目的
「悪い」音楽と「良い」音楽を区別するようにニューラルネットワークを教えるか、ニューラルネットワークではこれが不可能であることを示します(この特定の実装)。

ステージ1:データの正規化
音楽は数え切れないほどの数の音の組み合わせであるため、そのようにニューラルネットワークを「フィード」することは不可能であるため、どのネットワークを「リッスン」するかを決定する必要があります。 音楽の「最も重要な」機能を強調するためのオプションは無限です。 音楽と区別する必要があるものを決定する必要があります。 参考データとして、音楽で使用される音の周波数についてのいくつかのアイデアを強調する必要があると判断しました。
周波数を選択することにしました まず、 楽器ごとに異なります 。

第二に、周波数に依存する聴覚の感度は異なり 、かなり個人的なものです(合理的な制限内)。
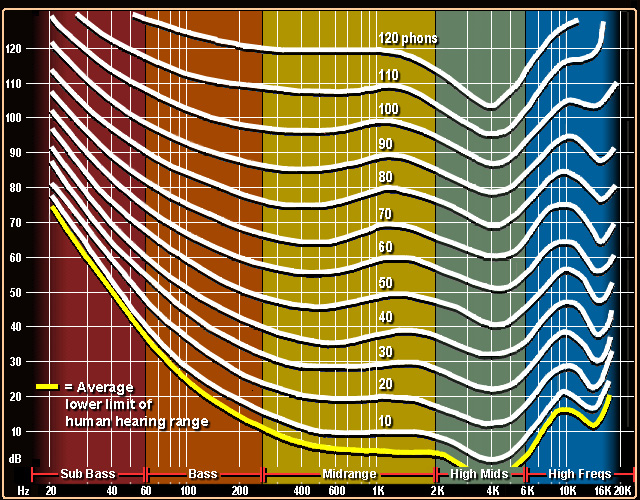
第三に、特定の周波数のトラックの彩度は非常に個別ですが、同時に、同様の構成でも同様です。たとえば、2つの異なるトラックのギターソロは、個々の周波数のレベルでトラックの「彩度」の同様の画像を提供します。
したがって、正規化タスクは、周波数に関するいくつかの情報の割り当てに限定されます。
- 特定の周波数範囲の音がコンポジションでどれくらいの頻度で聞こえるか
- 彼はどれほどうるさかった
- 彼はどのくらい鳴りましたか
- 特定の周波数範囲ごとに(「可聴」スペクトル全体を特定の範囲に分割する必要があります)。
各時間間隔でトラックの周波数飽和度を選択するには、 FFTデータを使用できます。必要に応じてこのデータを手動で計算できますが、既製のBassオープンライブラリ、より正確にはBass.NETシェルを使用して、このデータをより人道的に取得できます。
トラックからFFTデータを取得するには、小さな関数を記述します 。
生データを受信した後、それらを処理する必要があります。

データの可視化
まず、目的のサウンドを分割する周波数範囲の数を決定する必要があります。このパラメーターは分析結果の詳細度を決定しますが、ニューラルネットワークに多くの負荷を与えます(ビッグデータを操作するにはニューロンがさらに必要になります)。 このタスクでは、1024階調を使用します。これはかなり詳細な周波数のスペクトルであり、出力では比較的少量の情報です。 ここで、必要なすべての情報を含むfloat []のN個の配列から1つの配列を取得する方法を決定する必要があります。特定のスペクトルによる音の飽和、音のさまざまなスペクトルの発生頻度、音量、持続時間。
最初のパラメーター「サチュレーション」では、すべてが非常に単純で、すべての配列を単純に合計することができ、出力では、トラック全体の各スペクトルがどれだけ「多く」あったかがわかりますが、これは他のパラメーターを反映しません。
他のパラメータも「反映」するために、他のパラメータをもう少し複雑に要約することができます。そのような「加算」機能の実装の詳細には触れません。 可能な実装の数は事実上無限です。
