ただし、これらすべてのために、コンパイラーという小さなものが1つ欠けています。
はい、多くの人がコンパイラを重要なものと見なしていないことを知っています。誰もが厳密にアセンブラでプログラミングするべきだと信じています。 あなたもそう思うなら、私はあなたと議論しないでください、ただ読んでいないでください。
元のアーキテクチャで少なくともC言語を使用できるようにする場合は、catを使用してください。
この記事では、LLVMコンパイラインフラストラクチャを使用して、それに基づいたカスタムソリューションを構築する方法について説明します。
LLVMの範囲は、新しいプロセッサー用のコンパイラーの開発に限定されません.LLVMコンパイラーインフラストラクチャは、新しいプログラミング言語、新しい最適化アルゴリズム、プログラムコードの静的分析(エラーの検索、統計の収集など)用のコンパイラーの開発にも使用できます。
たとえば、いくつかの標準プロセッサ(たとえばARM)を特殊なコプロセッサ(たとえばマトリックスFPU)と組み合わせて使用できます。その場合、FPU用のコードを生成できるように、既存のARMコンパイラを変更する必要があります。
また、LLVMの興味深いアプリケーションは、高レベル言語でのソーステキストの生成(ある言語から別の言語への「翻訳」)です。 たとえば、Cのソースコードを使用してVerilogコードジェネレーターを記述できます。

KDPV
なぜLLVMなのか?
現在、独自のアーキテクチャ用のコンパイラを開発する現実的な方法は、GCCを使用するかLLVMを使用する2つだけです。 他のオープンソースコンパイラプロジェクトは、GCCやLLVMなどの開発レベルに達していないか、時代遅れで開発を停止しており、最適化アルゴリズムを開発しておらず、C言語標準との完全な互換性を提供していない場合があります。プログラミング言語。 独自のコンパイラを「ゼロから」開発することは非常に非合理的な方法です。既存のオープンソースソリューションは、多くの非常に重要な最適化アルゴリズムを備えたコンパイラフロントエンドを既に実装しているためです。
これら2つのオープンソースプロジェクトのうち、コンパイラのベースとして選択すべきものはどれですか? GCC(GNU Compiler Collection)は古いプロジェクトで、最初のリリースは1987年に行われました。その著者は、オープンソース運動で有名なRichard Stallmanです[4]。 C、C ++、Objective-C、Fortran、Java、Ada、Goなどの多くのプログラミング言語をサポートしています。 メインアセンブリに含まれていない他の多くのプログラミング言語のフロントエンドもあります。 GCCコンパイラは、多数のプロセッサアーキテクチャとオペレーティングシステムをサポートしており、現在最も一般的なコンパイラです。 GCC自体はCで記述されています(コメントでは、ほとんどがC ++ですでに書き直されていることが修正されました)。
LLVMははるかに「若く」、2003年に最初のリリースが行われ、より正確にはClangフロントエンドがC、C ++、Objective-CおよびObjective-C ++プログラミング言語をサポートし、Common Lisp、ActionScript、Adaの言語のフロントエンドも備えています、D、Fortran、OpenGLシェーディング言語、Go、Haskell、Javaバイトコード、Julia、Swift、Python、Ruby、Rust、Scala、C#、およびLua。 米国イリノイ大学で開発され、OS Xオペレーティングシステムでの開発用の主要コンパイラであり、LLVMはC ++(最新リリースではC ++ 11)で記述されています[5]。

LLVMの相対的な「若さ」は欠陥ではなく、重大なバグが発生しないほど十分に成熟しているだけでなく、GCCのような時代遅れのアーキテクチャソリューションの大きな負担も負いません。 コンパイラのモジュール構造により、LLCC(LLVMバックエンド)によってターゲットプラットフォームコードの生成が実行される一方で、LLCC-GCCフロントエンドを使用してGCC標準を完全にサポートできます。 オリジナルのLLVMフロントエンドであるClangを使用することもできます。
