数独のソリューションは、驚くほど簡単であることが判明しました。
基本的なスキームは次のとおりです。
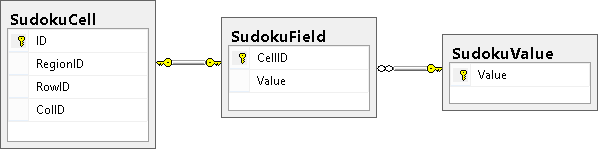
テーブルの説明:
- SudokuCell-すべてのセルのプロパティ(領域、行、列)の説明。
- SudokuValue-有効なセル値。
- SudokuField-既知の数値を設定するためのフィールド。
テーブルを作成するためのスクリプト:
-- IF EXISTS (SELECT * FROM sysobjects WHERE name='SudokuField') DROP TABLE SudokuField; IF EXISTS (SELECT * FROM sysobjects WHERE name='SudokuCell') DROP TABLE SudokuCell; IF EXISTS (SELECT * FROM sysobjects WHERE name='SudokuValue') DROP TABLE SudokuValue; ---------------------------------------------- -- ---------------------------------------------- CREATE TABLE SudokuCell( ID int NOT NULL, -- ID RegionID int NOT NULL, -- RowID int NOT NULL, -- ColID int NOT NULL, -- CONSTRAINT PK_SudokuCell PRIMARY KEY(ID) ) GO -- INSERT SudokuCell(ID,RegionID,RowID,ColID) SELECT reg.ID*100+ri*10+cj, reg.ID, (reg.ID/10-1)*3+ri, (reg.ID-1)%10*3+cj FROM (VALUES (11),(12),(13),(21),(22),(23),(31),(32),(33)) reg(ID) CROSS JOIN (VALUES(1),(2),(3)) r(i) CROSS JOIN (VALUES(1),(2),(3)) c(j) GO ---------------------------------------------- -- 1-9 ( ) ---------------------------------------------- CREATE TABLE SudokuValue( Value char(1) NOT NULL, CONSTRAINT PK_SudokuValue PRIMARY KEY(Value) ) GO -- INSERT SudokuValue(Value) VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9) GO ---------------------------------------------- -- ---------------------------------------------- CREATE TABLE SudokuField( CellID int NOT NULL, Value char(1) NOT NULL, CONSTRAINT PK_SudokuField PRIMARY KEY(CellID), CONSTRAINT FK_SudokuField_CellID FOREIGN KEY(CellID) REFERENCES SudokuCell(ID), CONSTRAINT FK_SudokuField_Value FOREIGN KEY(Value) REFERENCES SudokuValue(Value) ) GO
次のように、既知の番号をフィールドに入力します。
-- , TRUNCATE TABLE SudokuField GO -- INSERT SudokuField(CellID,Value)VALUES (1122,'3'),(1123,'4'), (1211,'1'),(1212,'5'), (1322,'8'),(1323,'9'),(1333,'3'), (2112,'2'),(2122,'4'),(2123,'7'),(2133,'9'), (2212,'6'),(2223,'9'),(2232,'2'), (2311,'8'),(2333,'1'), (3111,'1'), (3213,'2'),(3221,'9'), (3313,'5'),(3332,'7'),(3333,'4') GO
セル識別子(CellID)は次のように構築されます。
- 番号の1桁目と2桁目-どの地域(行、列)であるかを示します。
- 3番目と4番目の数字は、領域内の行と列の番号です。
私は次のサイトリンクから最初の塗りつぶしオプションを取りました。
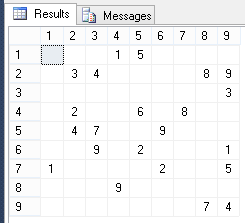
フィールドがどのように見えるか見てみましょう:
-- SELECT ISNULL([1],'') [1], ISNULL([2],'') [2], ISNULL([3],'') [3], ISNULL([4],'') [4], ISNULL([5],'') [5], ISNULL([6],'') [6], ISNULL([7],'') [7], ISNULL([8],'') [8], ISNULL([9],'') [9] FROM ( SELECT c.RowID,c.ColID,f.Value FROM SudokuCell c LEFT JOIN SudokuField f ON f.CellID=c.ID ) q PIVOT(MAX(Value) FOR ColID IN([1],[2],[3],[4],[5],[6],[7],[8],[9])) p ORDER BY RowID
次に、コメント付きのソリューション検索アルゴリズムがあります。
-- DECLARE @StartTime datetime=SYSDATETIME(); -- SELECT -- - RIGHT(CONCAT('0',CAST(CellNo AS varchar(2)),CHAR(ASCII('a')+Value-1)),3) ID, * INTO #SudokuVariant FROM ( -- SELECT ID CellID,RowID,ColID,RegionID, -- CAST(DENSE_RANK()OVER(ORDER BY ID) AS int) CellNo FROM SudokuCell WHERE ID NOT IN(SELECT CellID FROM SudokuField) ) e CROSS APPLY ( -- , SELECT v.Value FROM SudokuCell c JOIN SudokuField f ON f.CellID=c.ID AND (c.ColID=e.ColID OR c.RowID=e.RowID OR c.RegionID=e.RegionID) RIGHT JOIN SudokuValue v ON v.Value=f.Value WHERE c.ID IS NULL -- , // ) v --SELECT * FROM #SudokuVariant -- CREATE TABLE #SudokuTree( CellNo int NOT NULL, VariantPath varchar(1000) NOT NULL ) -- CellNo=1 INSERT #SudokuTree(CellNo,VariantPath) SELECT CellNo,ID FROM #SudokuVariant WHERE CellNo=1 --SELECT * FROM #SudokuTree -- DECLARE @MaxCellNo int=(SELECT MAX(CellNo) FROM #SudokuVariant) -- DECLARE @CurrCellNo int=1 DECLARE @NextCellNo int=@CurrCellNo+1 -- WHILE @CurrCellNo<@MaxCellNo BEGIN -- INSERT #SudokuTree(CellNo,VariantPath) SELECT v.CellNo, CONCAT(t.VariantPath,v.ID) FROM #SudokuTree t JOIN #SudokuVariant v ON t.CellNo=@CurrCellNo AND v.CellNo=@NextCellNo /* , // , .. #SudokuVariant */ WHERE NOT EXISTS( SELECT * FROM #SudokuVariant i WHERE i.CellNo<@NextCellNo -- --AND t.VariantPath LIKE '%'+i.ID+'%' AND CHARINDEX(i.ID,t.VariantPath)>0 -- - AND (i.RegionID=v.RegionID OR i.RowID=v.RowID OR i.ColID=v.ColID) AND i.Value=v.Value ) /* .. VariantPath, , - */ --DELETE #SudokuTree WHERE CellNo=@CurrCellNo -- SET @CurrCellNo+=1 SET @NextCellNo+=1 END --SELECT * FROM #SudokuTree WHERE CellNo=@MaxCellNo -- INSERT SudokuField(CellID,Value) SELECT v.CellID,v.Value FROM #SudokuVariant v JOIN ( -- , SELECT TOP 1 * FROM #SudokuTree WHERE CellNo=@MaxCellNo -- ) r ON r.VariantPath LIKE '%'+v.ID+'%' -- DROP TABLE #SudokuTree DROP TABLE #SudokuVariant -- PRINT ' - '+CONVERT(varchar(30),DATEADD(MS,DATEDIFF(MS,@StartTime,SYSDATETIME()),'19000101'),114);
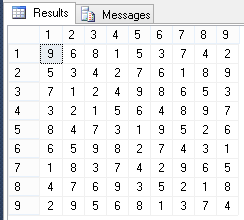
見つかった解決策を見てみましょう。
-- SELECT ISNULL([1],'') [1], ISNULL([2],'') [2], ISNULL([3],'') [3], ISNULL([4],'') [4], ISNULL([5],'') [5], ISNULL([6],'') [6], ISNULL([7],'') [7], ISNULL([8],'') [8], ISNULL([9],'') [9] FROM ( SELECT c.RowID,c.ColID,f.Value FROM SudokuCell c LEFT JOIN SudokuField f ON f.CellID=c.ID ) q PIVOT(MAX(Value) FOR ColID IN([1],[2],[3],[4],[5],[6],[7],[8],[9])) p ORDER BY RowID
ソリューションの他の例:

次のスクリプトを使用して、初期値を設定しました。
スクリプトを表示...
