もちろん、このテストは完全であるとは言えません。読み取りだけが関係し、それは線形であるためです。 しかし、結果はすでに特定のケースでのbtrfsへの可能な移行について考えさせます。
しかし、主な目標は、それがいかに合理的であるか、そしてファイルシステムレベルでの透過的な圧縮アプローチが隠しうる落とし穴についてのコミュニティの意見を見つけることです。
時間を無駄にしたくない人のために、すぐに調査結果についてお話しします。 compress = lzoオプションを使用してbtrfsでホストされるPostgreSQLデータベースは、データベースのサイズを2つに縮小し(圧縮なしのFSと比較して)、マルチスレッドシーケンシャルリードを使用すると、ディスクサブシステムの負荷を大幅に削減します。
在庫は何ですか
物理サーバー-1台
- CPU:6コアの2ソケット
- RAM:48 GB
- ストレージ:
- 2x-RAID 1 + 0構成のSAS 10K 300GB-OSおよびメインのpostgresデータベース用
- 2x-RAID 1 + 0構成のSAS 10K 300GB-テスト用
- OS:Ubuntu 14.04.2-3.16.0-41
- PG:9.4.4 x86_64
テスト方法
したがって、2台のディスクを持つ物理マシンがあります:最初のディスクにはメインのpostgresデータベース(initdbの後)が含まれ、2番目のディスクはテスト済みのファイルシステム(ext4、btrfs lzo / zlib)にマークアップを作成せずに完全にフォーマットされています。
pg_basebackupを使用して作成された、テストに関係するバックアップコピーのテーブルスペースは、テストディスクに配置されます。 メインのpostgresデータベースも復元されます。
テストの本質は、5つのテーブルのシーケンシャルな読み取り(5つのスレッドのクローン)です。
このスクリプトは非常に単純で、単純なExplain Explainです。
各テーブルのサイズは13GBで、合計ボリュームは約65GBです。
最も単純なパラメーター「sar 1」-CPU ALL;を使用して、sarからチャートのデータを取得します。 「Sar -d 1」-I / O
開始する前に、次のコマンドを使用してページキャッシュをリセットします。
free && sync && echo 3 > /proc/sys/vm/drop_caches && free
バックグラウンドプロセスの完了を確認します。
