結果の視覚化は、研究の不可欠な部分です。たとえば、記事の公開やレポート付きのプレゼンテーションなどです。 同時に、得られた違いの正しい画像は、審美的な問題だけではありません(もちろん、効果的な視覚化は少なくともリスナーの注意を引き付けます!)だけでなく、純粋に統計的な問題でもあります。 私はいつも、どのグループが比較されたか、どの変数によって、統計的に有意な違いが見つかったかどうかなど、スケジュールが完了した作業に関する包括的なレポートを含むべきであるアプローチが好きでした。
Rの平均値の比較
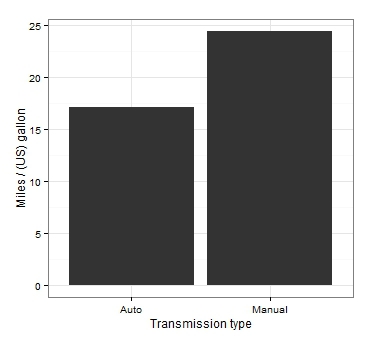
最も一般的なタイプのグラフの1つである平均値を比較し、わずか数行のコードでRにそれらを構築する方法を調べてみましょう。 Rに組み込まれているmtcarsデータを使用して、32台の自動車のさまざまな技術的特性に関する情報を提供します。 自動ギアボックスと手動ギアボックスを搭載した車の平均燃料消費量を比較します。
mtcars $ am <-factor(mtcars $ am、labels = c( "Auto"、 "Manual"))#ギアボックスのタイプを要因にする t.test(mpg〜am、mtcars)
t-テストの結果:
t = -3.7671、df = 18.332、p値= 0.001374
対立仮説:平均の真の差は0と等しくない
95%の信頼区間:
-11.280194 -3.209684
サンプル推定:
グループ0の平均グループ1の平均
17.14737 24.39231
統計的に有意な違いが見つかりましたが、結果を視覚化することは残っています。 「平均値の比較を表示する必要がない」というカテゴリのチャンピオンチャートから始めましょう。
実際、ここで何が間違っていますか?
平均が列に表示されるという事実を受け入れたとしても、この種のグラフの主な欠点は、そのデータの変動性の尺度が不足していることです。 このようなグラフを見ると、有意差が得られたかどうかは絶対にわかりません。 そして、私たちができる唯一の結論:右の列は左よりも高い!
元のバージョンを次のように改善しましょう。平均値をドットで表示し、信頼区間を追加します。
ライブラリ(ggplot2) ggplot(mtcars、aes(am、mpg))+ stat_summary(fun.data = mean_cl_boot、geom = "errorbar"、width = 0.1、size = 1)+ stat_summary(fun.y =平均、geom = "ポイント"、サイズ= 6、形状= 22、塗りつぶし= "白")+ theme_bw()+ xlab(「送信タイプ」)+ ylab( "Miles /(US)gallon")

はるかに良い! まず、独立した信頼区間は、統計的に有意な差に関する結論を確認します。 第二に、注意深い観察者のために、このグラフはデータの詳細に関する追加情報も提供します。手動ギアボックスを持つグループの平均燃料消費量の信頼区間がはるかに広いことがわかります。 私たちの場合、これはグループ内の標準偏差の異なる値によって説明されます(原則として、この情報は「柱状」グラフを見ても取得できません)。
分散分析といくつかのグループの比較
次に、分散分析と複数のグループの比較を使用した、より興味深いオプションを検討します。 Rに組み込まれたもう1つのデータ、ToothGrowthを使用します。 このデータにより、ビタミンCの投与量と消費された食物の種類に応じて、モルモットの歯の成長を調べることができます。 分散分析を適用します。
fit <-aov(len〜dose * supp、ToothGrowth)
分析結果:
Df Sum Sq Mean Sq F値Pr(> F) 用量1 2224.3 2224.3 133.415 <2e-16 *** supp 1 205.3 205.3 12.317 0.000894 *** 用量:supp 1 88.9 88.9 5.333 0.024631 * 残差56 933.6 16.7
各要因の影響とそれらの相互作用が重要であることが判明しました。 これは、視覚化せずに結論を出すことが非常に難しい場合は間違いありません。