LLVMは十分に文書化されており、多くのコード例があります。
モジュラーコンパイラアーキテクチャ
LLVMコンパイラインフラストラクチャはさまざまなツールで構成されていますが、これらすべてをこの記事のフレームワーク内で考慮することは意味がありません。 コンパイラ自体を構成するメインツールに限定します。
LLVMコンパイラは、他のいくつかのコンパイラと同様に、フロントエンド、オプティマイザー(ミドルランド)、およびバックエンドで構成されています。 この構造により、新しいプログラミング言語用のコンパイラーの開発、最適化メソッドの開発、および特定のプロセッサー用のコードジェネレーターの開発を分離できます(このようなコンパイラーは「リターゲット可能」、「リターゲット可能」と呼ばれます)。
それらの間のリンクは、「仮想マシン」のアセンブラーである中間言語LLVMです。 フロントエンド(Clangなど)は、高レベル言語のプログラムのテキストを中間言語のテキストに変換し、オプティマイザー(opt)はさまざまな最適化を実行し、バックエンド(llc)はターゲットプロセッサのコードを生成します(アセンブラーで、またはバイナリファイルとして直接)。 さらに、プログラムの実行中にコンパイルが直接行われる場合、LLVMはJIT(ジャストインタイム)コンパイルモードで動作できます。
プログラムの中間表現は、LLVMアセンブラー言語のテキストファイルの形式、またはバイナリ形式の「ビットコード」形式のいずれかです。 デフォルトでは、clangはビットコード(.bcファイル)を生成しますが、LLVMのデバッグと学習のために、LLVMアセンブラーでテキスト中間表現を生成する必要があります(中間表現、中間表現という言葉からIRコードとも呼ばれます)。
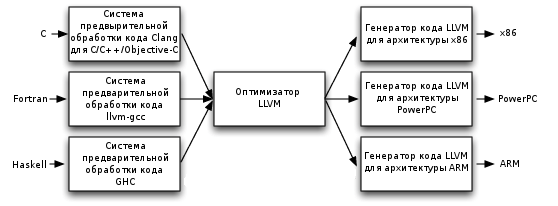
図 1.コンパイラのモジュールアーキテクチャ
上記のプログラムに加えて、LLVMには他のユーティリティが含まれています[6]。
それでは、Cで最も単純なプログラムを書きましょう。
int foo(int x, int y) { return x + y; }
そしてそれをコンパイルします:
clang-3.5 -c add.c -O0 --target=xcore -emit-llvm -S -o add_o0.ll
いくつかの説明:
-c add.c-入力ファイル。
-O0-最適化レベル0、最適化なし。
--target = xcore-xcoreプロセッサのコアは、IRコードにコンパイルするときに複雑な機能を持たないため、研究に理想的なオブジェクトです。 このカーネルの容量は32で、clangはすべての変数を32ビットワードの境界に合わせます。
-emit-llvm -S-(アセンブラーLLVMで)テキスト形式でllvmファイルを生成するようにclangに指示します。
-o add_o0.ll-出力ファイル
結果を見てみましょう:
; ModuleID = 'add.c'
target datalayout = "em:ep:32:32-i1:8:32-i8:8:32-i16:16:32-i64:32-f64:32-a:0:32-n32"
target triple = "xcore"
; Function Attrs: nounwind
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 %x, i32* %1, align 4
store i32 %y, i32* %2, align 4
%3 = load i32* %1, align 4
%4 = load i32* %2, align 4
%5 = add nsw i32 %3, %4
ret i32 %5
}
