質問文
最近、ある大企業とのインタビューで、負荷平均とは簡単な質問をされました。 どれだけ正解したのかわかりませんが、正確な答えが本当に分からないことに気づきました。
ほとんどの人は、おそらく負荷平均が一定期間 (1、5、および15分間) のシステムの平均負荷であることを知っています。 また、 この記事の使用方法に関する詳細を確認することもできます。 ほとんどの場合、この知識はLAの値によってシステム負荷を推定するのに十分ですが、私は専門職の物理学者であり、「一定期間の平均」を見ると、すