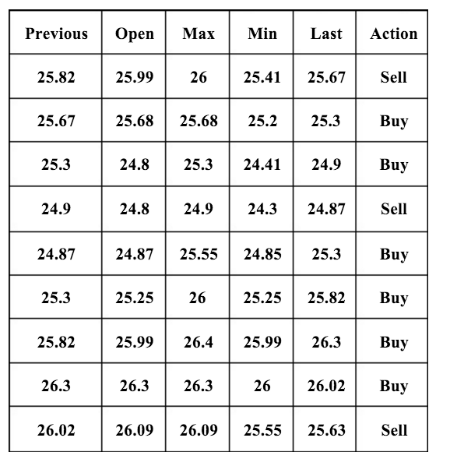
そして、翻訳後:

このような離散値のセットを取得した後、決定木を使用して分類モデルを構築する必要があります。
この調査では、実行可能な2つのシナリオを検討します。
スクリプト#1
次のアクションを実行する必要があります。
- 30日間、オークションで財務データを収集します。
- 1取引日の9つの時点で6つの属性のデータを選択します。
- 各セットのマトリックスを作成します。
- XX ^ Tを計算し、サポートベクトル法を適用して固有値を生成します。
- 平均売上と購入の計算。
- 各取引日の平均値の計算。
- 1日目、7日目、30日目に異なる重みを割り当て、月の平均値を割り当てます。
- アクションの推奨事項を生成するには、現在の値を1日目、7日目、30日目、および月全体の平均値と比較する必要があります。
- 4取引日の予測結果が同じである場合、購入する必要があります。3取引日の一致がある場合、購入のリスクは25%になり、2日間のリスクは50%になります。
30日のうちの各取引日について、Xiが1日の9つの異なる瞬間を表す行列を生成する必要があります。

その後、R = XX Tが計算されます-各行列に転置バージョンを乗算する必要があります。 次に、参照ベクトルとその固有値が計算されます。
シナリオ2
この場合、同じ手順が実行されますが、サポートベクトル法は生データに適用されず、自己相関後に取得された行列に適用されます。 取引日ごとに自己相関マトリックスが生成されます。

ここでは次の式が使用されます。

自己相関の後、新しい行列( Toeplitz行列 )を取得します。

そして、すでにそのために、参照ベクトルと固有値が計算されます。 さまざまな取引日の平均値からの偏差を比較するために、平均値、分散、標準偏差が計算され、ベクトルに保存されます。
おわりに
最良の結果を得るために、研究者は説明されたすべての方法を段階的に適用しました。基本的な分析から始め、遺伝的アルゴリズム、ニューラルネットワーク、機械学習、サポートベクトル法を使用しました。

同時に、株価指数の値の変化の予測の絶対的な精度を達成することはできませんでした。 さまざまな金融商品では、1取引日の間隔でのインデックスの動作を予測する精度はまったく異なります。
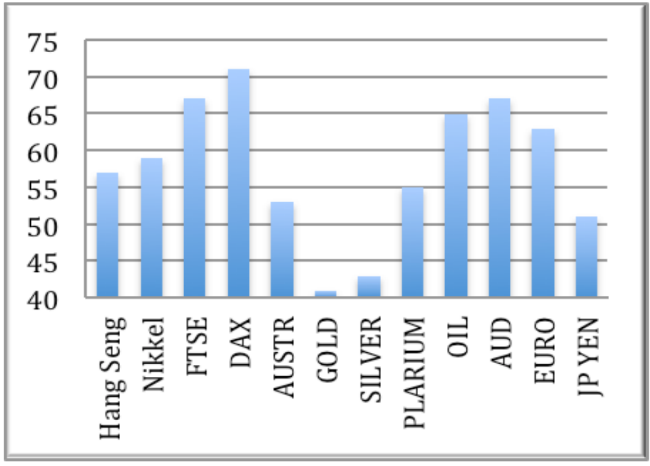
最良の結果は、ドイツのDAXインデックスの精度が70.8%でした。 長期予測(30日を超える期間)でより高い精度を達成するために、次の式が使用されました。
Pr {v t + 1 -v t > c t }、ここでc t =-(v t-ts -v t )
この場合、最高の予測精度の結果は85.0%でした。