attributes #0 = { nounwind "less-precise-fpmad"="false" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.ident = !{!0}
!xcore.typestrings = !{!1}
!0 = metadata !{metadata !"Ubuntu clang version 3.5.0-4ubuntu2~trusty2 (tags/RELEASE_350/final) (based on LLVM 3.5.0)"}
!1 = metadata !{i32 (i32, i32)* @foo, metadata !"f{si}(si,si)"}
かなり複雑に見えますよね? ただし、ここに何が書かれているかを理解しましょう。 だから:
ターゲットdatalayout = "em:ep:32:32-i1:8:32-i8:8:32-i16:16:32-i64:32-f64:32-a:0:32-n32"
変数のビット深度とアーキテクチャの最も基本的な機能の説明。 e-リトルエンディアンアーキテクチャ。 ビッグエンディアンの場合、E:m:e-マングリング、命名規則になります。 まだ必要ありません。 p:32:32-ポインターは32ビットで、32ビットワードの境界に配置されます。 i1:8:32-ブール変数(i1)は8ビット値で表現され、32ビットワードの境界に整列されます。 さらに、整数変数i8-i64(それぞれ8〜64ビット)、および倍精度の実変数のf64でも同様です。 a:0:32-集約変数(つまり、配列と構造体)は32ビットのアライメントを持ちます。n32-プロセッサALUによって処理される数値のビット深度(ネイティブ整数幅)。
ターゲット(ターゲットプロセッサ)の名前は次のとおりです:target triple =“ xcore”。 IRコードはしばしば「マシンに依存しない」と呼ばれますが、実際にはそうではありません。 ターゲットアーキテクチャのいくつかの機能を反映しています。 これが、バックエンドだけでなくフロントエンドにもターゲットアーキテクチャを指定する必要がある理由の1つです。
fooの機能コードは次のとおりです。
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 %x, i32* %1, align 4
store i32 %y, i32* %2, align 4
%3 = load i32* %1, align 4
%4 = load i32* %2, align 4
%5 = add nsw i32 %3, %4
ret i32 %5
}
元の関数は非常に単純ですが、コードはかなり面倒です。 これが彼の仕事です。
LLVM内のすべての変数名には、%(ローカル変数の場合)または@のグローバルの接頭辞が付いていることに注意してください。 この例では、すべての変数はローカルです。
%1 = alloca i32、align 4-スタック上の変数に4バイトを割り当てます。この領域へのポインターはポインター%1です。
store i32%x、i32 *%1、align 4-関数の引数の1つ(%x)を選択した領域にコピーします。
%3 = i32 *%1、load 4をロード-変数の値を取得します%3。 %3は、%xのローカルコピーを保存するようになりました。
%y引数についても同じことを行います
%5 = nsw i32%3、%4を追加-%xと%yのローカルコピーを追加し、結果を%5に入れます。 nsw属性もありますが、まだ重要ではありません。
値%5を返します。
上記の例からわかるように、最適化レベル0では、clangはソースコードに文字通り従うコードを生成し、すべての引数のローカルコピーを作成し、冗長なコマンドを削除しようとしません。 これは悪いコンパイラプロパティのように思えるかもしれませんが、プログラムをデバッグするとき、およびコンパイラ自体のコードをデバッグするとき、実際には非常に便利な機能です。
最適化レベルをO1に変更するとどうなるか見てみましょう。
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = add nsw i32 %y, %x
