利用可能な紙の本を比較します。 店舗が異なれば、書籍の数も大きく異なります。 1000冊未満、または20万冊を超える書籍。
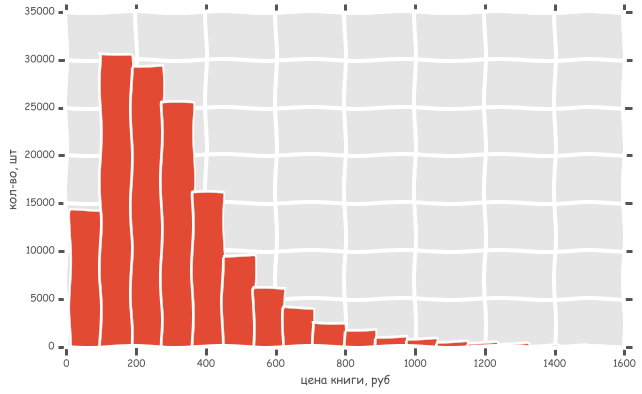
ところで、ヒストグラムは本物です。 どのように構築されているか、その他の興味深いパターンはカットの下にあります。
まず、すべての店舗にある書籍のリストを見つける必要があります。
bookradar.orgからデータベースをcsvファイルとしてアップロードしました。 もちろん、単にアンロードするのではなく、特別な方法でPythonを使用して処理したため、分析に便利です。 私たちが持っている列はお店、行は本、行のセルは特定の店でのこの本の価格です。 ストアに本がない場合、空の値(NaN)。
ISBN付きの紙の本のみがアップロードされます。 ISBNが指定されていない書籍では、これが同じ書籍であることを理解する方法はありません。 同じと呼ばれ、同じように見える本でさえ、たとえば異なる年の出版物である場合、価格が異なる場合があります。 したがって、分析を簡素化するために、簡単に比較できる書籍のみを使用します。
私が最初にグラフィックを描いたとき、スケールはまったく読めませんでした。 30から5万ルーブルの費用がかかる個別のインスタンスがあります。 したがって、アンロードするときに、1,500ルーブルを超える本を削除しました。
分析するストアの選択
必要なインポートを行い、ファイルをDataFrameにロードします。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from IPython.display import HTML plt.style.use('ggplot') %matplotlib inline filename = 'books.csv' data = pd.read_csv(filename, header=0, na_values=None, low_memory=False) data.head()
これは、DataFrameの最初の数行です。
| isbn | dmkpress.com | rufanbook.ru | read.ru | setbook.ru | moymir.ru | boffo.ru | my-shop.ru | ... | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 9785994911389 | ナン | ナン | 69 | 100 | ナン | ナン | ナン | ... |
| 2 | 9789855497791 | ナン | ナン | ナン | 310 | ナン | ナン | 403 | ... |
| 3 | 9785942802943 | ナン | ナン | ナン | ナン | ナン | ナン | ナン | ... |
| 4 | 9785779717533 | ナン | ナン | 177 | 160 | ナン | ナン | 177 | ... |
各店舗の本の数を数えましょう:
desc = data.describe() l = [] for colname in desc: count = desc[colname][0] l.append((count, colname)) for t in sorted(l, reverse=True): print("{:16} {}".format(t[1], int(t[0])))
蔵書数 ozon.ru 220962 setbook.ru 208039 my-shop.ru 203200 books.ru 181817 book-stock.ru 124308 bookvoed.ru 117494 labirint.ru 114803 read.ru 93720 spbdk.ru 43714 chaconne.ru 42993 biblion.ru 41898 eksmo.ru 40582 knigosvet.com 34645 rufanbook.ru 6071 combook.ru 4716 bookmail.ru 2356 boffo.ru 2341 moymir.ru 740 dmkpress.com 722
とても小さなお店を連れて行くのは意味がありません 重複する本はほとんどないか、まったくありません。 約10万冊またはそれ以下の本からお店を選ぶ
# stores = ['books.ru', 'labirint.ru', 'ozon.ru', 'my-shop.ru', 'read.ru', 'bookvoed.ru', 'book-stock.ru', 'setbook.ru'] data = data[stores] # . # .. , . data = data.dropna(axis=0) # , data.describe()
テーブルに関する要約情報を取得しました:
| books.ru | labirint.ru | ozon.ru | my-shop.ru | read.ru | bookvoed.ru | book-stock.ru | setbook.ru | |
|---|---|---|---|---|---|---|---|---|
| 数える | 17834.000000 | 17834.000000 | 17834.000000 | 17834.000000 | 17834.000000 | 17834.000000 | 17834.000000 | 17834.000000 |
| 意地悪 | 340.154312 | 343.349333 | 308.639677 | 294.602108 | 309.796400 | 315.771504 | 291.266794 | 286.433722 |
| 標準 | 189.347516 | 235.526318 | 209.594445 | 206.383899 | 208.093532 | 208.651959 | 204.553104 | 191.038253 |
| 分 | 40.000000 | 17.000000 | 26.000000 | 14.000000 | 69.000000 | 13.000000 | 14.000000 | 77.000000 |
| 25% | 210.000000 | 169.250000 | 153.000000 | 142.000000 | 155.000000 | 162.000000 | 142.000000 | 140.000000 |
| 50% | 308.000000 | 293.500000 | 264.000000 | 248.000000 | 267.000000 | 271.000000 | 248.000000 | 240.000000 |
| 75% | 429.000000 | 435.000000 | 391.000000 | 380.750000 | 391.000000 | 402.000000 | 373.000000 | 360.000000 |
| 最大 | 1460.000000 | 1497.000000 | 1478.000000 | 1474.000000 | 1485.000000 | 1456.000000 | 1474.000000 | 1490.000000 |
すべての店舗に17834冊の本があります。
いくつかの説明:
- 平均 -平均
- std-標準偏差
- 50%、25%、および75%は、中間、下位、および上位の分位数の中央値です。
これらのデータに基づいて、すでにいくつかの結論を引き出すことが可能です。 中央値を見ると、240のsetbook.ruが最良の価格を提供し、中央値が248のmy-shop.ruとbook-stock.ruに移動します。
価格分布
ヒストグラムを作成して、どの範囲で最も多くの本を見てみましょう。 このヒストグラムは、投稿の冒頭の写真に似ていますが、バーが多いだけです。
plt.figure(figsize=(10, 6)) plt.xlabel(' , ') plt.ylabel('-, ') data3 = data[stores] x = data3.as_matrix().reshape(data3.size) # count, bins, ignored = plt.hist(x, bins=30)
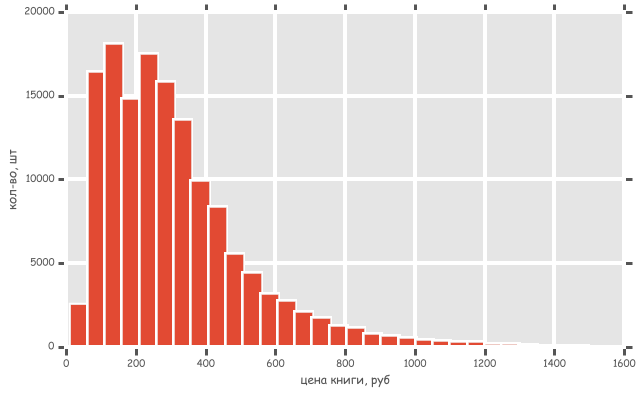
興味深いことに、約75ルーブルと215ルーブルの2つのピークが見つかりました。
そして、前のコードの冒頭に数行追加することで、ゆがんだ外観になりました。
plt.xkcd() # plt.style.use('ggplot') # xkcd, .. xkcd
価格相関
次に、店舗の価格の相関関係を見てみましょう。
data.corr()
| books.ru | labirint.ru | ozon.ru | my-shop.ru | read.ru | bookvoed.ru | book-stock.ru | setbook.ru | |
|---|---|---|---|---|---|---|---|---|
| books.ru | 1.000000 | 0.971108 | 0.969906 | 0.965291 | 0.978453 | 0.970747 | 0.965809 | 0.966226 |
| labirint.ru | 0.971108 | 1.000000 | 0.973731 | 0.968637 | 0.979923 | 0.970600 | 0.969971 | 0.965970 |