2番目の例:
3番目の例:
-- , TRUNCATE TABLE SudokuField GO -- INSERT SudokuField(CellID,Value)VALUES (1112,'7'),(1113,'1'),(1131,'4'),(1132,'9'), (1212,'9'),(1221,'3'),(1223,'6'), (1311,'8'),(1331,'7'),(1333,'5'), (2112,'1'),(2121,'9'),(2123,'2'), (2211,'9'),(2233,'8'), (2321,'6'),(2323,'3'),(2332,'2'), (3111,'8'),(3113,'5'),(3133,'7'), (3221,'6'),(3223,'7'),(3232,'4'), (3312,'7'),(3313,'6'),(3331,'3'),(3332,'5') GO
3番目の例:
-- , TRUNCATE TABLE SudokuField GO -- INSERT SudokuField(CellID,Value)VALUES (1132,'4'), (1221,'9'),(1223,'4'),(1231,'8'),(1233,'5'), (1311,'7'),(1321,'2'),(1323,'3'), (2113,'7'),(2121,'9'),(2133,'3'), (2212,'1'), (2311,'6'),(2332,'5'),(2333,'2'), (3111,'6'),(3112,'2'),(3121,'7'), (3223,'3'),(3233,'8'), (3323,'9') GO
私のコンピューターでは、解決策は6秒以内です(指定された初期値による):
- 例1:4.547秒
- 例2:5.317秒
- 例3:3.690秒
実際には、それだけです。
完全なスクリプトは、次のリンク( スクリプト)からダウンロードできます 。
記事が面白かったと思います。
頑張って、あなたの注意をありがとう!
PS(2015年12月4日)
MS SQLでOracleクエリを書き直しました。
WITH x AS( SELECT s, CHARINDEX(' ',s) ind -- --FROM (SELECT ' 15 34 89 3 2 6 8 47 9 9 2 11 2 5 9 74' s) q --FROM (SELECT ' 71 9 8 3 6 49 7 5 1 9 9 2 6 3 8 2 8 5 76 6 7 7 4 35 ' s) q FROM (SELECT ' 7 9 42 3 4 8 5 7 1 6 9 3 5262 7 3 9 8 ' s) q UNION ALL SELECT CAST(STUFF(s,ind,1,z) AS varchar(81)), -- CHARINDEX(' ',s,ind+1) -- FROM x CROSS JOIN (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)) v(z) WHERE ind>0 AND NOT EXISTS( SELECT * FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9)) v(lp) WHERE z=SUBSTRING(s,(ind-1)/9*9+lp,1) OR z=SUBSTRING(s,(ind-1)%9-8+lp*9,1) OR z=SUBSTRING(s,((ind-1)/3)%3*3+(ind-1)/27*27+lp+(lp-1)/3*6,1) ) ) SELECT s FROM x WHERE ind=0
Oracleクエリの表示...
with x( s, ind ) as ( select sud, instr( sud, ' ' ) --from ( select ' 15 34 89 3 2 6 8 47 9 9 2 11 2 5 9 74' sud from dual ) --from ( select ' 71 9 8 3 6 49 7 5 1 9 9 2 6 3 8 2 8 5 76 6 7 7 4 35 ' sud from dual ) from ( select ' 7 9 42 3 4 8 5 7 1 6 9 3 5262 7 3 9 8 ' sud from dual ) union all select substr( s, 1, ind - 1 ) || z || substr( s, ind + 1 ) , instr( s, ' ', ind + 1 ) from x , ( select to_char( rownum ) z from dual connect by rownum <= 9 ) z where ind > 0 and not exists ( select null from ( select rownum lp from dual connect by rownum <= 9 ) where z = substr( s, trunc( ( ind - 1 ) / 9 ) * 9 + lp, 1 ) or z = substr( s, mod( ind - 1, 9 ) - 8 + lp * 9, 1 ) or z = substr( s, mod( trunc( ( ind - 1 ) / 3 ), 3 ) * 3 + trunc( ( ind - 1 ) / 27 ) * 27 + lp + trunc( ( lp - 1 ) / 3 ) * 6 , 1 ) ) ) select s from x where ind = 0
私のコンピューターでは、MS SQLは実行時間でOracleよりもはるかに進んでいます。
- 例1:Oracle-1.079秒、MS SQL-0.303秒
- 例2:Oracle-2.991秒、MS SQL-0.787秒
- 例3:Oracle-3.037秒、MS SQL-0.773秒
Oracleバージョン-11g Enterprise Editionリリース11.2.0.1.0-64ビット製品版
MS SQLバージョン2014-12.0.2269.0(X64)Developer Edition(64ビット)