ret i32 %1
}
余分なチームは1つも残っていません。 これで、プログラムは関数の引数を直接追加し、結果を返します。
より高いレベルの最適化がありますが、この特定のケースでは、より良い結果は得られません。 最適化の最大レベルはすでに達成されています。
LLVMコードの残りの部分(属性、メタデータ)は、サービス情報をそれ自体に伝えますが、これは今のところ興味深いものではありません。
LLVMコード構造
LLVMコード構造は非常に単純です。 プログラムコードはモジュールで構成され、コンパイラは一度に1つのモジュールを処理します。 モジュールには、グローバル宣言(変数、定数、および他のモジュールにある関数ヘッダーの宣言)と関数があります。 関数には引数と戻り値の型があります。 関数はベースブロックで構成されます。 ベースユニットは、1つのエントリポイントと1つの出口ポイントを持つLLVMアセンブラー命令シーケンスです。 ベースブロックには分岐とループは含まれず、最初から最後まで厳密に連続して実行され、終了コマンド(関数から戻るか別のブロックに切り替える)で終了する必要があります。
最後に、ベースユニットはアセンブラコマンドで構成されます。 コマンドのリストは、LLVMのドキュメント[7]に記載されています。
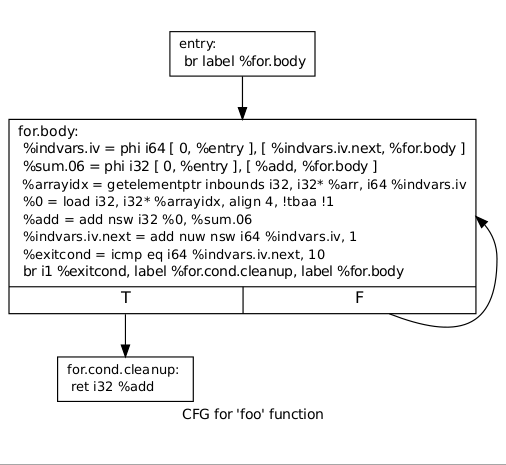
そのため、ベースユニットにはラベルでマークされたエントリポイントが1つあり、必ず無条件のジャンプコマンドbrまたはリターンコマンドretで終了する必要があります。 それらの前に条件分岐コマンドがある場合があります。その場合、終了コマンドの直前でなければなりません。 ベースユニットには、前任者のリスト(制御を取得できるベースユニット)と後続のリスト(制御を転送できるベースユニット)があります。 この情報に基づいて、CFGが構築されます-制御フローグラフ、制御フローグラフ、コンパイラでプログラムを表す最も重要な構造。
Cのテスト例を考えてみましょう。
言語Cのソースコードにサイクルを持たせます。
// 10 int for_loop(int x[]) { int sum = 0; for(int i = 0; i < 10; ++i) { sum += x[i]; } return sum; }
CFGの形式は次のとおりです。
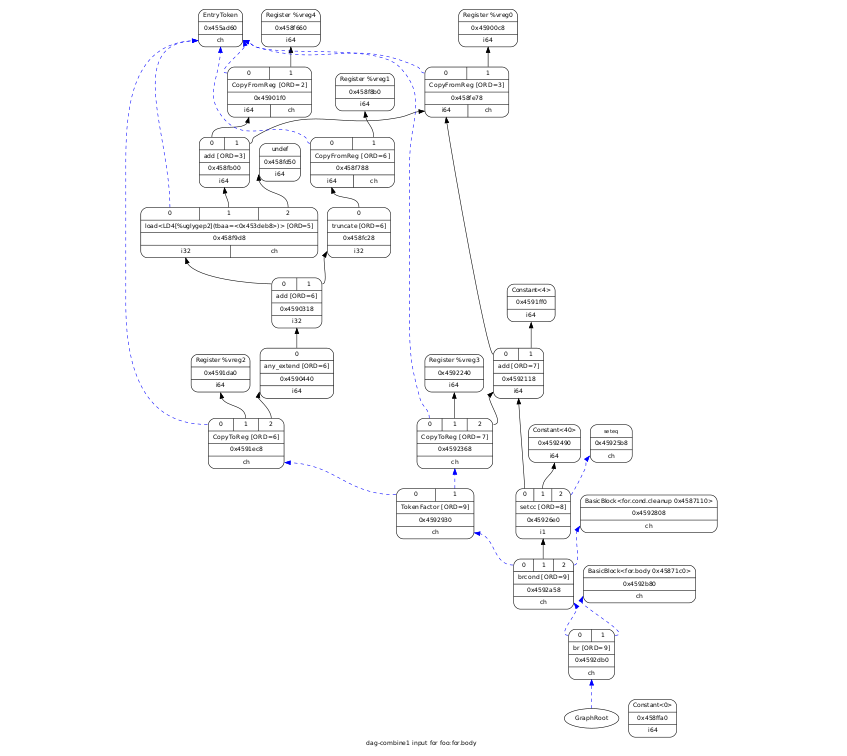
LLVMの別のタイプのグラフは、DAG-有向非巡回グラフ、基本単位である有向非巡回グラフです。
アセンブラーコマンドとそれらの間の依存関係を表します。 次の図は、ベースユニットのDAGを示しています。これは、上記の例のループの本体を表し、最適化レベルは-O1です。
SSAフォーム
高水準言語と区別するIRコードの主要な機能は、いわゆるSSA形式(静的単一割り当て形式)で表示されることです。 この機能は、LLVMプラットフォームでコンパイラーを開発する際に理解するために非常に重要であるため、注意を払います。 要するに、SSA形式では、各変数にはプログラムの1つのポイントでのみ1回だけ値が割り当てられます。 IRコードの最適化および変換アルゴリズムはすべて、このフォームでのみ機能します。
しかし、通常の高級言語プログラムをこの形式に変換する方法は? 実際、通常のプログラミング言語では、変数の値は、プログラムのさまざまな場所、またはループなどで複数回割り当てることができます。
このプログラムの動作を実装するには、2つの方法のいずれかを使用します。 最初のトリックは、上記のコードのように、ロード/ストアコマンドのペアを使用することです。 唯一の割り当て制限は、LLVM名前付き変数にのみ適用され、ポインターによって参照されるメモリの場所には適用されません。 つまり、storeコマンドを使用してメモリセルに無制限の回数書き込むことができ、このセルへのポインタは変更されないため、正式なSSAルールが遵守されます。 このメソッドは通常、-O0の最適化レベルで使用されます。詳細については説明しません。 2番目のトリックでは、IRコードのもう1つの興味深い概念であるφ関数を使用します。