| ozon.ru | 0.969906 | 0.973731 | 1.000000 | 0.973783 | 0.979620 | 0.967151 | 0.974792 | 0.971946 |
| my-shop.ru | 0.965291 | 0.968637 | 0.973783 | 1.000000 | 0.976491 | 0.956980 | 0.996946 | 0.970588 |
| read.ru | 0.978453 | 0.979923 | 0.979620 | 0.976491 | 1.000000 | 0.974892 | 0.976164 | 0.974129 |
| bookvoed.ru | 0.970747 | 0.970600 | 0.967151 | 0.956980 | 0.974892 | 1.000000 | 0.958787 | 0.961217 |
| book-stock.ru | 0.965809 | 0.969971 | 0.974792 | 0.996946 | 0.976164 | 0.958787 | 1.000000 | 0.972701 |
| setbook.ru | 0.966226 | 0.965970 | 0.971946 | 0.970588 | 0.974129 | 0.961217 | 0.972701 | 1.000000 |
すべての店舗の価格には良好な相関関係が見られます。 そして、my-shop.ruとbook-stock.ruをいくつか見ると、相関関係はすでに0.996946です。 価格はほぼ同じです。
各店舗の書籍の価格分布のヒストグラムと、店舗の各ペアの散布図を作成します。
from pandas.tools.plotting import scatter_matrix scatter_matrix(data, alpha=0.05, figsize=(14, 14));

散布図から、相関表と同じ図が再び表示されます。 明らかに相関関係があり、はっきりと見えます。 明確にするために、いくつかの店舗を増やしましょう。
scatter_matrix(data[['ozon.ru', 'labirint.ru']], alpha=0.05, figsize=(14, 14));

次に、非常に類似した価格の店舗を見てみましょう。
scatter_matrix(data[['my-shop.ru', 'book-stock.ru']], alpha=0.05, figsize=(14, 14));

結果はほぼ完璧なストレートでした。 しかし、まだそれの外側にあるポイントがあります、すなわち 100%の価格が同じではありません。
すべての価格でスケジュール
テーブルをグラフ化してみましょう。
plt.figure(figsize=(14, 6)) # x = list(range(data['books.ru'].count())) colors = ['red', 'blue', 'green', 'orange', 'yellow', 'pink', 'brown', 'purple'] for index,store in enumerate(stores): plt.scatter(x, data[store], alpha=0.5, color=colors[index], label=store) plt.xlabel('n') plt.ylabel('price') plt.legend(loc='best');
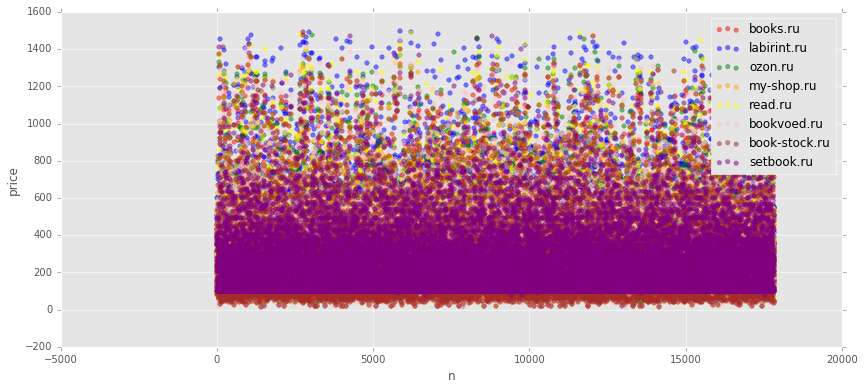
チャートは美しいが、役に立たない。 ポイントは単純に重なります。 最後のレイヤーは紫色で、明らかに前のレイヤーの上に塗りつぶされています。
最低価格の本の数
次に、各店舗で最低価格の書籍の数を調べてみましょう。 特定の本の最低価格は、一度に複数の店舗で購入できることに注意してください。 したがって、「min_ozon.ru」という形式の列を追加します。このストアのすべてのストアの最低価格がこのブックに設定されている場合は、NaNに1を設定します。 これらの値は、計算を簡単にするために選択されています。
