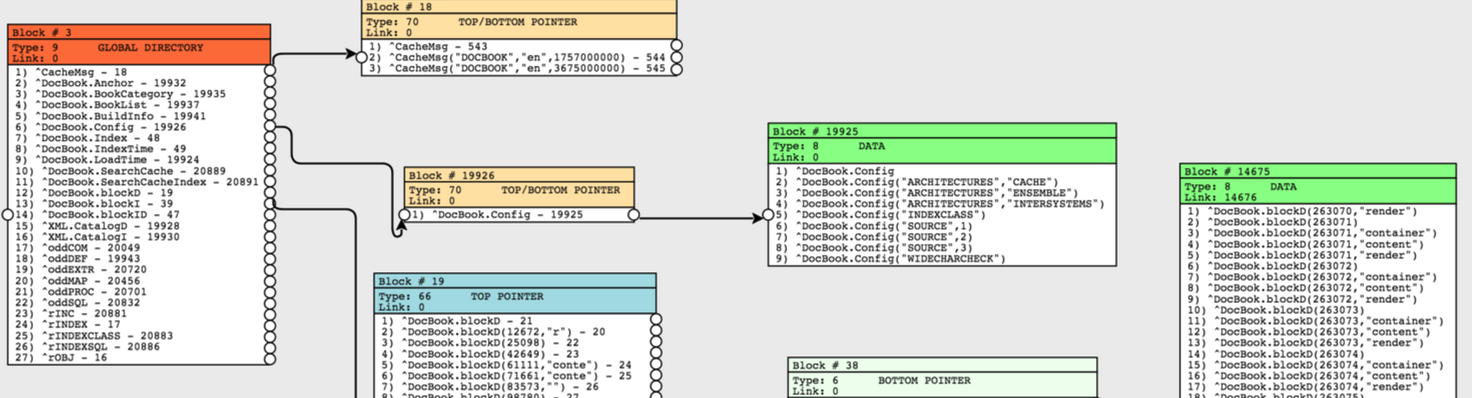
デモンストレーションのために、新しいデータベースを作成し、Cachéが新しく作成されたデータベースに対してデフォルトで初期化するすべてのグローバルをクリアしました。 単純なグローバルを作成します。
set ^colors(1)="red" set ^colors(2)="blue" set ^colors(3)="green" set ^colors(4)="yellow"

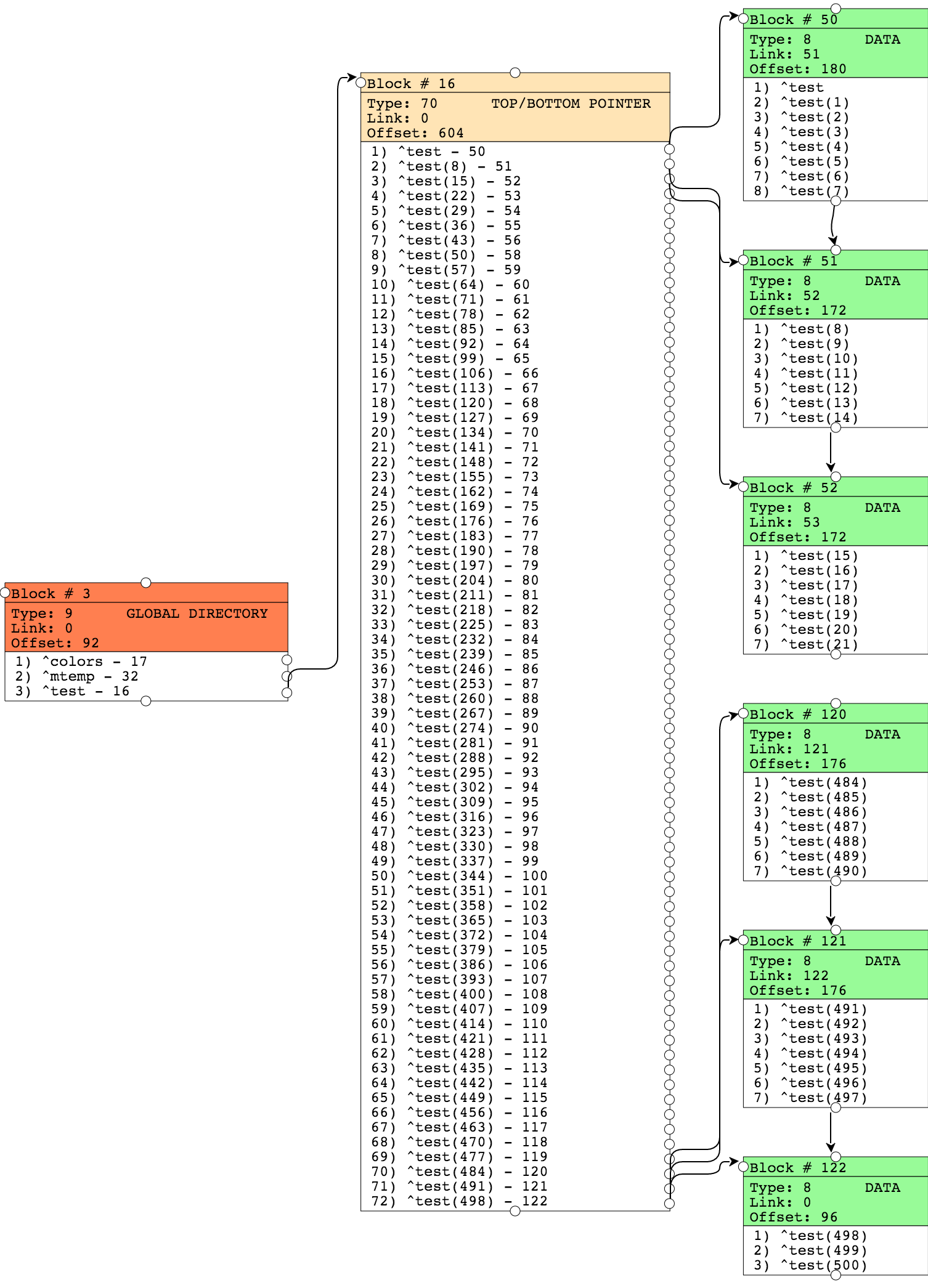
作成されたグローバルのブロックを示す図に注意してください。 グローバルはシンプルなので、もちろん、その説明はタイプ9ブロック(グローバルカタログブロック)で確認できます。 グローバルツリーはまだ深くないため、すぐに「上下のポインター」ブロック(タイプ70)に移動し、データブロックへのリンクをすぐに指定できます。これは1つの8KBブロックに収まります。
ここで、1つのブロックに収まらなかったような量の値を別のグローバルに書き留めます-ポインターブロックに新しいノードが表示される方法を確認します。これは、最初のブロックに収まらなかった新しいデータブロックを参照します。
1000文字の長さで50個の値を書き込みます。 データベースのブロックサイズは8192バイトです。
set str="" for i=1:1:1000 { set str=str_"1" } for i=1:1:50 { set ^test(i)=str } quit
