注:この記事は、ソフトウェアまたはハードウェア製品の広告または反広告ではなく、著者の個人的な経験のみを説明しています。
開発者のクイックスタートガイドからの知恵
実際、コプロセッサーはPCI-eスロットにインストールされた別個のハードウェアです。 GPUとは異なり、コプロセッサには独自のLinuxライクなマイクロOS、いわゆるカードOSまたはuOSがあります。 Xeon Phiコードを実行するための2つのオプションがあります。
- –mmicフラグを使用して、MICアーキテクチャのネイティブコードをコンパイルします。
- オフロードを介してコードを実行します。 この場合、コンパイルされたコードの一部はホスト(コプロセッサーを含むコンピューター)で起動され、一部はデバイス(以降、コプロセッサーを単にデバイスと呼びます)で起動されます。
もう1つの重要なポイントは、OpenMPを使用して、デバイス内のスレッド間で作業を分散できることです。それが私たちの仕事です。 まず、CPUに単純なアルゴリズムを実装し、次にコプロセッサーで動作するようにプログラムをやり直します。
テストタスクの説明
テスト例として、 n体の問題を選択しました。N個の体があり、その相互作用は特定のペアポテンシャルによって記述されるため、しばらくして各体の位置を決定する必要があります。
ペアワイズ相互作用の可能性と強度(この場合、プロセスの物理学にはほとんど関心がないため、任意の関数を使用できます):
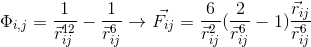
アルゴリズムは簡単です:
- ボディの初期座標と速度を設定します。
- 他の身体から各身体に作用する力を計算します。
- 体の新しい座標を決定します。
- 目的の結果が得られるまで、手順2と3を繰り返します。
明らかに、最も「難しい」段階は力の計算です。これは、N 2回の操作を実行する必要があるためです。また、各時間ステップで(もちろん、隣人のリストのようなトリックを使用し、ニュートンの第3則別の物語)。
このようなアルゴリズムのシリアルコードは非常にシンプルで、OpenMPディレクティブを使用して簡単にパラレルに変換できます。
OpenMPを使用した並列コード
/*---------------------------------------------------------*/ /* N-Body simulation benchmark */ /* written by MSOzhgibesov */ /* 04 July 2015 */ /*---------------------------------------------------------*/ #include <stdio.h> #include <stdlib.h> #include <math.h> #include <string.h> #include <time.h> #include <omp.h> #define HOSTLEN 50 int numProc; // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI); // Forces acting on each body void forces(float *rA, float *fA, int nBod); // Calculate velocities and update coordinates void integration(float *rA, float *vA, float *fA, int nBod); int main(int argc, const char * argv[]) { int const nI = 32; // Number of bodies in X, Y and Z directions int const nBod = nI*nI*nI; // Total Number of bodies int const maxIter = 20; // Total number of iterations (time steps) float const initDist = 1.0; // Initial distance between the bodies float *rA; // Coordinates float *vA; // Velocities float *fA; // Forces int iter; double startTime0, endTime0; char host[HOSTLEN]; rA = (float*)malloc(3*nBod*sizeof(float)); fA = (float*)malloc(3*nBod*sizeof(float)); vA = (float*)malloc(3*nBod*sizeof(float)); gethostname(host, HOSTLEN); printf("Host name: %s\n", host); numProc = omp_get_num_procs(); printf("Available number of processors: %d\n", numProc); // Setup initial conditions initCoord(rA, vA, fA, initDist, nBod, nI); startTime0 = omp_get_wtime(); // Main loop for ( iter = 0; iter < maxIter; iter++ ) { forces(rA, fA, nBod); integration(rA, vA, fA, nBod); } endTime0 = omp_get_wtime(); printf("\nTotal time = %10.4f [sec]\n", endTime0 - startTime0); free(rA); free(vA); free(fA); return 0; } // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI) { int i, j, k; float Xi, Yi, Zi; float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- int ii = 0; memset(fA, 0.0, 3*nBod*sizeof(float)); memset(vA, 0.0, 3*nBod*sizeof(float)); for (i = 0; i < nI; i++) { Xi = i*initDist; for (j = 0; j < nI; j++) { Yi = j*initDist; for (k = 0; k < nI; k++) { Zi = k*initDist; rAx[ii] = Xi; rAy[ii] = Yi; rAz[ii] = Zi; ii++; } } } } // Forces acting on each body void forces(float *rA, float *fA, int nBod) { int i, j; float Xi, Yi, Zi; float Xij, Yij, Zij; // X[j] - X[i] and so on float Rij2; // Xij^2+Yij^2+Zij^2 float invRij2, invRij6; // 1/rij^2; 1/rij^6 float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- float *fAx = &fA[ 0]; //---- float *fAy = &fA[ nBod]; // Pointers on X, Y, Z components of forces float *fAz = &fA[2*nBod]; //---- float magForce; // Force magnitude float const EPS = 1.E-10; // Small value to prevent 0/0 if i==j #pragma omp parallel for num_threads(numProc) private(Xi, Yi, Zi, \ Xij, Yij, Zij, magForce, invRij2, invRij6, j) for (i = 0; i < nBod; i++) { Xi = rAx[i]; Yi = rAy[i]; Zi = rAz[i]; fAx[i] = 0.0; fAy[i] = 0.0; fAz[i] = 0.0; for (j = 0; j < nBod; j++) { Xij = rAx[j] - Xi; Yij = rAy[j] - Yi; Zij = rAz[j] - Zi; Rij2 = Xij*Xij + Yij*Yij + Zij*Zij; invRij2 = Rij2/((Rij2 + EPS)*(Rij2 + EPS)); invRij6 = invRij2*invRij2*invRij2; magForce = 6.0*invRij2*(2.0*invRij6 - 1.0)*invRij6; fAx[i]+= Xij*magForce; fAy[i]+= Yij*magForce; fAz[i]+= Zij*magForce; } } } // Integration of coordinates an velocities void integration(float *rA, float *vA, float *fA, int nBod) { int i; float const dt = 0.01; // Time step float const mass = 1.0; // mass of a body float const mdthalf = dt*0.5/mass; float *rAx = &rA[ 0]; float *rAy = &rA[ nBod]; float *rAz = &rA[2*nBod]; float *vAx = &vA[ 0]; float *vAy = &vA[ nBod]; float *vAz = &vA[2*nBod]; float *fAx = &fA[ 0]; float *fAy = &fA[ nBod]; float *fAz = &fA[2*nBod]; #pragma omp parallel for num_threads(numProc) for (i = 0; i < nBod; i++) { rAx[i]+= (vAx[i] + fAx[i]*mdthalf)*dt; rAy[i]+= (vAy[i] + fAy[i]*mdthalf)*dt; rAz[i]+= (vAz[i] + fAz[i]*mdthalf)*dt; vAx[i]+= fAx[i]*dt; vAy[i]+= fAy[i]*dt; vAz[i]+= fAz[i]*dt; } }
「ロード」コプロセッサー
最初のプログラムを検討してください。 最初に、デバイスの名前と使用可能なプロセッサーの数を調べます。 次の図では、ホスト(上図)とデバイス(下図)のコードの違いがはっきりとわかります。

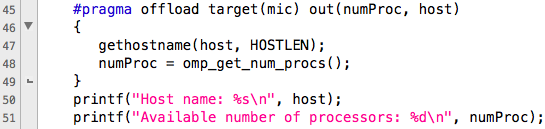
下の図は、コードをデバイスにオフロードするために、ディレクティブ#pragma offloadが使用され、マイク(デバイス)がアンロードのターゲットとして示されていることを示しています。 システムに複数のコプロセッサーがある場合、デバイス番号を指定する必要があります。 例:
#pragma offload target (mic:1)
目的が示された後、アンロードパラメータは次のとおりです。
- in-変数は排他的に入力されます。つまり、コードが完了した後、変数の値はホストにコピーされません。
- out-変数は結果のみです。つまり、ページセクションの開始前は、変数の値はホストからコピーされません。
- inout-アップロードされたコードを開始する前に、すべての変数がデバイスにコピーされ、完了後にホストにコピーされます。
- nocopy-変数はどこにもコピーされません。 既に初期化された変数を再利用するために使用されます。
オフロードの詳細な説明はこちらです。
この場合、変数numProcとhostはホスト上でのみ宣言されますが、初期化されないため、コピーを使用します(もちろんinoutもできますが、順序は崩しません)。
結果のコードをコンパイルして実行できます-特別なコンパイルフラグは必要ありません。 この場合、デバイスは値numProcを返すことでスレッドの数を決定しますが、計算はホストで実行されますが、プロシージャをアンロードしていないためです。
最初の手順は初期条件を設定します。N個の操作の順序が必要で、1回だけ呼び出されるため、ホストに残します。
次に、時間サイクルが始まります。各ステップで相互作用力を計算し、運動方程式を積分する必要があります。 後者の手順では、初期条件と同様に、N個の操作の順序が必要であり、ホスト上に残すことも論理的に思えますが、これには、すべてのステップでアレイを強制的にコピーすることが必要です。 明らかに、システムのサイズが大きい場合、ほとんどの時間はアレイを前後にドラッグすることに費やされます。 したがって、すべてのソースデータをデバイスにダウンロードし、必要な反復回数を実行して、結果をホストにアップロードする必要があります。 このアプローチは、GPUの並列化でも使用されます。
startTime0 = omp_get_wtime(); // Main loop #pragma offload target(mic) inout(rA, fA, vA:length(3*nBod)) in(nBod) for ( iter = 0; iter < maxIter; iter++ ) { forces(rA, fA, nBod); integration(rA, vA, fA, nBod); } endTime0 = omp_get_wtime();
配列の名前に加えて、サイズも指定する必要があります。 したがって、サイクルはデバイスに完全にロードされて実行され、その後、結果がコピーされます。 デバイスで実行されるルーチンには、適切な属性を指定する必要があることに注意してください。
// Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI); // Forces acting on each body __attribute__ ((target(mic))) void forces(float *rA, float *fA, int nBod); // Calculate velocities and update coordinates __attribute__ ((target(mic))) void integration(float *rA, float *vA, float *fA, int nBod);
それだけです。IntelXeon Phiの最初のプログラムは準備が整っており、機能します。 プログラムを起動するとき、誰がどこでコピーするか(ホストとデバイスの間)を正確に知ることが役立つ場合があります。 これは、環境変数OFFLOAD_REPORTを使用して実行できます。 例( 詳細 ):
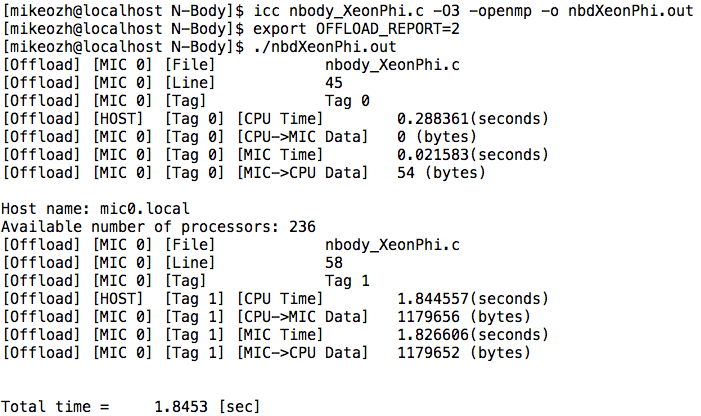
最初のアンロードでは、デバイスには何もコピーされませんでしたが、デバイスから54バイトが受信されました(名前と整数を含む文字列-プロセッサの数)。 2番目のケース(2番目のアップロード)では、nBod変数の値がコピーされていないため、送信されたサイズより4バイト少ないサイズが受信されました。
24個のホストスレッド(2つのIntel Xeon E5-2680v3プロセッサ)でのコードランタイム:5.9832秒

236デバイススレッド(Intel Xeon Phi 5110P)でのコード実行時間:1.8667秒
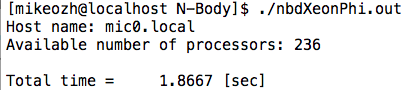
合計で、2行のコードでパフォーマンスが約3倍向上しました-非常に良いことです。 ハイブリッドコンピューティングのオプションも検討できることに注意してください-問題の一部はホストで、一部はデバイスで解決されますが、座標を同期するためにホストとデバイス間のデータ交換を回避する方法はありません。
Xeon Phiのフルバージョンコード
/*---------------------------------------------------------*/ /* N-Body simulation benchmark */ /* written by MSOzhgibesov */ /* 04 July 2015 */ /*---------------------------------------------------------*/ #include <stdio.h> #include <stdlib.h> #include <math.h> #include <string.h> #include <time.h> #include <omp.h> #include <unistd.h> #define HOSTLEN 50 __attribute__ ((target(mic))) int numProc; // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI); // Forces acting on each body __attribute__ ((target(mic))) void forces(float *rA, float *fA, int nBod); // Calculate velocities and update coordinates __attribute__ ((target(mic))) void integration(float *rA, float *vA, float *fA, int nBod); int main(int argc, const char * argv[]) { int const nI = 32; // Number of bodies in X, Y and Z directions int const nBod = nI*nI*nI; // Total Number of bodies int const maxIter = 20; // Total number of iterations (time steps) float const initDist = 1.0; // Initial distance between the bodies float *rA; // Coordinates float *vA; // Velocities float *fA; // Forces int iter; double startTime0, endTime0; double startTime1, endTime1; char host[HOSTLEN]; rA = (float*)malloc(3*nBod*sizeof(float)); fA = (float*)malloc(3*nBod*sizeof(float)); vA = (float*)malloc(3*nBod*sizeof(float)); #pragma offload target(mic) out(numProc, host) { gethostname(host, HOSTLEN); numProc = omp_get_num_procs(); } printf("Host name: %s\n", host); printf("Available number of processors: %d\n", numProc); // Setup initial conditions initCoord(rA, vA, fA, initDist, nBod, nI); startTime0 = omp_get_wtime(); // Main loop #pragma offload target(mic) inout(rA, fA, vA:length(3*nBod)) in(nBod) for ( iter = 0; iter < maxIter; iter++ ) { forces(rA, fA, nBod); integration(rA, vA, fA, nBod); } endTime0 = omp_get_wtime(); printf("\nTotal time = %10.4f [sec]\n", endTime0 - startTime0); free(rA); free(vA); free(fA); return 0; } // Initial conditions void initCoord(float *rA, float *vA, float *fA, \ float initDist, int nBod, int nI) { int i, j, k; float Xi, Yi, Zi; float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- int ii = 0; memset(fA, 0.0, 3*nBod*sizeof(float)); memset(vA, 0.0, 3*nBod*sizeof(float)); for (i = 0; i < nI; i++) { Xi = i*initDist; for (j = 0; j < nI; j++) { Yi = j*initDist; for (k = 0; k < nI; k++) { Zi = k*initDist; rAx[ii] = Xi; rAy[ii] = Yi; rAz[ii] = Zi; ii++; } } } } // Forces acting on each body __attribute__ ((target(mic))) void forces(float *rA, float *fA, int nBod) { int i, j; float Xi, Yi, Zi; float Xij, Yij, Zij; // X[j] - X[i] and so on float Rij2; // Xij^2+Yij^2+Zij^2 float invRij2, invRij6; // 1/rij^2; 1/rij^6 float *rAx = &rA[ 0]; //---- float *rAy = &rA[ nBod]; // Pointers on X, Y, Z components of coordinates float *rAz = &rA[2*nBod]; //---- float *fAx = &fA[ 0]; //---- float *fAy = &fA[ nBod]; // Pointers on X, Y, Z components of forces float *fAz = &fA[2*nBod]; //---- float magForce; // Force magnitude float const EPS = 1.E-10; // Small value to prevent 0/0 if i==j #pragma omp parallel for num_threads(numProc) private(Xi, Yi, Zi, \ Xij, Yij, Zij, magForce, invRij2, invRij6, j) for (i = 0; i < nBod; i++) { Xi = rAx[i]; Yi = rAy[i]; Zi = rAz[i]; fAx[i] = 0.0; fAy[i] = 0.0; fAz[i] = 0.0; for (j = 0; j < nBod; j++) { Xij = rAx[j] - Xi; Yij = rAy[j] - Yi; Zij = rAz[j] - Zi; Rij2 = Xij*Xij + Yij*Yij + Zij*Zij; invRij2 = Rij2/((Rij2 + EPS)*(Rij2 + EPS)); invRij6 = invRij2*invRij2*invRij2; magForce = 6.0*invRij2*(2.0*invRij6 - 1.0)*invRij6; fAx[i]+= Xij*magForce; fAy[i]+= Yij*magForce; fAz[i]+= Zij*magForce; } } } // Integration of coordinates an velocities __attribute__ ((target(mic))) void integration(float *rA, float *vA, float *fA, int nBod) { int i; float const dt = 0.01; // Time step float const mass = 1.0; // mass of a body float const mdthalf = dt*0.5/mass; float *rAx = &rA[ 0]; float *rAy = &rA[ nBod]; float *rAz = &rA[2*nBod]; float *vAx = &vA[ 0]; float *vAy = &vA[ nBod]; float *vAz = &vA[2*nBod]; float *fAx = &fA[ 0]; float *fAy = &fA[ nBod]; float *fAz = &fA[2*nBod]; #pragma omp parallel for num_threads(numProc) for (i = 0; i < nBod; i++) { rAx[i]+= (vAx[i] + fAx[i]*mdthalf)*dt; rAy[i]+= (vAy[i] + fAy[i]*mdthalf)*dt; rAz[i]+= (vAz[i] + fAz[i]*mdthalf)*dt; vAx[i]+= fAx[i]*dt; vAy[i]+= fAy[i]*dt; vAz[i]+= fAz[i]*dt; } }
おわりに
GPUとXeon Phiのプログラミングの唯一の類似点は、ホストとデバイス間でデータを移動する必要があることです。これは、実際にはCPU専用のOpenMPを使用することとは異なります。 ネイティブコンパイラは、ホストだけでなくデバイスに対してもコードを自動的にベクトル化できるため、細部にこだわることなく適切なパフォーマンスを得ることができます。
私の意見では、OpenMPで動作する既製のコードがあり、パフォーマンスを向上させる必要がある場合、Xeon Phiは非常に適していますが、GPU用に書き換える欲求/能力はありません。 科学コミュニティの人々が確実に好む重要なポイントは、Fortranのサポートです。
便利なリンク
www.prace-ri.eu/best-practice-guide-intel-xeon-phi-html
www.ichec.ie/infrastructure/xeonphi
www.cism.ucl.ac.be/XeonPhi.pdf
hpc-education.unn.ru/files/courses/XeonPhi/Lection03.pdf