import random def has_min_price(store): def inner(row): prices = list(row[:len(stores)]) min_price = min(prices) store_price = prices[stores.index(store)] return 1 if store_price == min_price else np.nan return inner # ;) def has_max_price(store): def inner(row): prices = list(row[:len(stores)]) max_price = max(prices) store_price = prices[stores.index(store)] return 1 if store_price == max_price else np.nan return inner for store in stores: data['min_' + store] = data.apply(has_min_price(store), axis=1) data['max_' + store] = data.apply(has_max_price(store), axis=1) HTML(data.head(10).to_html())
こんなテーブルになった
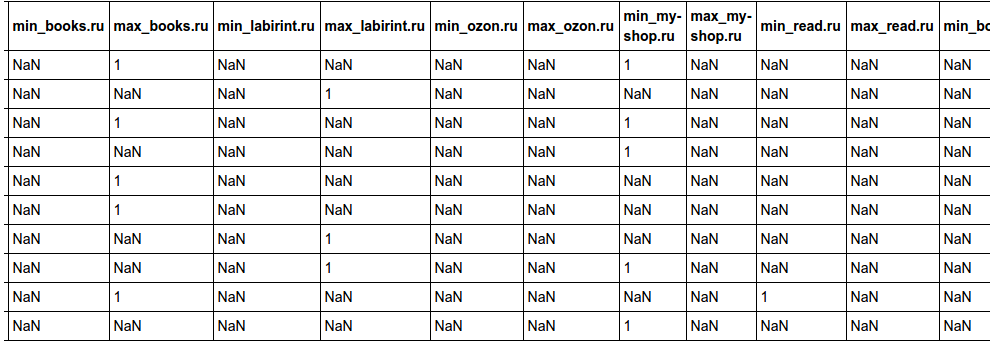
次に、各店舗の最低価格と最高価格で書籍の数を表示します。
desc = data.describe() def show_count(prefix): l = [] for column_name in desc: if prefix in column_name: cnt = desc[column_name][0] l.append((cnt, column_name)) for t in sorted(l, reverse=True): print(t[1].replace(prefix, ''), int(t[0])) print(' :', desc[stores[0]][0]) print() print(' :') show_count('min_') print() print(' :') show_count('max_')
総書籍数:17834.0 最低価格の本の数: book-stock.ru 8411 my-shop.ru 7735 setbook.ru 6359 bookvoed.ru 1884 ozon.ru 1015 read.ru 914 books.ru 379 labirint.ru 335 最大価格での本の数: books.ru 10323 labirint.ru 4383 bookvoed.ru 1143 setbook.ru 1052 ozon.ru 676 book-stock.ru 372 my-shop.ru 351 read.ru 265
Book-stock.ru、my-shop.ru、setbook.ruは、最低価格の本の数をリードしています。 これはすでに中央値から見たものと似ていますが、順序が変わりました。
そして、最高価格で、books.ru、labirint.ru、bookvoed.ruがトップです。
最低価格で並べ替え
ドットが互いに上書きしないように、少数の本に制限します。
def get_min(row): prices = list(row[:len(stores)]) return min(prices) # data['min'] = data.apply(get_min, axis=1) # , # 300- , data2 = data.sort_values(['min'])[::300] # plt.figure(figsize=(14, 10)) colors = ['red', 'blue', 'green', 'orange', 'yellow', 'pink', 'brown', 'purple'] for index,store in enumerate(stores): plt.scatter(x[:len(data2)], data2[store], alpha=1.0, color=colors[index], label=store) plt.xlabel('n') plt.ylabel('price') plt.legend(loc='upper left');
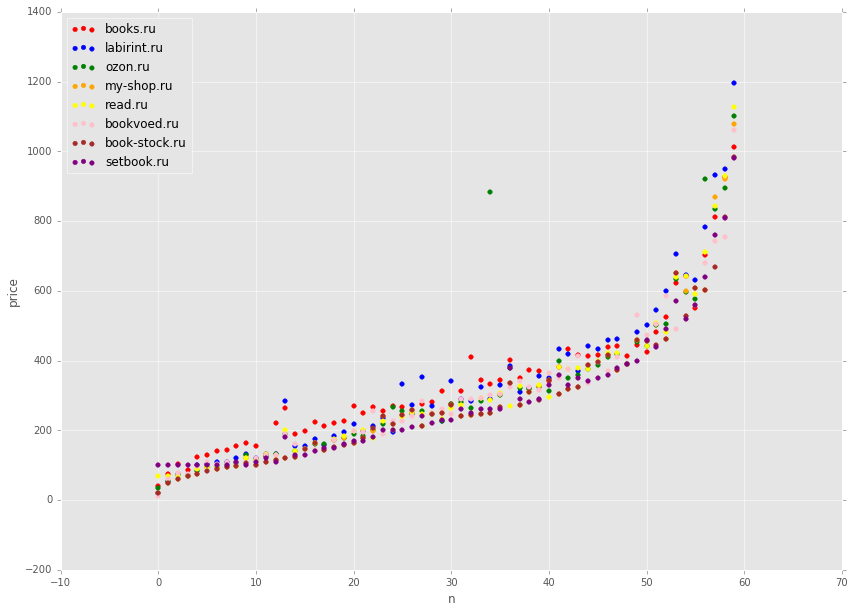
グラフには、ソートされたセットから等間隔で取得された約60冊の書籍の価格が表示されます。 価格は平均して非常に似ていることがわかります。 ただし、別の緑色の点を見ると、そこの価格は明らかに法外に誇張されています。 60ポイントではなく、17000すべてを表示した場合、明らかにこのような排出量が増えます。
結論
店舗の本の価格は、平均して100〜150ルーブルの範囲の最後のチャートと大まかに言えば、それほど大きな違いはないことがわかります。 一方で、病院の平均気温のようなものです。 価格はほとんど同じように見えますが、特定の本については、3倍高い価格で購入できます。 特定の本の価格に関する最新情報は、ウェブサイトでいつでも見ることができます 。
また、配送条件(価格と利便性)と個人割引を考慮していません。