次の図に注意してください。
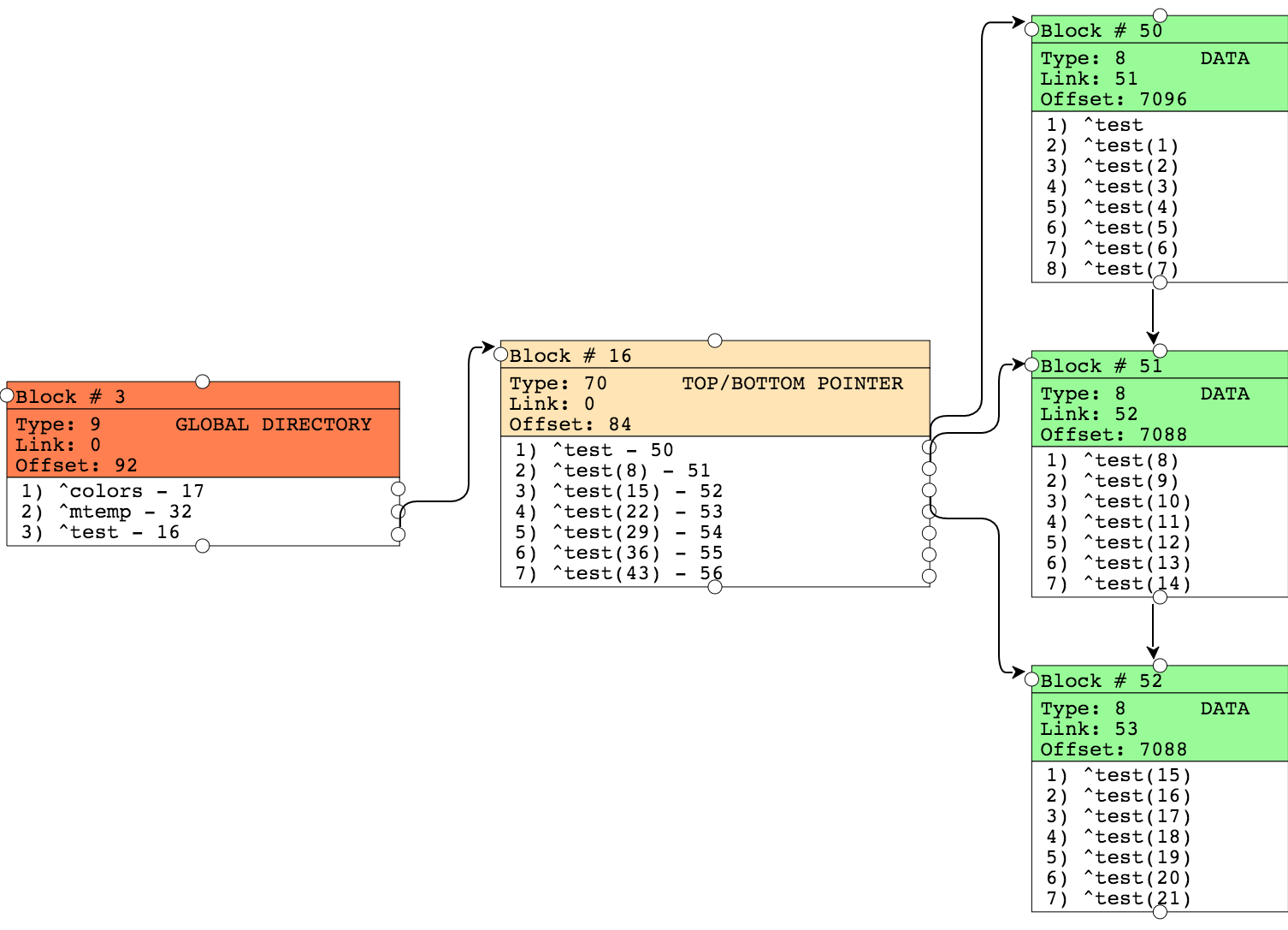
ポインターブロックレベルでは、データブロックを参照する複数のノードがあります。 各データブロックには、次のブロックへのリンクがあります(「右リンク」)。 オフセット-このデータブロックで占有されているバイト数を示します。
次に、ブロック分割をシミュレートしてみましょう。 最初のブロックに非常に多くの値を追加して、合計8KBのブロックサイズを超えると、このブロックが2つに分割されます。
コード例
set str="" for i=1:1:1000 { set str=str_"1" } set ^test(3,1)=str set ^test(3,2)=str set ^test(3,3)=str
結果は以下のとおりです。

ブロック50は分割され、新しいデータで補完され、それから置き換えられた値は現在ブロック58にあります。このブロックへのリンクがポインターブロックに表示されました。 他のブロックは変更されていません。
長い行の例
8KB(データブロックサイズ)より長い文字列を書き込むと、「長いデータ」ブロックが得られます。 たとえば、サイズ10,000バイトの文字列を書き込むことで、この状況をシミュレートできます。
コード例
set str="" for i=1:1:10000 { set str=str_"1" } for i=1:1:50 { set ^test(i)=str }
