
「 以前の記事で、 MS Excelでマクロと数式を使用して大きなセマンティックカーネルをクラスタリングすることについて話しました。 今回は、さらに興味深いこと-単語形式、レンマ化、Yandex、Google、Zaliznyakの辞書、そして再びExcelについて-その制限、それらをバイパスする方法、信じられないほどのバイナリ検索速度についてお話します。 この記事は、前の記事と同様に、コンテキスト広告の専門家とSEOの専門家にとって興味深いものです。
では、どこから始まったのでしょうか?
ご存じのとおり、Yandex検索アルゴリズムとGoogle検索の主な違いは、ロシア語の形態のサポートです。 つまり、最も優れた機能の1つは、Yandex.Directでは、1つの単語形式を除外キーワード(任意)として指定するだけで十分であり、広告はそのすべての単語形式に対して表示されないことです。 彼は除外キーワードに「無料」という言葉を入れました。「無料」、「無料」、「無料」、「無料」などの言葉には印象がありません。 便利ですか? もちろん!
ただし、すべてがそれほど単純ではありません。 Habré自体への投稿など、Yandexの形態の奇妙なトピックについて複数の記事が書かれており、私は仕事の過程で繰り返しそれらに出会いました。 紛争は今日まで続いていますが、このアルゴリズムは、すべてにかかわらず、Googleロジックよりも有利であると考えることができます。
奇妙なことは、動詞や形容詞などのすべての単語形式のグループに名詞の単語形式のグループと同音異義語が含まれている場合、Yandexは実際にそれらを単一の単語形式のセットに「接着」し、 すべてが広告を表示することです。
ここに良い例があります、 NashLosを許してください :
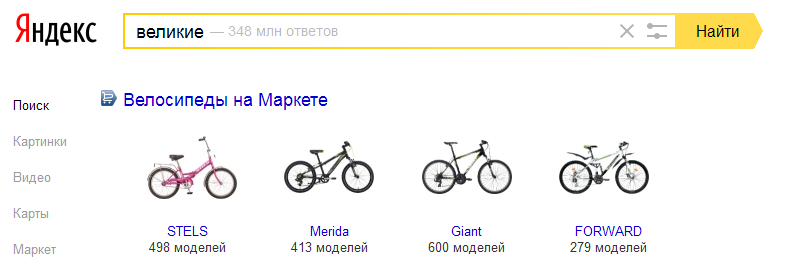
誰もが理解しているように、「偉大な」「導かれる」という形容詞の短縮形は、「偉大な顔」という言葉の同義語であり、「自転車」という言葉と同義語です。 もちろん、「すばらしい」という言葉自体には「すばらしい」という言葉がないため、このリクエストでそれを表示するのは明らかに間違っています。 言語学者の言語で、Yandexはパラダイムを混同しました。
自然出力の状況ははるかに良く、おそらくそこのアルゴリズムはより複雑で最適化されています。 または、これは競争の激化によるものかもしれません。 SEOはシェアウェアであり(州が独自のウェブマスターを持っている場合)、コンテキスト広告の前向きな傾向にもかかわらず、Yandex.Directでのクリックごとに支払うハンターの桁が1桁少なくなっています。 たぶん、VCGオークションはすべてを修正しますか? 待って、見て。
しかし、 善良な企業には独自の癖があります。 Google
一般に、Yandex.DirectとAdWordsを使用して作業したときの結論は、使用するツールが何であれ、最大限の結果を得るには単語形式を詳しく調べる必要があるということです。 そのため、Yandexアルゴリズムに最も近い単語形式の完全なデータベースが必要でした。 まだ生きているものを知ったとき、私は信じられないほど幸せでした、そして、神は彼にまだ健康と長命を与えました、 Zaliznyak Andrei Anatolyevichはそのような辞書を作成しました。 この辞書には約100,000のセマンティックパラダイムが含まれており、そのうち最も多面的なものは182語です。 合計で、辞書全体は250万語をわずかに超えています。 彼は多くの形態認識システムの基礎を形成しました。 私がインターネットで見つけ、仕事のニーズに合わせてExcelに正常に統合されたのは、電子的な表形式のこの辞書でした。
好奇心の強い人には、疑問が生じるかもしれません-なぜ250万語をExcelに挿入する必要があったのですか?