SSAコード:ロード/ストア
前のセクションのテストケースを使用します。
最適化レベル-O0でコンパイルします。
define i32 @for_loop(i32* %x) #0 {
%1 = alloca i32*, align 4
%sum = alloca i32, align 4
%i = alloca i32, align 4
store i32* %x, i32** %1, align 4
store i32 0, i32* %sum, align 4
store i32 0, i32* %i, align 4
br label %2
; :2 ; preds = %12, %0
%3 = load i32* %i, align 4
%4 = icmp slt i32 %3, 10
br i1 %4, label %5, label %15
; :5 ; preds = %2
%6 = load i32* %i, align 4
%7 = load i32** %1, align 4
%8 = getelementptr inbounds i32* %7, i32 %6
%9 = load i32* %8, align 4
%10 = load i32* %sum, align 4
%11 = add nsw i32 %10, %9
store i32 %11, i32* %sum, align 4
br label %12
; :12 ; preds = %5
%13 = load i32* %i, align 4
%14 = add nsw i32 %13, 1
store i32 %14, i32* %i, align 4
br label %2
; :15 ; preds = %2
%16 = load i32* %sum, align 4
ret i32 %16
}
ここで、上記の内容がわかります。ループ変数は、%iポインターによって参照される単なるメモリセルです。
SSAコード:φ関数
O1最適化レベルを試してみましょう。
define i32 @for_loop(i32* nocapture readonly %x) #0 {
br label %1
; :1 ; preds = %1, %0
%i.02 = phi i32 [ 0, %0 ], [ %5, %1 ]
%sum.01 = phi i32 [ 0, %0 ], [ %4, %1 ]
%2 = getelementptr inbounds i32* %x, i32 %i.02
%3 = load i32* %2, align 4, !tbaa !2
%4 = add nsw i32 %3, %sum.01
%5 = add nsw i32 %i.02, 1
%exitcond = icmp eq i32 %5, 10
br i1 %exitcond, label %6, label %1
; :6 ; preds = %1
ret i32 %4
}
ここで、ループ変数は%i.02(LLVMの変数名にはピリオドを含めることができます)であり、これはポインターではなく通常の32ビット変数であり、値はphi i32関数[0、%0]を使用して割り当てられます。 [%5、%1]。 これは、ベースブロック%0(関数の最初のベースブロック)から遷移が発生した場合、関数は値0を取り、ベースブロック%1(同じベースの出力ポイントから遷移が発生した場合、変数%5の値ブロック)。 したがって、IRコードジェネレーターは、厳密に正式なSSAルールに従って、2つの変数の割り当てを取り除きました。 さらに、同様の方法でvariable%sum.01への割り当てが発生することがわかります。
そのため、φ関数の意味は、その値がどの基本単位から遷移したかに依存するということです。 φ関数は、ベースユニットの先頭でのみ見つけることができます。 複数ある場合は、ベースユニットの最初の命令から連続して実行する必要があります。
モア最適化!