結果の配列のグラフィカル表現:
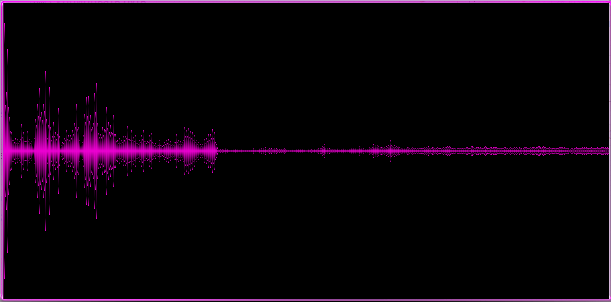
例1.軽いロック、ピアノ、ボーカルの要素を備えた比較的穏やかなメロディー
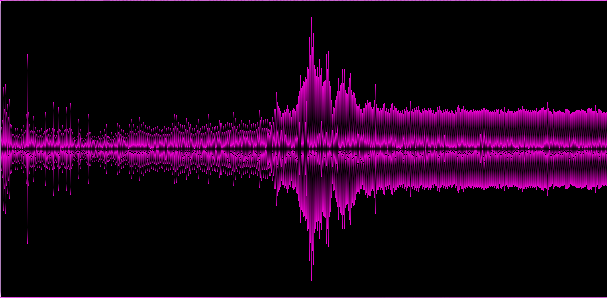
例2.あまり柔らかくないダブステップの
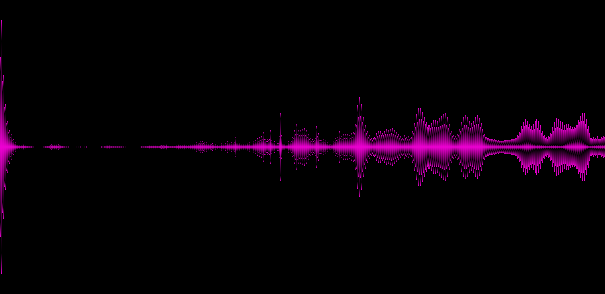
例3. トランスに近いスタイルの音楽
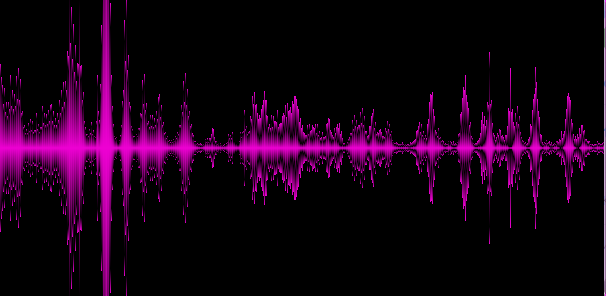
例4. ピンクフロイド
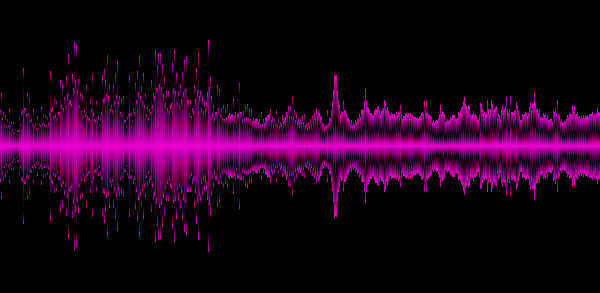
例5. ヴァン・ヘイレン
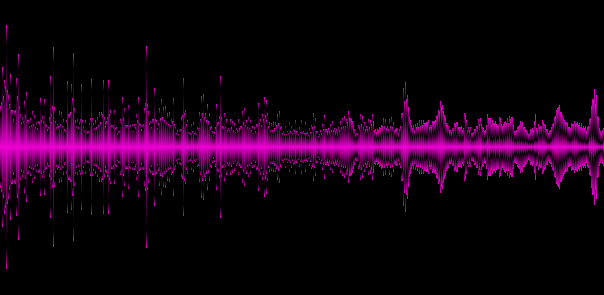
例6.ロシアの国歌
上記の例は、さまざまなジャンルが異なる「スペクトル写真」を提供することを示しています。これは良いことなので、トラックの少なくともいくつかの重要な特徴を特定しました。
次に、ニューラルネットワークを準備する必要があります。これを「トレーニング」します。 多くのニューラルネットワークアルゴリズムがあり、特定のタスクに適したものもあれば、悪いものもあります。タスクのコンテキストですべてのタイプを研究する目標を設定せず、問題の解決に適応するのに十分な柔軟性を備えた最初の実装 ( dr.kernelのおかげ)を採用します。 「より適切な」ニューラルネットワークを選択しません。 タスクは「ニューラルネットワーク」をチェックすることであり、そのランダムな実装が良好な結果を示した場合、結果をさらに良く表示するより適切なタイプのニューラルネットワークが間違いなくあり、ネットワークに障害が発生した場合、このニューラルネットワークが対処しなかったことのみを示します
このニューラルネットワークは、0〜1の範囲にあるデータでトレーニングされ、出力では0〜1の値も与えます。したがって、データは「適切な形式」にする必要があります。 さまざまな方法でデータを適切な形式にすることができますが、結果は同様です。
ステージ2:ニューラルネットワークの準備
私が使用するニューラルネットワークは、層の数、入力、出力の数、および各層のニューロンの数によって決まります。
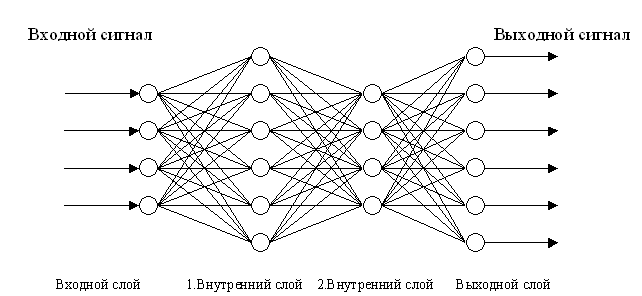
明らかに、すべての構成が「同等に役立つ」わけではありませんが、このタスクに「最適な」構成を決定するための方法があれば、それがわかりません。 いくつかの異なる構成を試して、「より適切な」構成に焦点を当てることができますが、私は逆に、進化アルゴリズムを使用してニューラルネットワークを成長させます。