- まず、どのような辞書なのか興味がありました。 実際、Yandexは単語形式をサポートし始め、それを基礎としてデータベースとして使用しました。 さらに、もちろん、Yandexプログラマーは大幅な進歩を遂げました。Mystemの最新バージョンからわかるように、上記の同音異義語を除去するアルゴリズムがあります(理解しているように、アルゴリズムは近くの単語の品詞を認識し、この情報に基づいて部分についての仮定を行います)元の「多義的な」単語のスピーチ)。 それにもかかわらず、インターネットの巨人の主な競争上の優位性は、「偉大で強力な」形態のサポートです-行われた仕事の結果と、80歳の教授の仕事の一部です。
- 私が知っており、パブリックドメインにあるシンプルなインターフェイスを備えた無料のレンマタイザー( K50やAndrey Kashinなど )は、私の要件を満たしていません。 その発行はYandexアルゴリズムに準拠していません。 そして、私にとって、彼らの開発者ではなく、この状況を解決する方法はありません。
- テキストの処理の大部分はExcelテーブルで発生し、ウェブインターフェースが常に利用可能または大量のデータで「遅くなる」わけではないため、すべてのツールをローカルで「手元に」持っている方が便利です。
- 正規化が組み込まれていない「Recognizer Robot 1.0」は価値がなく、私自身もこれを認識していました。 正規化されていないコアをクラスタリングするコンテキスト広告スペシャリストのポイントは何ですか? それでも同じように、Webインターフェイスにアクセスし、そこで要求を正規化して、Excelでコピーして処理する必要があります。
- Excelでバイナリ検索を発見した後、実際に大量のデータに対して実行してみました。 そして、なぜMS Excelで250万個のセルが大量ではないのですか?
レンマタイザーとバイナリ検索の誕生
したがって、悪名高いマクロと式をブラックジャックして、独自のレマタイザーを作成することにしました。 その過程で、レンマ化とは、スロフォルムをレンマに変換するプロセスであり、最初の辞書形式(動詞には不定詞、単数形の主格には名詞と形容詞に)を使用します。
努力の結果は、次のリンクからダウンロードできます。 認識ロボット-3
視覚的には、ファイルは実際には以前のバージョンと変わりません。 唯一の違いは、2つの追加シート(辞書)が追加され、それらを検索して初期フォームを返すマクロが追加されることです。 Excelの制限は、行の20乗の2から1行を引いたもの(100万を少し超える)であるため、辞書を2シートに分割し、この機能に基づいてマクロを作成する必要がありました。 最初は、データに3枚のシートが必要であると想定されていましたが、幸い、辞書にはかなりの数のテイクがありました。 それらはコンピュータの複製であり、人にとっては異なるパラダイムの異なる単語形式である可能性があります。
ファイルの中心には、Excelファイルの標準による巨大な配列があります。 このようなデータの配列の処理はリソースを大量に消費し、非常に時間がかかる場合があります。 この問題は、冒頭で述べたExcelのバイナリ(バイナリ)検索によって解決されました。 線形検索アルゴリズムは、250万件以上のレコードすべてを行単位で実行できます。これには多くの時間がかかります。 バイナリ検索では、4つの主要な手順を実行するため、データ配列を非常に迅速に処理できます。
- データ配列は半分に分割され、読み取り位置は中央に移動します。
- 見つかった値(let n)は、探している値(let m)と比較されます。
- m> nの場合、m <nが最初の部分である場合、配列の2番目の部分が取得されます。
- 次に、データ配列の選択した部分で手順1〜3を繰り返します。
簡単に言えば、バイナリ検索アルゴリズムは、辞書で単語を検索する方法に似ています。 辞書を中央で開き、必要な単語の半分を調べます。 最初に言ってみましょう。 正しい単語が見つかるまで、最初の部分を中央で開き、半分まで続けます。 2〜20度の操作(Excelの列の最大占有率)を行う必要がある線形とは異なり、バイナリでは、たとえば20だけを行う必要があります。 同意し、印象的です。 ファイルを操作することにより、バイナリ検索の速度を確認できます。それぞれ300万セル、クエリ内の各単語を数秒で検索します
すべての数式とマクロは元のファイルでのみ機能し、他のファイルでは機能しません。 その他。 ファイル内の辞書を補足する場合、ファイルを処理する前に、辞書をアルファベット順にソートする必要があります-すでに理解したように、これにはバイナリ検索のロジックが必要です。
もちろん、少なくとも3215文字の巨大な数式を使用しているため、このソリューションを最もエレガントなものと呼ぶことはできません。 自分の目でそれを見て、ロジックを理解しようとする人は、中に入って見ることができます。
表示する
WHAT(IF(substring(A1; ""; 1)<"m"; IF ERROR(IF(VLOOKUP(substring(A1; ""; 1); 'AL'!$ A:$ B; 1; 1) <サブストリング(A1; ""; 1);サブストリング(A1; ""; 1); VLOOKUP(サブストリング(A1; ""; 1); 'A-L'!$ A:$ B; 2; 1)) ; ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 1); 'M-Z'!$ A:$ B; 1; 1)<substring(A1; ""; 1); substring( A1; ""; 1); VLOOKUP(substring(A1; ""; 1); 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(substring(A1 ; ""; 2)<"m"; IF ERROR(IF(VLOOKUP(substring(A1; ""; 2); 'A-L'!$ A:$ B; 1; 1)<substring(A1; "" ; 2); substring(A1; ""; 2); VLOOKUP(substring(A1; ""; 2); 'AL'!$ A:$ B; 2; 1)); ""); IF ERROR( IF(VLOOKUP(substring(A1; ""; 2); 'M-Z'!$ A:$ B; 1; 1)<substring(A1; ""; 2); substring(A1; ""; 2) ; VLOOKUP(substring(A1; ""; 2); 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(substring(A1; ""; 3)< "M"; IF ERROR(IF(VLOOKUP(substring(A1; ""; 3); 'AL'!$ A:$ B; 1; 1)<substring(A1; ""; 3); substring(A1 ; ""; 3); VPN(部分文字列(A1; ""; 3); 'A-L'!$ A:$ B; 2; 1)); ""); IFエラー A(IF(VLOOKUP(substring(A1; ""; 3); 'M-Z'!$ A:$ B; 1; 1)<substring(A1; ""; 3); substring(A1; ""; 3); VLOOKUP(サブストリング(A1; ""; 3); 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(サブストリング(A1; ""; 4 )<"M"; IFエラー(IF(VLOOKUP(substring(A1; ""; 4); 'AL'!$ A:$ B; 1; 1)<substring(A1; ""; 4); substring(A1; ""; 4); VLOOKUP(部分文字列(A1; ""; 4); 'A-L'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 4); 'M-Z'!$ A:$ B; 1; 1)<substring(A1; ""; 4); substring(A1; ""; 4); VLOOKUP(サブストリング(A1; ""; 4); 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(サブストリング(A1; ""; 5 )<"M"; IF ERROR(IF(VLOOKUP(substring(A1; ""; 5); 'AL'!$ A:$ B; 1; 1)<substring(A1; ""; 5); substring (A1; ""; 5); VLOOKUP(substring(A1; ""; 5); 'AL'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring (A1; ""; 5); 'M-Z'!$ A:$ B; 1; 1)<部分文字列(A1; ""; 5);部分文字列(A1; ""; 5); VLOOKUP(部分文字列( A1; ""; 5); 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(部分文字列(A1; ""; 6)<"m"; IFエラー(IF(VLOOKUP(substring(A1; ""; 6); 'A-L'!$ A:$ B; 1; 1)<substring(A1; ""; 6); substring(A1; ""; 6 ); VLOOKUP(substring(A1; ""; 6); 'AL'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 6 ); 'M-Z'!$ A:$ B; 1; 1)<部分文字列(A1; ""; 6);部分文字列(A1; ""; 6); VLOOKUP(部分文字列(A1; ""; 6) ; 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(部分文字列(A1; ""; 7)<"m"; IFエラー(IF(B OL(サブストリング(A1; ""; 7); 'A-L'!$ A:$ B; 1; 1)<サブストリング(A1; ""; 7);サブストリング(A1; ""; 7); VLOOKUP (substring(A1; ""; 7); 'A-L'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 7); ' M-Z '!$ A:$ B; 1; 1)<部分文字列(A1; ""; 7);部分文字列(A1; ""; 7); VLOOKUP(部分文字列(A1; ""; 7); 'M-Z'!$ A:$ B; 2; 1)); ""))& ""&IF(部分文字列(A1; ""; 8)<" m "; IF ERROR(IF(VLOOKUP(substring(A1;" "; 8); 'A-L'!$ A:$ B; 1; 1)<substring(A1;" "; 8); substring(A1; ""; 8); VLOOKUP(substring(A1; ""; 8); 'AL'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 8); 'M-Z'!$ A:$ B; 1; 1)<部分文字列(A1; ""; 8);部分文字列(A1; ""; 8); VLOOKUP(部分文字列(A1; " "; 8); 'M-Z'!$ A:$ B; 2; 1));" "))&" "&IF(部分文字列(A1;" "; 9)<" m "; IFエラー(IF( VLOOKUP(substring(A1; ""; 9); 'A-L'!$ A:$ B; 1; 1)<substring(A1; ""; 9); substring(A1; ""; 9); VLOOKUP (substring(A1; ""; 9); 'AL'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 9); ' M-Z '!$ A:$ B; 1; 1)<部分文字列(A1; ""; 9);部分文字列(A1; ""; 9); VLOOKUP(部分文字列(A1; ""; 9);' M -I '!$ A:$ B; 2; 1)); ""))& ""&IF(substring(A1; ""; 10)<"m"; IF ERROR(IF(VLOOKUP(substring(A1; " "; 10); 'A-L'!$ A:$ B; 1; 1)<部分文字列(A1;" "; 10);部分文字列(A1;" "; 10); VLOOKUP(部分文字列(A1;" " ; 10); 'A-L'!$ A:$ B; 2; 1)); ""); IF ERROR(IF(VLOOKUP(substring(A1; ""; 10); 'M-Z'!$ A:$ B; 1; 1)<サブストリング(A1; ""; 10);サブストリング(A1; ""; 10); VLOOKUP(サブストリング(A1; ""; 10); 'M-Z'!$ A:$ B; 2 ; 1)); "")))
ただし、レンマタイザーでの作業中に遭遇しなければならない問題は、巨大な式だけではありません。
- Zalizniakの辞書は古い版(1977年)であり、単語の形式の中には2015年の最も単純で最も馴染みのある単語(たとえば「コンピューター」)がありません。 それが、Yandexがファイナライズしている理由です。ファイナライズしているので、必要であれば誰でも修正できます。 問題は完全には解決されていませんが、「ロボット」の今後の更新を待ちます-すべてが解決します。
- 辞書に適切な名前はありません-それらもそこに追加する必要があります。 これに取り組み、名前、世界の国々、ロシアの都市を追加しました。
現代の単語の欠如の問題は、さまざまなオープンソースから収集された単語を追加することで解決されます。 特に、公開後の時点で、300,000件の商用リクエストのデータベースが既にコンパイルされており、データベースと比較されます。 不足している単語は、必要な単語形式で辞書に追加されます。 30万語では不十分のように思えるかもしれませんが、Zaliznyakの辞書を大幅に拡張するにはこれで十分です。
さらに、「Recognition Robot 2」では、他のレンマタイザーの上記のエラーは発生しません。たとえば、「Avito」は単語形式と見なされ、動詞「Avit」を返し、この存在しない動詞の多数の単語形式が生成されます。
PS:要望やバグ報告は大歓迎です。
現在、Dmitryは反対の操作を実行する別のツールに取り組んでいます:補題を返さずに、与えられた単語の単語形式を生成します。 マクロと巨大な数式の別のストリームを待っています。 コンテキスト広告自動化システムに加えて、RealWebではExcelで認識ロボットを積極的に使用しています-これは、Web全般、特にオンライン広告での作業に必要なセマンティックコアでの作業に非常に役立ちます。ウェブ全般、特にオンライン広告で作業するために必要なセマンティックコア。 これらのツールがあなたにとっても役立つと確信しています!