最適化レベル-O2ではどうなりますか?
define i32 @for_loop(i32* nocapture readonly %x) #0 {
%1 = load i32* %x, align 4, !tbaa !2
%2 = getelementptr inbounds i32* %x, i32 1
%3 = load i32* %2, align 4, !tbaa !2
%4 = add nsw i32 %3, %1
%5 = getelementptr inbounds i32* %x, i32 2
%6 = load i32* %5, align 4, !tbaa !2
%7 = add nsw i32 %6, %4
%8 = getelementptr inbounds i32* %x, i32 3
%9 = load i32* %8, align 4, !tbaa !2
%10 = add nsw i32 %9, %7
%11 = getelementptr inbounds i32* %x, i32 4
%12 = load i32* %11, align 4, !tbaa !2
%13 = add nsw i32 %12, %10
%14 = getelementptr inbounds i32* %x, i32 5
%15 = load i32* %14, align 4, !tbaa !2
%16 = add nsw i32 %15, %13
%17 = getelementptr inbounds i32* %x, i32 6
%18 = load i32* %17, align 4, !tbaa !2
%19 = add nsw i32 %18, %16
%20 = getelementptr inbounds i32* %x, i32 7
%21 = load i32* %20, align 4, !tbaa !2
%22 = add nsw i32 %21, %19
%23 = getelementptr inbounds i32* %x, i32 8
%24 = load i32* %23, align 4, !tbaa !2
%25 = add nsw i32 %24, %22
%26 = getelementptr inbounds i32* %x, i32 9
%27 = load i32* %26, align 4, !tbaa !2
%28 = add nsw i32 %27, %25
ret i32 %28
}
オプティマイザーはループを開始しました。 一般に、LLVM IRコードオプティマイザーは非常にインテリジェントです。ループを展開するだけでなく、コードに明示的に存在しない場合でも、重要な構成を単純化し、定数値を計算し、他の複雑なコード変換を実行できます。
IRコードのレイアウト
実際のプログラムは1つのモジュールで構成されていません。 従来のコンパイラは、モジュールを個別にコンパイルし、オブジェクトファイルに変換してからリンカー(リンカー)に渡します。リンカーはこれらを1つの実行可能ファイルに結合します。 LLVMでもこれを行うことができます。
ただし、LLVMにはIRコードを作成する機能もあります。 これを検討する最も簡単な方法は、例を使用することです。 foo.cとbar.cの2つのソースモジュールがあるとします。
//bar.h #ifndef BAR_H #define BAR_H int bar(int x, int k); #endif //bar.c int bar(int x, int k) { return x * x * k; } //foo.c #include "bar.h" int foo(int x, int y) { return bar(x, 2) + bar(y, 3); }
プログラムが「従来の」方法でコンパイルされている場合、オプティマイザーはほとんど何もできません。foo.cをコンパイルするとき、コンパイラーはbar関数内に何があるかを知らず、bar()呼び出しを挿入する唯一の明白な方法を実行できます。
しかし、IRコードを作成すると、1つのモジュールが得られます。-O2レベルで最適化すると、次のようになります(わかりやすくするために、モジュールヘッダーとメタデータは省略されます)。
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = shl i32 %x, 1
%2 = mul i32 %1, %x
%3 = mul i32 %y, 3
%4 = mul i32 %3, %y
%5 = add nsw i32 %4, %2
ret i32 %5
}
; Function Attrs: nounwind readnone
define i32 @bar(i32 %x, i32 %k) #0 {
%1 = mul nsw i32 %x, %x
%2 = mul nsw i32 %1, %k
ret i32 %2
}
foo関数で呼び出しが行われず、コンパイラーがbar()の内容を完全に転送して、途中でkの定数値を置き換えていることがわかります。 bar()関数はモジュール内に残りますが、プログラム内の他の場所で呼び出されない限り、実行可能ファイルのコンパイル時に除外されます。
