
目標は非常に野心的でした-理想的には、プログラムが入力に送られ、それをこのようにねじり、人間の介入なしに可能な限りあらゆる方法で個々のフラグメントを高速化し、同時に最適化のためのベースを収集するようなことをすることです。 すべての問題は解決されましたが、実際の利益は得られなかったとすぐに言わなければなりません。 しかし、このプロセスで得られた結果の一部は、共有するのに十分興味深いと思われました。
たとえば、式に対応する一連の算術命令(手元にある何らかの種類の数学ライブラリから取得)のこのような楽しい最適化は次のとおりです。
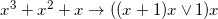 JITをオフにしたJava 6では約10%の加速が得られましたが、一見、これらの式が同等であることは明らかではありません(これはどこですか、それとも一般に合法ですか?!) カットの下で、そのような結果がどのように得られたか、そして私が自分で書くことができるよりも優れたコードをコンピューターがどのように思いついたかを正確に説明します。
JITをオフにしたJava 6では約10%の加速が得られましたが、一見、これらの式が同等であることは明らかではありません(これはどこですか、それとも一般に合法ですか?!) カットの下で、そのような結果がどのように得られたか、そして私が自分で書くことができるよりも優れたコードをコンピューターがどのように思いついたかを正確に説明します。
とにかく最適化は行わず、いわゆる「ローカル」またはピープホール最適化を行うことにしました。 これは通常、現代の最適化コンパイラがプログラムを実行する最後のステップであり、実際には非常に簡単です。指定された小さな線形の命令シーケンスを検索し、それらの観点から最適な他の命令に変更します。 つまり、ここではmov eaxの悪名高い置換、 xor eax eax での0-これはまさにローカル最適化です。 ここで最も興味深いのは、これらの置換ルールが正確に構築されることです。 それらは、特別に訓練され、アセンブラーを認識している人が手動で作成するか、一連の指示を検索して作成できます。 明らかに、最初のオプションは非常に高価であり(特別に訓練された人はおそらく多額のお金を必要とするでしょう)、効果的ではありません(まあ、そのようなセットはどれくらい考えて提供できますか?)、そして2番目は長いです、特に長いシーケンスを整理しようとする場合。
これは、遺伝的アルゴリズムがシーンに入る場所であり、検索プロセスを大幅に削減できます。
遺伝的アルゴリズム自体についてはお話ししません。少なくとも一般的な意味で誰もがそれが何であるかを理解していることを願っています 。 私はそれらをどのように使用したかについてのみ説明します。
この場合の個人はコードフラグメントであり、クロス演算子とミューテーション演算子はそれらに含まれる命令を何らかの方法で変更する必要があり、フィットネス関数は最速のオプションを選択する必要があることは明らかです(実行速度を正確に最適化するため)。 しかし、これはどのように正確にクロスする必要がありますか?
コードフラグメントの交差と突然変異
私は、任意のフラグメントを非常に迅速に変更するという考えをあきらめました。 この場合、無効なコード、つまり単に実行できないコードを受け取る可能性が非常に高くなります。 私はターゲットアーキテクチャとしてJVMを選択しました(バイトコード自体とそれを操作する手段の両方のシンプルさのため、後でこれが最も成功したソリューションではないことに気づきました)、そしてそれは単にカーブコードのロードを許可しないかなり厳格なバリデーターを持っています(例:スタックを空にします)。 したがって、彼のフィットネス関数の値は計算できません。