結果を見てみましょう:

その結果、画像内のブロックの構造が保持されました。 新しいグローバルノードは追加せず、値のみを変更しました。 ただし、すべてのブロックのオフセット値(占有バイト数)は変更されています。 たとえば、ブロックNo. 51の場合、新しいオフセット値は172になり、前回は7088でした。 新しい値がブロックに収まらないため、データの最後のバイトへのポインターが変更されているはずですが、データは現在どこに保存されているのでしょうか? 現時点では、私のプロジェクトは「大きなブロック」に関する情報を表示する機能をまだ実装していません。 ^ REPAIRユーティリティを使用して、ブロック51の新しいコンテンツに関する情報を表示しましょう。
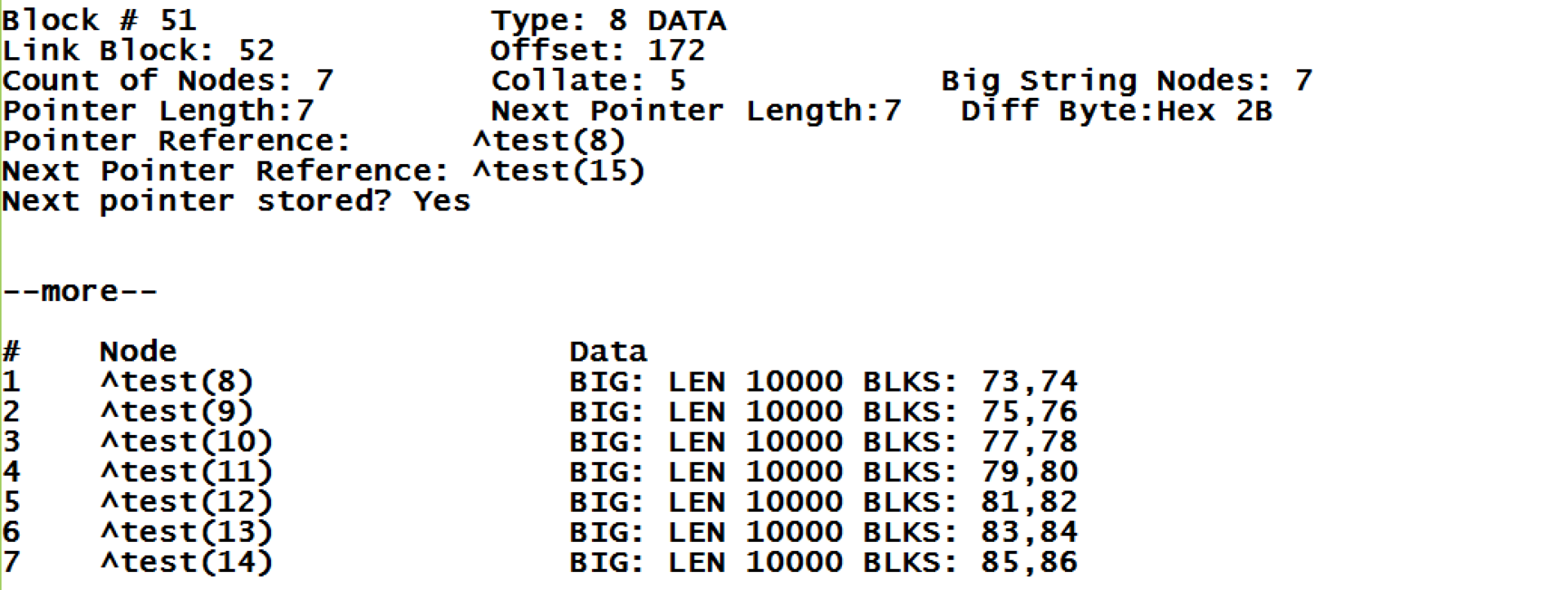
このユーティリティが何を示しているかについて、さらに詳しく説明します。 右のブロックNo. 52へのリンクがあります。同じ番号が次のノードのポインターの親ブロックに示されています。 グローバルの並べ替えはタイプ5です。大きな行を持つノードの数は7です。場合によっては、ブロックには、すべての同じブロック内で、一部のノードのデータ値と他のノードの長い行の両方を含めることができます。 また、次のブロックの開始時に予想されるグローバルリンクを確認します(Next Pointer Reference)。