この時点で、入力データの形式が定義されています。出力データの形式を決定する必要があります。 明らかに、単に「良い」と「悪い」にトラックを分割することができ、1つの出力ニューロンで十分ですが、良い概念と悪い概念は拡張可能であると思います。特に、特定の音楽は朝に目覚めるのに適しています。仕事の後の夕方の休憩など つまり、トラックの品質は、時刻と曜日(合計24 * 7の出力ニューロン)に対しても決定する必要があります。
トレーニングのサンプルを決定する必要があります。これは、もちろん、すべてのトラックを取り、座って、いつ聴きたいか、または聞きたくないことを覚えておくことができますが、私は何時間も座ってトラックをマークする人ではありません、「途中で」それを行うのははるかに簡単ですつまり、トラックを聴きながら。 つまり、トラックが「良い」または「悪い」とマークされる可能性のあるトラックを聴きながら、「トレーニング」サンプルをプレイヤーが作成する必要があります。 そして、そのようなプレーヤーが存在することを想像してください(実際には、つまり、他のプレーヤーのオープンソースコードに基づいて記述されています)。 さまざまな日に10時間音楽を聴いた後、最初のサンプルのデータが収集されます。 各サンプル要素には、入力データ(トラックのスペクトル画像の1024値)と出力(0から1までの24 * 7の値が含まれます。0は本当に悪いトラックで、1は週7日の1時間ごとに非常に良いトラックです)。 同時に、「良い」トラック+はすべての曜日と時間に設定されていましたが、この時間\曜日+は大きく、「悪い」の場合も同様です。つまり、データは0と1ではありませんが、一部の値は0と1の間です。
トレーニング用のデータがあります。今、トレーニング済みのネットワークを考慮するものを決定する必要があります。この場合、そこにロードされたデータについて、入力データに対するネットワーク応答の差は最小ではなく、初期出力データであると仮定できます。 未知のデータからネットワークを「予測」する能力も非常に重要です。つまり、再トレーニングするべきではなく、ネットワークの再トレーニングにはほとんど意味がありません。 「応答品質」を決定するのに問題はありません。これには、エラーを計算する関数があるため、予測の品質をどのように決定するかという疑問が残ります。 この問題を解決するには、1つのサンプルでネットワークをトレーニングするだけで十分ですが、別のサンプルで品質を確認します。サンプルはランダムで、最初と2番目の要素は繰り返さないでください。
ネットワーク学習のレベルをチェックするアルゴリズムが見つかったので、構成を決定する必要があります。 先ほど言ったように、これには進化的アルゴリズムが使用されます。 これを行うには、それぞれが100個のニューロンを持つ10個のレイヤー(これは間違いなく小さく、そのようなネットワークの品質はあまり良くありません)などの初期設定を行い、トレーニングの品質を決定した後、特定のステップ数(たとえば1000)でトレーニングします。 次に、「進化」に進み、10個の構成を作成します。各構成は元の「変異体」です。つまり、各層または一部の層の層数またはニューロン数がランダムに変更されています。 次に、各構成を元の構成と同じ方法でトレーニングし、最適な構成を選択して、元の構成として定義します。 このプロセスは、オリジナルよりも学習しやすい構成が見つからない瞬間が来るまで続けます。 この構成を最適と見なし、初期データを「記憶」し、何よりも最良を予測できることが判明しました。つまり、トレーニングの結果は可能な限り最高の品質です。
