バージョン管理とは
バージョン管理は、DDL(データ定義言語)クエリに対してのみ使用します。 データ自体には興味がありません。 なんで? 2つの極端なケースを検討します。
- わずかなデータ(たとえば、50メガバイト未満)。 この場合、データベースの完全なダンプを定期的に実行し、それをリポジトリに安全に配置できます。
- 大量のデータ(1ギガバイト以上)。 この場合、バージョン管理はあまり役に立ちませんが、とにかく、それを整理することは非常に問題になります。 この場合、バックアップとアーカイブログで標準スキームを使用することをお勧めします。これにより、いつでもデータベースの統合バージョンを取得できます。
DDLをバージョン管理する必要があるのはなぜですか?
複雑なデータベースを操作する場合、奇妙なことに、テーブルはあまり面白くありません(ただし、バージョン管理も必要です)。 トリガー、ビュー、パッケージおよびプロシージャ、および同様のオブジェクトに含まれるビジネスロジックを扱うのははるかに困難です。 たとえば、私が使用したデータベースの1つに、最大1.5メガバイトのサイズのパケットがありました。 これらのパッケージには常に変更が加えられており、誰が変更を行ったか、いつ理由を知りたいのか、どのように変更を希望する状態に戻すのかを知ることが非常に重要です。
完璧な世界
プロジェクトが完了するまで変わらない明確なTKがある理想的な世界を想像してください。 リリース後、私たちは何をしたかを忘れ、美しい目のために定期的な給料をもらいます。 すべてのニュアンスを考慮に入れて、すぐに記述した理想的なコード。エラーなしで機能し、メンテナンスの必要はありません。 改善の欠如、緊急のバグ修正、統合メカニズム、テストベースとテストサンプルで作業する能力、すべてが完璧であると言うユビキタスユニットテストの存在。
この場合、データベースの状態に関する情報の主要なソースとしてバージョン管理システムを使用し、そこからデータベースへの変更を展開するだけで十分です。 単一のリポジトリがあり、基本コードの共同作業があります-すべてが美しく透明です。 この機能を非常にうまく実装しているように見える製品がいくつかあります。
実世界
このパートの概要 
目を開けて見回してください。 ほとんどの場合、プロジェクトはスキームに従って実装されます。このスキームはUHV(作成、ロールアウト、廃棄)と呼ばれます。 完了したプロジェクトの大部分は売却できず、将来の見通しなしに閉鎖されています。 残りの幸運なものは何百回も繰り返されますが、その後は元のTKから名前が良くなります。 この現実では、製品の速度、要件、および品質については主に心配していません。 明らかな理由に加えて、プロジェクトの予算の最大の部分はそれに依存しているため、開発時間の作業コストがかかるため、開発の速度が心配です。
はい、それは間違っています。 世界は残酷で、不公平で、ダイナミックであり、品質が低下したとしても、即座に反応する必要があります。 すべての開発者は理想的なコードを目指して努力しますが、ほとんどは悪魔との取引条件を受け入れ、品質と速度の許容可能な妥協を求めます。 私たちは最善を尽くしますが、半年の期間と理想的な製品の代わりに、2週間で不安定で時にはdecisionい決定を下した場合は、赤面しないことを学びます。 さらに、ある時点で「最後のバグ」は決して見つからないという理解に至り、ある時点でそれを探すのをやめて、リリースするだけです。 ソリューションを理想に近づけることは、最も単純なアプリケーションとコンソールスクリプトの運命です。それでも、重要な点を考慮に入れていないことがよくあります。 大規模なプロジェクトについて話すとき、Oracle、Microsoft、Appleの例は、完璧なコードがないことを示しています。 例として、DBAの古典的な答えは、Oracle Databaseの新しいリリースでは「古いバグの30%を削除し、新しいバグの40%を追加しました」という質問に対するものです。
誰が責任を負い、何をすべきか?
データベースについて話すとどういう意味ですか? これは通常そうです:
- 多数の開発者がデータベースにアクセスできます
- 多くの場合、1つまたは別のオブジェクトをロールバックする必要があります
- オブジェクトを壊したのは彼だと誰も認めない
- 変更はしばしば理解不能です
さらに、開発者がDBAにアクセスして、オブジェクトの以前のバージョンを返すように要求した場合、DBAは次の3つのケースでこれを行うことができます(例としてOracleを使用)。
- 以前のバージョンがまだUNDOに保存されている場合
- オブジェクトが単に削除され、ごみ箱に保存された場合(RECYCLEBIN)
- 必要な日にデータベースの完全バックアップを展開できる場合
最も現実的なオプションは3番目です。 しかし、どの日付に復元を実行する必要があるかがわからないことが多いという事実によって複雑になり、たとえば10テラバイトのベースを復元することは、かなり長く、リソースを大量に消費する操作です。 したがって、通常、DBAは肩をすくめ、開発者はコーヒーに顔をしかめ、オブジェクトをゼロから書き始めます。