そのため、私はかなり複雑なシステム、ほとんど一種のミニエミュレータJVMを構築する必要がありました。 各命令とそのシーケンスごとに、初期状態と最終状態が決定されました。 特定の値は計算されず、オペランドタイプのみが決定されました。 つまり、任意のコードフラグメントの実行の結果として、削除され、スタックに配置される値の数とタイプを常に伝えることができます。 次に、この情報に基づいて、指定されたセットを置き換えることができる別のセットが見つかりました(突然変異の場合は偶然作成され、交差の場合は2番目の個人で検索されました)、コードの正確さを維持するために、JVM状態の処理に関して同等である必要がありました-つまり、削除スタックから、まったく同じ数とタイプの値を戻します。
これは中間計算には適用されません。つまり、内部のフラグメントはスタックに対して何でも実行できますが、それ以降はまったく同じ状態を維持する必要があります。
例:
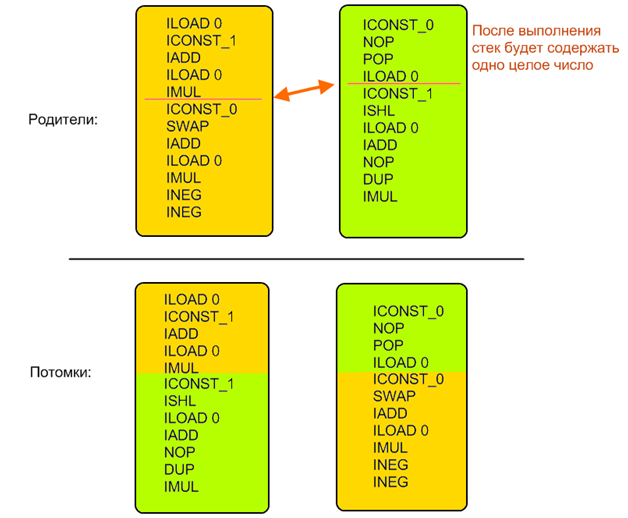
初期生成は同じルールに従って作成されました。元の命令シーケンスと同じ方法でJVMの状態を変更する必要がありました。 したがって、個人の正確さと比較可能性は常に維持されました。作業後のすべての個人は常に同じ状態(同じ順序でスタック上の同じタイプの値)のままなので、得られた結果と参照結果の類似性を比較するのは簡単でした:単純に計算するだけで十分でした各値が単一のレジスターまたはスタック要素である2つの多次元ベクトルの違い(原則的にアルゴリズムが適用されるため、Javaと非Javaの両方の用語を定期的に使用します 私はコンピューターを見ていますが、私自身がいくつかの目的でチェックしました。
フィットネス機能
個人から何が必要ですか? しかし、最初に同じ結果を考慮する必要があり、次に-元の結果よりも速く行う必要があります。 これを確認するには、それらを起動する必要があります。
個人の各ステップでVMの状態を既にカウントしています。 特に、これは必要な入力データのセットを提供します。つまり、すべてのレジスタが満たされる必要があり、すべてを正常に機能させるためにスタックに配置する要素の数と数です。 さて、このデータを作成するのと同じコードを各個人の先頭に追加し、最後に必要な場所に結果を記録します。 フィットネス関数の最終値は、結果ベクトル間の距離と、元のベクトルと比較した加速係数で構成されます。
研究の過程で、「前頭」の実装は人口の急速な退化につながり、それは非常に短い(そして非常に速い)個人で詰まり、有用なことは何もしません(つまり、例えばコンピューティングの代わりに、彼らは単に所望の深さまでスタックを空にします)長さと速度を犠牲にして勝ちます。 そのため、計算結果が基準に十分に近づいた後にのみ速度が考慮されるようにする必要がありました。
作業の速度と結果の同等性に加えて、個人の長さをさらに制御する必要がありました。 そのような制御がなければ、人口は十分に迅速に(約50世代で)個人の平均長、元のコードフラグメントの最大10-20の長さを伸ばし始めます。 そのような長い個体の出現は遺伝的プロセスを非常に遅くします。なぜなら、まず、正確性をチェックするために必要なコードの分析に必要な時間が増加し(各反復の時間が長くなる)、そして第二に、解決策を得るために、個体内の多数の不必要な指示を取り除く必要があるためですかなりの数の世代(反復の総数が増えています)。
この作業では、命令セットのサイズではなく、実行速度の最適化を検証するため、長さの要因は、長すぎる候補をドロップアウトするためにのみ使用され、フィットネス関数が計算される対象が元の個体よりも長い場合にのみ式に適用されます。
フィットネス関数の最終形式:
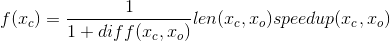
ここで、 Xcはテスト対象の個人、 Xoは元のフラグメント、 diffは結果ベクトルの差、 lenは比率が長い、 speedupは実行時間の比率です。
diffが一定の定数よりも大きい場合、 スピードアップは 1に等しくなります。つまり、ほぼ正しい値を考慮する個人に対してのみスピードが考慮され始めます。
この関数に次のプロパティがあることを簡単に確認できます。
- 最初のランダムコードフラグメントではゼロに近い(結果の差が大きい)
- 計算結果が参照と収束するにつれて、1に近づきます
- これは、ソースフラグメントの場合と同じです。
- 大きなユニットのフィットネス機能を備えたすべてのオプションは、アルゴリズムの潜在的な結果です。これらは、必要なものを考慮し、同時により速く/より短くする個人です
検証
アルゴリズムの過程で、各個人は、数十のテストケースで元のフラグメントを提供することにより、結果のコンプライアンスをチェックしました。 これは迅速でかなり効果的なテストですが、取得した最適化されたシーケンスと元のシーケンスが同等であることを厳密に証明するには明らかに不十分です。 そのような証拠を得るために、正式な検証が使用されました。
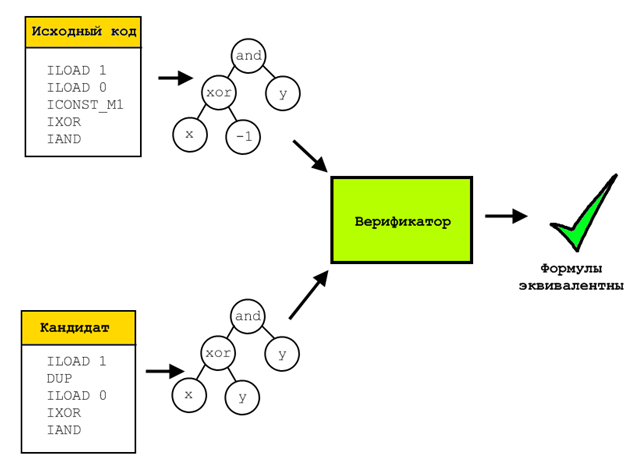
このため、検証された個人と初期の個人のために、すべての操作は記号形式で提示されました。つまり、スタックの各レジスタ/セルの特別なエミュレーターを実行した後、計算されて数式に書き込まれた数式の記号表現がありました。 次に、Z3 SMT式ソルバーを使用して、これらすべての式を比較しました。 このようなソルバーは、2つのテスト式が異なる結果を与える入力パラメーターのセットがないことを証明できます。 そのようなセットが存在する場合、構築されて表示されます。
検証はかなり長いプロセスであるため(1人の個人と1組の単純な数式で数十分かかる場合があります)、最終的なソリューションの候補のみ、つまり1より大きいフィットネス関数を持つ個人にさらされました。
ただし、研究中に、テストデータセットですべてを正確に計算し、検証段階で除外される単一の候補者に会ったわけではないことに注意してください。
例
遺伝的アルゴリズムは、他の機械学習業界と同様に、プログラマーに定期的に頭を握らせ、「どうやって、どうやってやったの?」と叫ぶことを強制する驚くべきことでしょう。 私の場合、私の助けを借りて、コンピューターはプログラムを何らかの未知の方法で実際に改善し、私がすぐには考えられないようなものを思いついたという事実によって、海賊行為が追加されました。
一般的に、私は時々これと同様の漫画のヒーローのように感じました:

さて、私たちは個人を十字架とエミュレーションで駆り立て、結果の同等性を検証し、何を得たのでしょうか? 私が見つけた最適化の例をいくつか挙げましょう。
折りたたみ定数およびその他の標準的なもの
第一に、このアルゴリズムは、未使用の計算の削除や定数の折りたたみなど、合成テストであらゆる種類の標準的なものを見つけるのに非常に優れていますが、このために明確にしたわけではありません。 たとえば、彼はすぐにx + 1-2をx-1に減らすことができることに気付きました。
それは:
ILOAD 0 ICONST_1 IADD ICONST_2 ICONST_M1 IMUL IADD
次のようになりました:
ILOAD 0 ICONST_1 ISUB
他のすべての例は実際のコードから取られ、コンパイルされたクラスを解析し、最適化に適したシーケンスを探した特別なツールが作成されました(つまり、ブランチやサポートされていない命令なし)。
数式の簡素化と括弧の外への配置
記事の冒頭の例は、11命令から9命令に削減されました。