ggplot(ToothGrowth、aes(factor(dose)、len、col = supp))+ stat_summary(fun.data = mean_cl_boot、geom = "errorbar"、width = 0.1、size = 1、position = position_dodge(0.2))+ stat_summary(fun.y =平均、geom = "ポイント"、サイズ= 3、形状= 22、塗りつぶし= "白"、位置= position_dodge(0.2))+ theme_bw()+ xlab(「ミリグラム単位の線量」)+ ylab(「歯の長さ」)+ scale_color_discrete(name = "Supplement type"、labels = c( "Orange juice"、 "Ascorbic acid"))
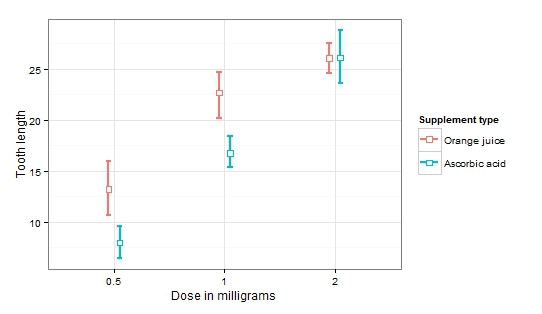
歯の長さの平均値が投与量の増加に伴って増加することに気付くのは簡単です(重要な投与量係数)。 さらに、製品の種類の影響は、投与量の増加とともに消えます(製品の種類と要因の相互作用の重要な要因)。
したがって、グラフに信頼区間をプロットすると、違いが統計的に有意であるかどうかを評価できるだけでなく、比較グループ内の変動性の性質を把握することもできます。 以下は、信頼区間間の距離とおおよそのp値との関係を少し思い出させてくれます。

まだRなのはなぜですか?
現在、データ分析と結果の視覚化のための多くのツールがあり、その中には、プログラミングの経験がなくてもかなり広い範囲の統計手法を使用できるものがあります( SPSSなど )。 Pythonプログラミング言語は、データ分析でも非常に一般的です。
データ分析のマスターを開始する場合:
- Rは非常にシンプルで直感的なプログラミング言語です。 Rでの作業の基本を学んだので、問題の解決を大幅に簡素化および高速化します。
- Rでの作業は貴重な経験を提供し、より複雑なプログラミング言語を学ぶのに役立ちます。
- もちろん可視化! この記事では、グラフの最も基本的なバージョンのみを検討しましたが、グラフィカルインターフェイスを使用したデータ分析プログラムでの視覚化よりも、何倍も見栄えがよくなります。
既にデータ分析の経験がある場合:
- Rには数千のパッケージとライブラリがあり、おそらく統計手法を使用する機会を提供します。 Rのランダム効果を使用して回帰分析を実装すると、特別なライブラリlme4が許可されます。 たとえば、Pythonの使用ははるかに困難です!
- Rには多くのライブラリがあり、さまざまな科学分野の非常に専門的な問題を解決するために、研究者や科学者によって直接作成されています。 たとえば、生体伝導体-バイオインフォマティクスのデータを分析するためのツールを提供します。 grtライブラリは、認知科学の計算モデルの分野で実験データを処理するのに役立ちます! 特別なライブラリは、ITトラッカーを使用してEEG、FMRI、または人の目の動きを記録する研究の結果を処理するのに役立ちます。
- 最後に、Rを使用すると、インタラクティブモードで最も広範なタスクをすばやく解決できます。
ロシア語のオンラインRコース:3週間のデータ分析
少し前まで、 Stepicプラットフォームでは、データ分析の基本的な方法に特化した統計の紹介に関するオンラインコースが完了しました。 バイオインフォマティクス研究所からの新しい3週間のオンラインコースでは、学生はRでのプログラミングの基礎を学びます。
最初の週では、データを操作し、言語の基本的な構文を理解する方法を学びます。 コースの2週目と3週目は、基本的な統計テストの適用と結果の視覚化に専念します。 コースはロシア語で、誰でも無料です! サインアップ: Rでのデータ分析
コースプログラム
週1
- 変数
- データフレームを使用する
- 記述統計
- 記述統計。 グラフ
- 結果の保存
週2
- 公称データ分析
- 2つのグループの比較
- 分散分析の使用
- 独自の関数を作成する
週3
- 相関と単純線形回帰
- 多重線形回帰
- モデル診断
- 二項回帰
- Rから分析結果をエクスポート
コースでお会いしましょう!