GCCには、中間コードをリンクおよび最適化する機能(LTO、リンク時最適化)もあることに注意してください[6]。
もちろん、LLVMでの最適化はIRコードの最適化に限定されません。 バックエンド内部では、IRコードをマシン表現に変換するさまざまな段階でさまざまな最適化も行われます。 LLVMはこれらの最適化の一部を独自に実行しますが、バックエンド開発者は、プロセッサアーキテクチャの機能を完全に使用できるようにする独自の最適化アルゴリズムを開発できます(また、開発する必要があります)。
ターゲットプラットフォームのコード生成
元のプロセッサアーキテクチャ用のコンパイラの開発。これは主にバックエンドの開発です。 原則として、フロントエンドアルゴリズムへの介入は不要です。いずれにしても、非常に正当な理由が必要です。 Clangのソースコードを分析すると、ほとんどの「特別な」アルゴリズムが、非標準形式の実数を持つx86およびPowerPCプロセッサに当てはまることがわかります。 他のほとんどのプロセッサでは、基本型のサイズとエンディアン(ビッグエンディアンまたはリトルエンディアン)のみを指定する必要があります。 ほとんどの場合、サポートされている多くのプロセッサの中から(ビット深度に関して)同様のプロセッサを簡単に見つけることができます。
ターゲットプラットフォームのコード生成は、LLVM、LLCバックエンドで行われます。 LLCは多くの異なるプロセッサをサポートしており、それに基づいて独自のオリジナルプロセッサ用のコードジェネレータを作成できます。 また、このタスクは、サポートされている各アーキテクチャのモジュールを含むすべてのソースコードが完全にオープンであり、調査に利用できるため、簡素化されています。
ターゲットプラットフォーム(ターゲット)のコードジェネレーターは、LLVMインフラストラクチャに基づいてコンパイラーを開発するときに最も時間のかかるタスクです。 ターゲットプロセッサのアーキテクチャに大きく依存しているため、ここではバックエンド実装の機能にこだわらないことにしました。 ただし、尊敬されるHabrの視聴者がこのトピックに興味を持っている場合は、次の記事でバックエンドを開発する際の重要なポイントを説明する準備ができています。
おわりに
短い記事では、LLVMアーキテクチャ、LLVM IR構文、バックエンド開発プロセスのいずれについても詳細に検討することはできません。 ただし、これらの問題についてはドキュメントで詳しく説明しています。 著者はむしろLLVMコンパイラインフラストラクチャの一般的なアイデアを与えようとしました。このプラットフォームは、モダンで強力で、普遍的であり、入力言語またはターゲットプロセッサアーキテクチャから独立しているため、開発者の要求に応じて両方を実装できます。
レビュー済みのものに加えて、LLVMには他のユーティリティも含まれていますが、それらの考慮事項は記事の範囲を超えています。
LLVMを使用すると、パイプラインアーキテクチャを含むあらゆるアーキテクチャ(注を参照)にバックエンドを実装できます。コマンドの並外れた実行、さまざまな並列化オプション、VLIW、クラシックアーキテクチャおよびスタックアーキテクチャ、一般に任意のオプション。
非標準ソリューションがプロセッサアーキテクチャの中心にあるかどうかに関係なく、多かれ少なかれコードを記述するだけです。
メモ
理由の範囲内の誰でも。 次のように、4ビットアーキテクチャ用のC言語コンパイラを実装することはほとんど不可能です。 言語標準では、少なくとも8のビット深度が明示的に必要です。
文学

コンパイラー
[1] ドラゴンブック
[2] Wirth N.ビルドコンパイラ
Gcc
[3] gcc.gnu.org -GCCプロジェクトサイト
[4]リチャードM.ストールマンとGCC開発者コミュニティ。 GNUコンパイラコレクションの内部
LLVM
[5] http://llvm.org/-LLVMプロジェクトサイト
[6] http://llvm.org/docs/GettingStarted.html LLVMシステム入門
[7] http://llvm.org/docs/LangRef.html LLVM言語リファレンスマニュアル
[8] http://llvm.org/docs/WritingAnLLVMBackend.html LLVMバックエンドの作成
[9] http://llvm.org/docs/WritingAnLLVMPass.html LLVMパスの作成
[10] Chen Chung-Shu。 Cpu0アーキテクチャ用のLLVMバックエンドの作成
[11] Mayur Pandey、Suyog Sarda。 LLVMクックブック
[12]ブルーノ・カルドーゾ・ロペス。 LLVMコアライブラリ入門
[13] Suyog Sarda、マユールパンディ。 LLVM Essentials
著者は、コメントとPMであなたの質問に喜んで答えます。
PMで通知されたすべてのタイプミスについて通知する要求。 事前に感謝します。