。 一見、式は一般的に正しくありません。それを受け取ったので、急いでエミュレータコードのエラーを探しました。 ただし、式(x + 1)xは常に偶数で負でないため、つまり、最下位ビットは常にゼロであり、この場合、ユニティへの追加はxorと同等ですが、一部の部分で動作するようです。より速く。 真実はJITが存在しない場合のみです。JITを有効にすると、期待される((x + 1)x + 1)xが最初に出力されます。 OR(またはXOR)を使用したオプションがより高速に機能した理由はわかりませんが、この結果はJavaの異なるバージョンや異なるコンピューターを含め、定期的に再現されました
一般に、Javaの場合、JITは多くの頭痛の種をもたらし、私はこのプラットフォームの選択を後悔しました。 100パーセント確信することは決してできませんでした。速度を向上させたのはあなたの最適化でした。 もちろん、 パフォーマンスを評価するための誤ったマイクロテストの構造など、あらゆる種類の有用な記事を調べましたが、それでもかなり悪くなりました。 非常に迷惑なのは、開始回数に応じてコードが一貫して改善されることです。 フラグメントを100回開始しました-インタープリターモードで動作し、1つの結果を生成し、1000を起動しました-JITを有効にしてネイティブコードに変換しましたが、特に最適化せずに1万を起動しました-JITはこのネイティブコードで何かを選択し始め、その結果、実行速度が変化しました桁とこれすべてを考慮する必要があります。
論理演算子
ただし、一部の場所では、JITをスキップすることさえできました。 たとえば、式(x XOR -1)AND yこの最適な最適化は!Xおよびyであり、これはC ++コンパイラが生成するものです。 ただし、Javaバイトコードにはビット単位の単一オペランド操作がないため、 (x XOR y)AND yが最適なオプションです。 同時に、JITはそのようなことすら考えていません(サーバーJVM 1.6でデバッグ出力をオンにすることで確認されました)。これにより、少し速度を上げることができます。
トリッキーな左シフト機能
シフト演算子には別の面白い結果がありました。 BigIntegerの腸のどこかで、式1 <<(x&31)が見つかりました 。この最適化されたバージョンは、アルゴリズムが1 << xを生成しました。
繰り返しになりますが、頭をつかんでバグを探します-アルゴリズムが重要なコード全体を受け取って破棄したことは明らかです。 特に演算子の仕様を詳細に検討するまで、演算子<<は2番目のオペランドの最下位5ビットのみを使用することが判明しました。 したがって、明示的な&31は一般的に必要ありません、オペレータはあなたのためにそれを行います(私が理解するように、ライブラリクラスのバイトコードでは、このチップは最初のJavaには現れなかったため、古いバージョンとの互換性のために強制されます。
問題と結論
結果を受け取った後、私は次に何をすべきかを考え始めました。 そして、ここでは何も起きませんでした。 Javaの場合、私の最適化は小さすぎて目立たないため、プログラム全体の速度に大きな影響を与えることはできません。いずれにしても、これらすべてをテストできるプログラムについては(いくつかの高度な科学計算は、いくつかの命令を置き換えて、 1メジャーの時間(数ナノ秒)。 さらに、Javaマシン、仮想性、およびJITの構造によって、その効果が大幅に消費されます。
他のアーキテクチャに切り替えてみました。 最初はx86で最初の作業バージョンを受け取りましたが、アセンブラーは複雑すぎて、検証に必要なコードを書くことができませんでした。 その後、私はゲーム開発者として働いていたため、シェーダーの方向に固執しようとし、ピクセルシェーダーアセンブラーのサポートを追加しました。 しかし、そこには、一連の命令の良い例を含む適切なシェーダーが見つかりませんでした。
一般的に、私はこのビジネスをどこに結びつけるか考えていませんでした。 コンピューターがあなたより賢く、その最適化を見つけて、それがどのように機能するかをすぐに理解することさえできないときの感覚は、長い間覚えています。