長い行のブロックについて:ここで、BIGキーワードがグローバルの値として指定されていることがわかります。これは、データが実際に「大きなブロック」にあることを示しています。 次に、同じ行に、含まれている行の全長と、この値を格納するブロックのリストが表示されます。 73番の「長い行のブロック」を見てみることができます。
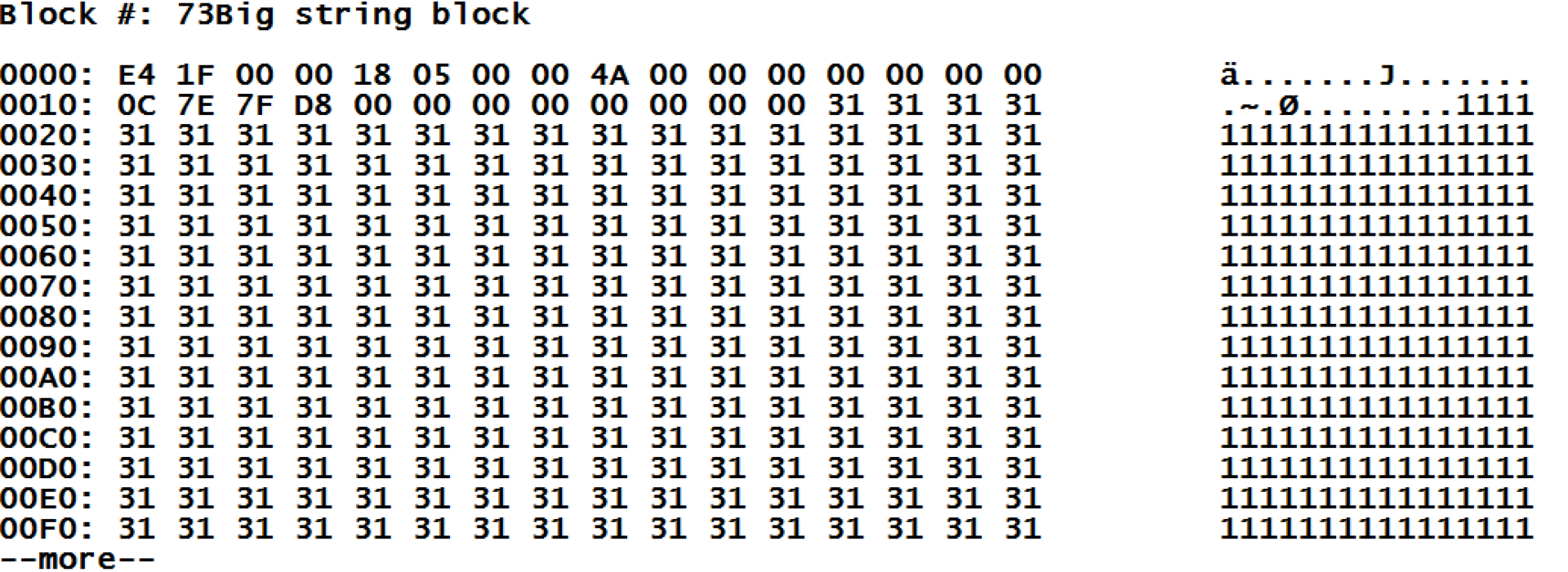
残念ながら、このブロックは暗号化されずに表示されます。 しかし、ここでは、ブロックヘッダー(常に28バイトの長さ)からのオーバーヘッド情報の後に、入力したデータが来ることがわかります。 また、どのデータを知っているかは、ヘッダーに示されているものを簡単に解読できます。
| 役職 | 価値 | 説明 | 詳細 |
| 0-3 | E4 1F 00 00 | オフセットはデータの終わりを示します | 8164に加えて、ヘッダーの28バイトは8192バイトです。
ブロックがいっぱいです。 |
| 4 | 18 | ブロックタイプ | 思い出してくださいが、値24は大きな文字列のブロックの型です。 |
| 5 | 05 | 仕分け | ソート5、これは「標準のキャッシュ」です |
| 8-11 | 4A 00 00 00 | 右リンク | 74でした。
思い出すと、値はブロック73と74に保存されています |
