エントリー
Javaでの文字列処理について何を知っていますか? これらの知識はどれくらいあり、どれほど深く関連性がありますか? 言語のこの重要で基本的でよく使用される部分に関連するすべての問題を整理するために私と一緒に試してみましょう。 私たちの小さなガイドは2つの出版物に分かれています。
今日は、Javaの正規表現について説明し、そのメカニズムと処理アプローチを検討します。 また、 java.util.regexパッケージの機能も考慮してください。
正規表現
正規表現( 正規表現 、以降PBと呼びます)は、テキストを処理するための強力で効果的なツールです。 それらは最初にUNIXオペレーティングシステム( edおよびQED )のテキストエディターで使用され、20世紀後半の電子ワードプロセッシングにブレークスルーをもたらしました。 1987年に、より複雑なPBがPerl言語の最初のバージョンに登場し、Cで記述されたHenry Spencer(1986)パッケージに基づいていました。そして、1997年に、Philip HazelはPerl Compatible Regular Expressions (PCRE) PerlのRV。 現在、PCREは、 Apache HTTP Serverなどの多くの最新ツールで使用されています 。
最新のプログラミング言語のほとんどはPBをサポートしていますが、Javaも例外ではありません。
メカニズム
RVメカニズムの構築に基づいた2つの基本テクノロジーがあります。
- 非決定性有限状態マシン(NKA)-「正規表現によって制御されるメカニズム」
- 確定的有限状態マシン(DFA)-「テキスト駆動メカニズム」
NKA-RS内の制御がコンポーネントからコンポーネントに転送されるメカニズム。 NQAはRTをスキャンして1つのコンポーネントを探し、コンポーネントがテキストと一致するかどうかを確認します。 一致する場合、次のコンポーネントがチェックされます。 この手順は、PBのすべてのコンポーネントで一致が見つかるまで(一般的な一致が得られるまで)繰り返されます。
DKAは、文字列を分析し、すべての「一致する可能性があるもの」を監視するメカニズムです。 その操作は、テキストの各スキャン文字に依存します(つまり、DFAは「テキスト駆動型」です)。 デンマークのメカニズムは、文字のテキストをスキャンし、「潜在的な一致」を更新して予約します。 次の文字が「潜在的な一致」をキャンセルすると、DFAはリザーブに戻ります。 予備金なし-偶然の一致なし。
DKAがNKAよりも高速に動作することは論理的です(DKAは、テキストの各文字を1回だけ、NKA-RSの分析が完了するまで何度でもチェックします)。 しかし、NCAはさらなるイベントのコースを決定する機会を提供します。 RVを正しく記述することにより、プロセスを大幅に制御できます。
Javaの正規表現はNKAエンジンを使用します。
これらのタイプの有限状態マシンについては、記事「内部からの正規表現」で詳細に検討されています。
処理アプローチ
プログラミング言語では、RVを処理するための3つのアプローチがあります。
- 統合された
- 手続き的
- オブジェクト指向
統合アプローチ-低レベル言語構文にRVを埋め込む。 このアプローチは、すべてのメカニズム、チューニングを隠し、その結果、プログラマーの作業を簡素化します。
手続き型アプローチとオブジェクト指向アプローチのRVの機能は、それぞれ関数とメソッドを提供します。 関数とメソッドは、特別な言語構造の代わりに文字列をパラメーターとして受け取り、PBとして解釈します。
Javaは、オブジェクト指向のアプローチを使用して正規表現を処理します。
実装
Javaで正規表現を使用するために、 java.util.regexパッケージが提供されています。 パッケージはバージョン1.4で追加され、既に正規表現を操作するための強力で最新のアプリケーションインターフェイスが含まれています。 CharSequence インターフェースを実装するオブジェクトの使用により、優れた柔軟性を提供します 。
すべての機能は、インターフェイスと例外の2つのクラスで表されます。
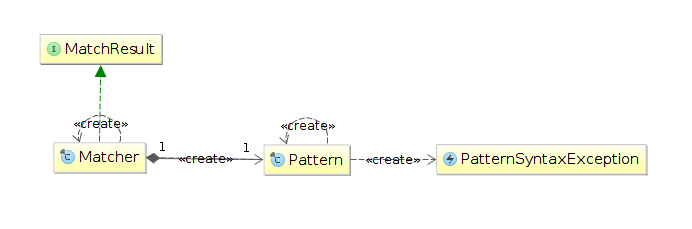
模様
Patternクラスは、PBのコンパイル済み表現です。 このクラスにはパブリックコンストラクターがないため、このクラスのオブジェクトを作成するには、静的コンパイルメソッドを呼び出し、PBを最初の引数として文字列を渡す必要があります。
// XML <xxx></xxx> Pattern pattern = Pattern.compile("^<([az]+)([^>]+)*(?:>(.*)<\\/\\1>|\\s+\\/>)$");
また、2番目のパラメーターとして、フラグをPatternクラスの静的定数としてコンパイルメソッドに渡すことができます。次に例を示します。
// email xxx@xxx.xxx ( ) Pattern pattern = Pattern.compile("^([a-z0-9_\\.-]+)@([a-z0-9_\\.-]+)\\.([az\\.]{2,6})$", Pattern.CASE_INSENSITIVE);
利用可能なすべての定数とそれらに相当するフラグの表:
| いや | 定数 | 同等の埋め込みフラグ式 |
|---|---|---|
| 1 | パターン.CANON_EQ | - |
| 2 | パターン.CASE_INSENSITIVE | (?i) |
| 3 | Pattern.COMMENTS | (?x) |
| 4 | パターン.MULTILINE | (?m) |
| 5 | パターン.DOTALL | (?s) |
| 6 | パターン.LITERAL | - |
| 7 | パターン.UNICODE_CASE | (?u) |
| 8 | パターン.UNIX_LINES | (?d) |
// hex ? if (Pattern.matches("^#?([a-f0-9]{6}|[a-f0-9]{3})$", "#8b2323")) { // true // - }
また、PBを使用して文字列を部分文字列の配列に分割することが必要になる場合があります。 splitメソッドはこれに役立ちます。