SELECT sa.pid, sa.state, sa.query FROM pg_stat_activity sa;
フィギュア
寸法
| FS | DBサイズ | ディスクサイズ | 圧縮係数 |
|---|---|---|---|
| btrfs-zlib | 156GB | 35GB | 4.4 |
| btrfs-lzo | 156GB | 67GB | 2.3 |
| ext4 | 156GB | 156GB | 1 |
順次読み取り(分析の説明)
| btrfs-zlib | 302000ミリ秒 |
| btrfs-lzo | 262000ミリ秒 |
| ext4 | 420000ミリ秒 |
グラフ
CPU負荷
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 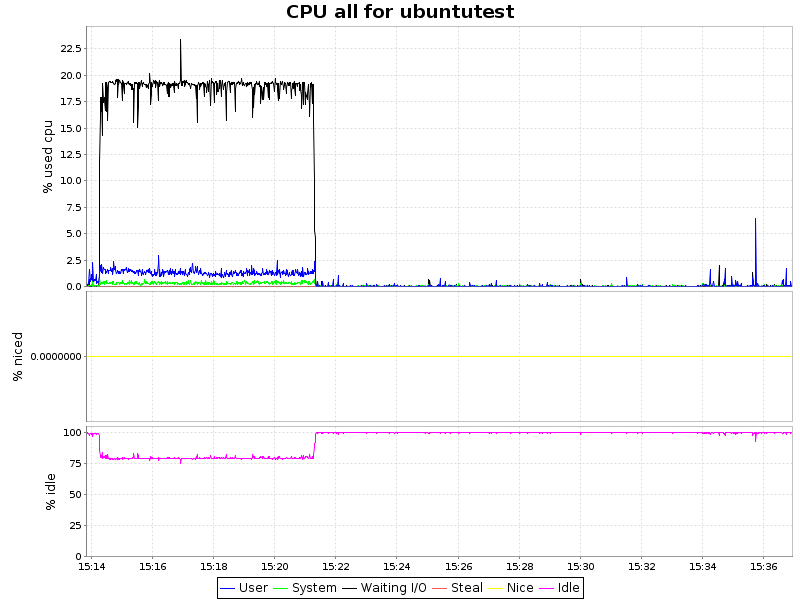 |
IOブロック転送
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 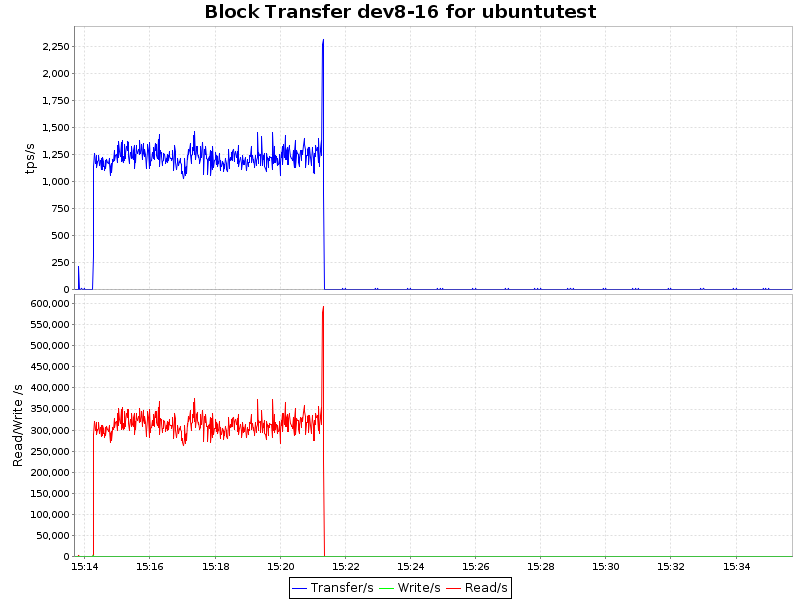 |
イオ待って
| btrfs-zlib | 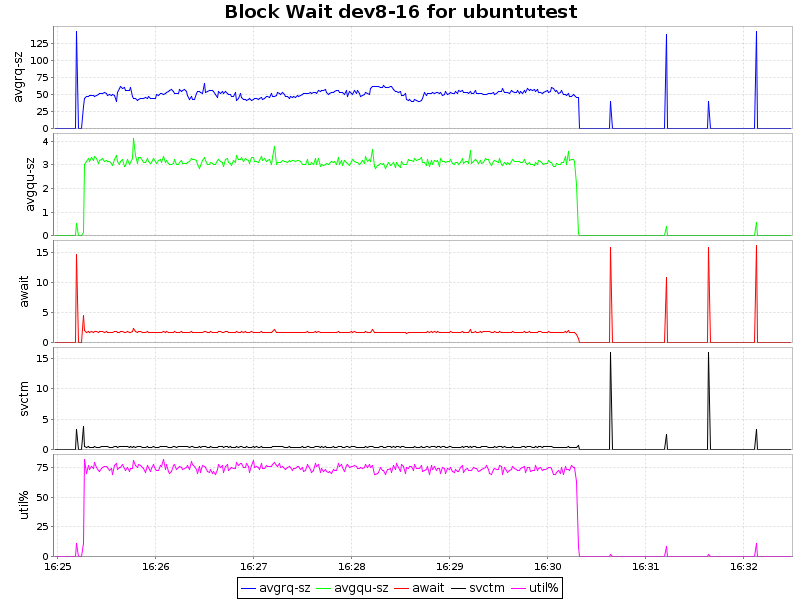 |
| btrfs-lzo | 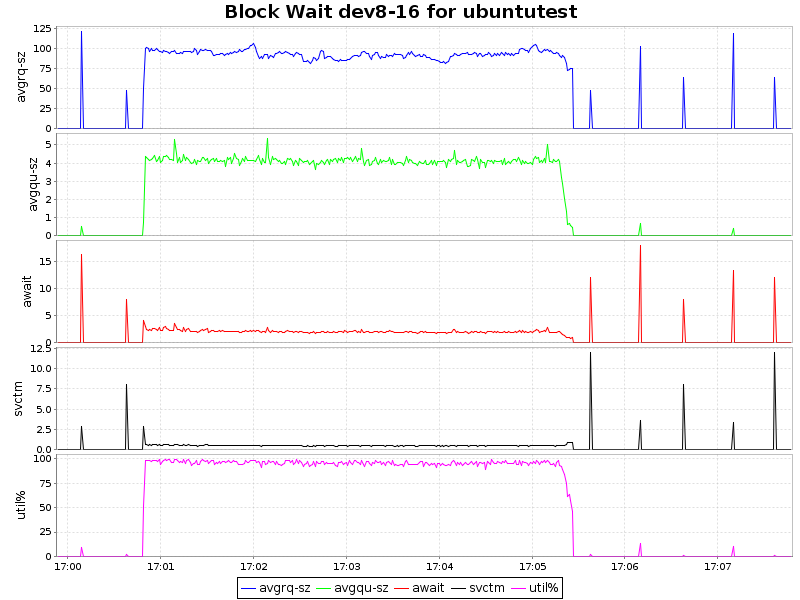 |
| ext4 |  |
おわりに
グラフからわかるように、lzoアルゴリズムを使用した圧縮はCPUにわずかな負荷を与えるだけであり、占有スペースの2倍の削減とある程度の加速により、このアプローチは非常に魅力的です。 Zlibはデータベースを4回押しますが、同時にCPUの負荷はすでに大幅に増加しています(CPU時間の7.5%まで)。これは、特定のシナリオでもまったく問題ありません。 ただし、btrfsは最近(カーネル3.10から)安定状態を取得したばかりであり、時期尚早に運用環境に導入することは可能です。 一方、同期レプリカを使用すると、この問題も解決されます。
PS
私の知る限り、zlibとおそらくlzoはSSE 4.2の命令を使用します。これにより、プロセッサーの負荷が軽減され、一部の仮想化環境では、プロセッサーの負荷が高くても圧縮を利用できない可能性があります。
誰かがこれに影響を与える方法を教えてくれたら、ハードウェアアクセラレーションを使用した場合と使用しない場合の違いを再確認します。