進化プロセスは、サイズが6000の要素のサンプルに対して約6時間かかり、数時間の最適化の後、プロセスは約30分かかり、構成は異なるサンプルで異なる場合がありますが、ほとんどの場合、構成は約7層で、ニューロンの数は徐々に3-4層に増加し、さらに、最後の層、つまり7層のうち3層から4層へのハンプのように、より迅速に縮小します。明らかに、この構成は特定のネットワークで最も「対応」しています。
そのため、ネットワークは「成長」し、学習することができます。ネットワークの通常の学習は長く退屈です(最大15分)。その後、ネットワークは「音楽を聴く」と「悪い」または「良い」と言う準備ができます。
ステージ3:結果の収集
「脳」の重み-訓練されたネットワークの構成は25 mbで、重みはサンプルごとに異なります。一般に、サンプルが大きいほど、処理に必要なニューロンが多くなりますが、平均的なネットワークの重みはほぼ同じです。

私の謙虚な意見では、トレーニングサンプルはVan Halen、Pink Floyd、クラシック音楽(いずれでもない)、ソフトロック、メロディックで落ち着いたトラックなどの「良い」トラックで構成されていました。 私の意見では、サンプルの「悪い」はラップ、ポップ、ハードロックと見なされていました。
トレーニング後にニューラルネットワークが計算するランダムトラックの「品質指標」を定義します。
- ヴァン・ヘイレン-29ポイント
- Rammstein-Mutter(アルバム)-20-23ポイント
- リアーナ-26ポイント
- パニッシャー-11-17ポイント
- ラジオラマ-25ポイント
- Rクラウダーマン-25-29ポイント
- グレゴリアン-27-29ポイント
- ピンクフロイド-29-33ポイント
- 低品質のロシアのラップ-9〜11ポイント
- 赤カビ16-19ポイント
- Bi-2 24-29ポイント
- うるう年-25〜33ポイント
結論:
「進化的」構成とトレーニングの後に登場した最初のニューラルネットワークは、トラックの特性を決定する「スキル」の存在を示しました。 ニューラルネットワークは、「音楽を聴く」ことと、それを教えた「リスナー」が好むまたは嫌うトラックを分離するように教えることができます。
C# のアプリケーションの完全なソースコードとコンパイルされたバージョンは、GitHubまたはSync経由でダウンロードできます。
記事に記載されているすべての機能を実装するアプリケーションの外観 :
この研究での私の経験が、ニューラルネットワークの機能を探求したい人々の将来に役立つことを願っています。