開発者の生活を楽にするために何ができますか? 唯一のオプションがあります-すでに完了した変更の事実に基づいてデータベースをバージョン管理するため。 当然、これは起こりうるエラーを防ぐ機会を与えませんが、大部分の場合、目的のオブジェクトとシステム全体を生き返らせる方法を提供します。
Oracleの実装
最初の単純な「額」ソリューションは、ベース全体を定期的にアンロードすることです。 ただし、データベースのアンロードには長い時間がかかり、誰が、いつ、何が変わったのかわかりません。 したがって、明らかにもっと複雑なものが必要です。 つまり、変更されたDDLオブジェクトのみをアンロードする必要があります。 これを行うには、監査を使用するか、システムトリガーを作成するという2つのアプローチを使用できます。 2番目の方法を使用しました。 次に、シーケンスは次のとおりです。
- DDLリクエストのデータが保存されるテーブルを作成します
- このテーブルに書き込むシステムトリガーを作成する
さらに、アクションごとに、リクエストの全文、スキーム、オブジェクトの名前とタイプ、ユーザーのIPアドレス、ユーザーのマシンのネットワーク名、ユーザー名、タイプ、変更日など、非常に詳細な情報を取得できます。 原則として、これは開発者を見つけてメダルを与えるのに十分です。
次に、オブジェクトの異なるバージョンを比較できるようにするために、データベースの構造が直感的な方法で表示されるリポジトリが必要です。 これを行うには、データベースを変更するたびに、変更されたオブジェクトをアンロードしてデータベースにコミットする必要があります。 複雑なことはありません! Gitリポジトリを作成し、最初にそこで完全なアップロードを行ってから、変更テーブルを監視するサービスを作成し、新しいレコードが表示される場合、変更されたオブジェクトをアンロードします。
それはどのように見えますか
通常の比較 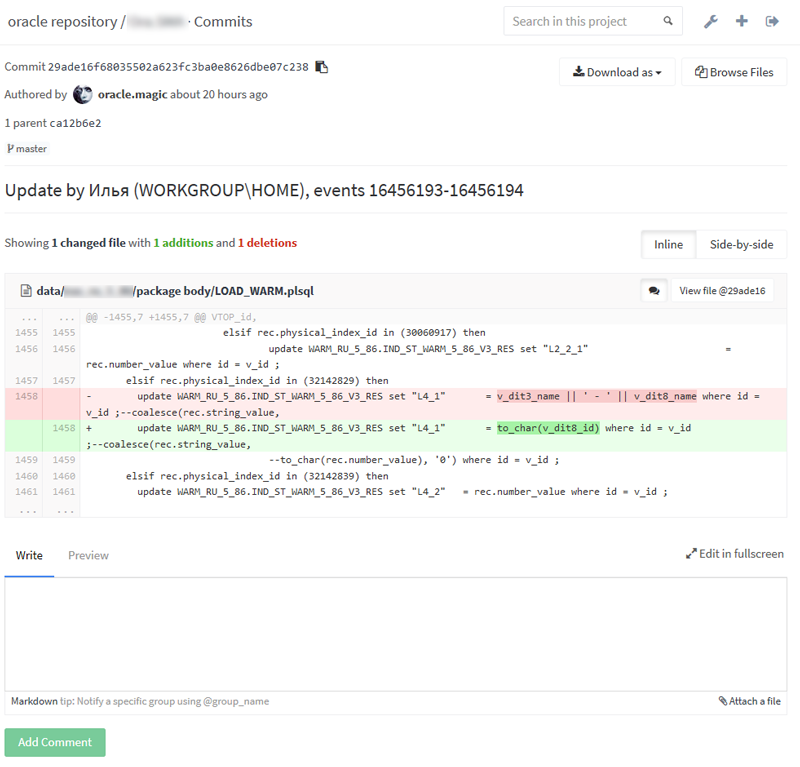
並べて比較
スキーマ内のオブジェクトのリスト
特定のオブジェクトの変更履歴
GitHubでも同じこと
つまり、データベース内の変更のソースを見つけて、必要に応じてロールバックできる作業ツールがあります。 私の場合、Gitlabの最大のGitリポジトリ(別のマシン上の独自のインスタンス)は数百メガバイトかかり、約10万件のコミットがあり、非常に高速に動作します。 Gitlabに移行する前は、同じリポジトリがgithubで、そしてbitbucketで正常に動作していました。
その後、私たちが持っているオブジェクトに関するデータ:
- テーブル
- 提出
- マテリアライズドビュー
- 引き金
- シーケンス
- ユーザー(古いパスワードを復元するために使用できるパスワードハッシュを使用)
- パッケージ、関数、手順
- データベースリンク(パスワードハッシュも使用)
- 助成金
- 条件付きの定数
- 同義語
古いデータベースを更新するタスクのためにプログラムを変更することもできます-古いバージョンをアンロードし、その上にある新しいバージョンをアンロードし、半自動モードの違いを修正します。
短所
- 一部の変更はすぐに発生する可能性があり、サービスには中間結果をアンロードする時間がありませんが、それらが関連する可能性は低いため、変更の表でそれらを見つけることができます。
- スキームやDROP CASCADEの削除など、一部の変更は一度に複数のオブジェクトに影響を与える可能性がありますが、必要に応じて適切に解決することもできます。唯一の問題は実装です。
- パスワードハッシュはリポジトリに格納されるため、開発者に直接発行することはできません。
推奨事項として、アップロードアルゴリズムのロジックでカバーできない変更があった場合は、リポジトリにあるものの上に現在のバージョンを定期的にアンロードすることをお勧めします。
PHPのアルゴリズムとインストールガイドへのリンクは記事の最後にありますが、参照用としてのみ使用することを心からお勧めします。 唯一のプラスは、奇妙なことに、動作することです。
おわりに
このようなワークフローで作業する必要がないことを心から願っています。 そして、もしあなたの世界がまだ理想からかけ離れているなら、この出版物があなたを助けることを願っています。
データベースをバージョン管理していますか? 正しい方法で、または実際に? MySQL、Postgresなど、他のDBMSの実装があるのでしょうか? または、私が見落としていた根本的に異なる良いアプローチがありますか?
参照資料
- stackoverflowに基づいてバージョンを作成する方法に関する素晴らしい議論
- Liquibaseから適切なアプローチを実装する
- 私の古い Java + SVN 実装に似ています
- インストール手順が記載されたツールのWebサイト
- githubのツールコードのリポジトリ
- ここで私を雇うことができます