ブロック51のデータは172バイトしか占有しないことを思い出させてください。 これは、大きな値を保存したときに起こりました。 ブロックはほとんど空になっていることがわかります-172バイトの有用なデータですが、8kbかかります! そのような状況では、空き領域が最終的に新しい値で満たされることは明らかですが、Cachéはそのようなグローバルを圧縮する機会も提供します。 これを行うために、 %Library.GlobalEditクラスにはCompactGlobalメソッドがあります。 この方法の有効性を検証するために、例を繰り返しますが、たとえば500ノードを作成するなど、大量のデータを使用します。
それが私たちが得たものです。
以下では、すべてのブロックを表示しませんでしたが、意味は明確なはずです。 データを含む多くのブロックがありますが、ノードの数は少ないです。
kill ^test for l=1000,10000 { set str="" for i=1:1:l { set str=str_"1" } for i=1:1:500 { set ^test(i)=str } } quit
以下では、すべてのブロックを表示しませんでしたが、意味は明確なはずです。 データを含む多くのブロックがありますが、ノードの数は少ないです。
CompactGlobalメソッドを実行します。
w ##class(%GlobalEdit).CompactGlobal("test","c:\intersystems\ensemble\mgr\habr")
結果を見てみましょう。 ポインターブロックには2つのノードしかありません。 値はすべて2つのデータブロックに入りましたが、以前はポインターブロックに72個のノードがありました。 したがって、ブロックの読み取りが少なくて済むため、70個のブロックを取り除き、グローバルへの完全なバイパスによりデータへのアクセス時間を短縮しました。
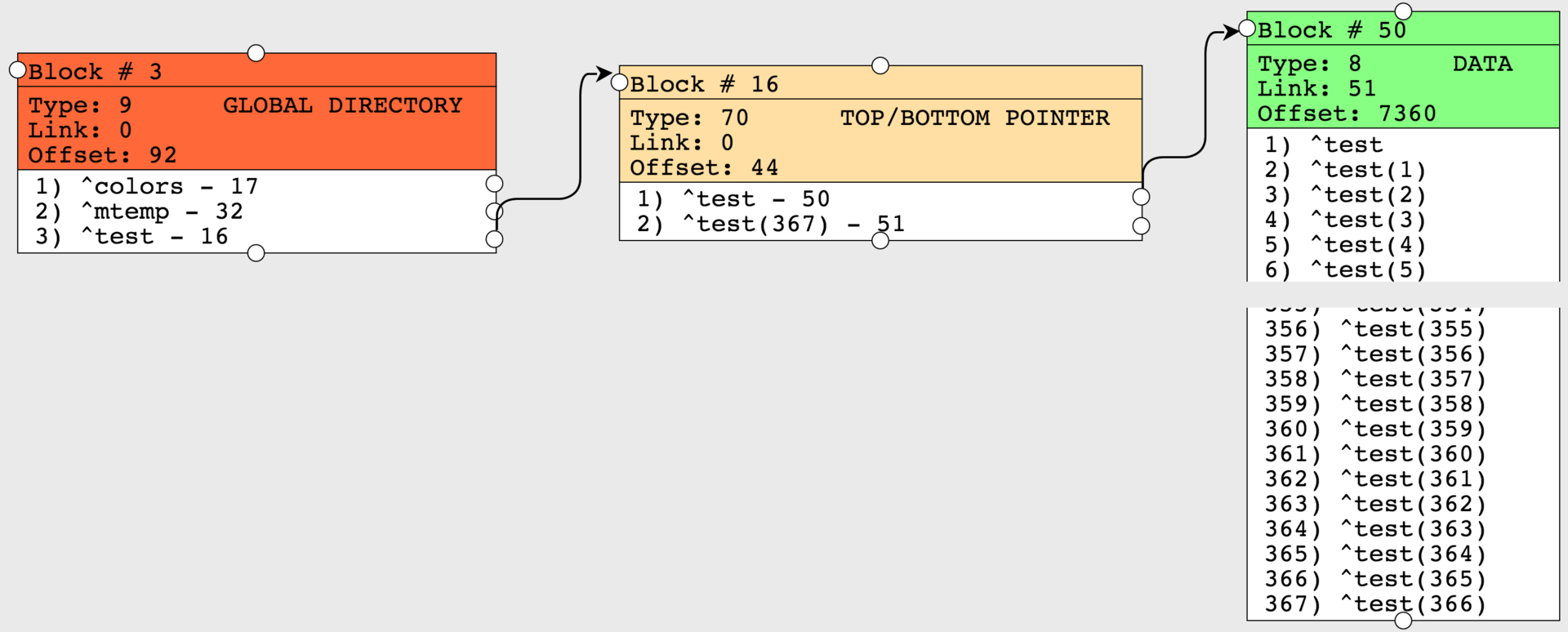
CompactGlobalは、グローバルの名前、データベース、取得する充填率など、いくつかのパラメーターを入力として受け入れます。デフォルト値は90です。そして、オフセット(占有バイト数)が7360に等しくなりました。最も90%のカバレッジ。 出力関数のいくつかのパラメーター:処理されたメガバイト数と圧縮後のメガバイト数。 以前は、グローバルは^ GCOMPACTユーティリティを使用して圧縮されていましたが、これは現在廃止されていると見なされています。
ブロックが不完全なままになる可能性がある状況は非常に正常であることに注意してください。 さらに、グローバル圧縮が常に望ましいとは限りません。 たとえば、グローバルがより頻繁に読み取られ、実際には変更されない場合、圧縮が役立ちます。 しかし、グローバルがアクティブに変化している場合、データブロックの特定のまばらさがブロックを分割する頻度を減らし、新しいデータがより速く書き込まれます。
次の部分では、InterSystemsスクールで最近開催されたハッカソンの一部として実装された私のプロジェクトの別の可能性について説明します-ベースユニットの分布のマップとその実用化について。