Pattern pattern = Pattern.compile(":|;"); String[] animals = pattern.split("cat:dog;bird:cow"); Arrays.asList(animals).forEach(animal -> System.out.print(animal + " ")); // cat dog bird cow
マッチャーとMatchResult
マッチャー -文字列を表し、PBでマッチングメカニズムを実装し、このマッチングの結果を格納するクラス( MatchResultインターフェイスのメソッドの実装を使用)。 パブリックコンストラクターがないため、このクラスのオブジェクトを作成するには、 Patternクラスのmatcherメソッドを使用する必要があります。
// URL String regexp = "^(https?:\\/\\/)?([\\da-z\\.-]+)\\.([az\\.]{2,6})([\\/\\w \\.-]*)*\\/?$"; String url = "http://habrahabr.ru/post/260767/"; Pattern pattern = Pattern.compile(regexp); Matcher matcher = pattern.matcher(url);
しかし、まだ結果はありません。 それらを取得するには、 findメソッドを使用する必要があります 。 一致を使用できます-このメソッドは、文字列全体が指定されたRVに一致する場合にのみtrueを返します。findはRVを満たす部分文字列を検索しようとします。 調整の結果の詳細については、 MatchResultインターフェイスのメソッドの実装を使用できます。次に例を示します。
// IP String regexp = "(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"; // find() matches() String goodIp = "192.168.0.3"; String badIp = "192.168.0.3g"; Pattern pattern = Pattern.compile(regexp); Matcher matcher = pattern.matcher(goodIp); // matches() - true, find() - true matcher = pattern.matcher(badIp); // matches() - false, find() - true // System.out.println(matcher.find() ? "I found '"+matcher.group()+"' starting at index "+matcher.start()+" and ending at index "+matcher.end()+"." : "I found nothing!"); // I found the text '192.168.0.3' starting at index 0 and ending at index 11.
find(int start)を使用して、目的の位置から検索を開始することもできます 。 検索する別の方法-lookingAtメソッドがあることに注意してください。 行の先頭から一致のチェックを開始しますが、matchsとは異なり、完全なコンプライアンスは必要ありません。
このクラスは、指定された行のテキストを置き換えるためのメソッドを提供します。
| appendReplacement(StringBuffer sb、文字列置換) | 追加と交換のメカニズムを実装します 。 目的の場所に置換を追加して、 StringBufferオブジェクト(パラメーターとして受信)を形成します。 最後の検索結果の末尾()に一致する位置を設定します。 この位置の後は何も追加しません。 |
| appendTail(StringBuffer sb) | appendReplacementを1回以上呼び出した後に使用され、残りの文字列をパラメーターとして取得されたStringBufferクラスのオブジェクトに追加するために使用されます。 |
| replaceFirst(文字列置換) | PBに対応する最初のシーケンスを置換で置き換えます。 appendReplacementおよびappendTailメソッドの呼び出しを使用します。 |
| replaceAll(文字列置換) | PBに対応する各シーケンスを置換で置き換えます。 appendReplacementおよびappendTailメソッドも使用します 。 |
| quoteReplacement(文字列) | スラッシュ( '\' )およびドル記号( '$' )が無意味になる文字列を返します。 |
Pattern pattern = Pattern.compile("a*b"); Matcher matcher = pattern.matcher("aabtextaabtextabtextb the end"); StringBuffer buffer = new StringBuffer(); while (matcher.find()) { matcher.appendReplacement(buffer, "-"); // buffer = "-" -> "-text-" -> "-text-text-" -> "-text-text-text-" } matcher.appendTail(buffer); // buffer = "-text-text-text- the end"
PatternSyntaxException
正規表現で構文エラーが発生すると、 未チェック ( 未チェック )の例外が発生します。 次の表に、すべてのメソッドとその説明を示します。
| getDescription() | エラーの説明を返します。 |
| getIndex() | RVでエラーが見つかった行のインデックスを返します |
| getPattern() | 無効なPBを返します。 |
| getMessage() | getDescription()+ getIndex()+ getPattern() |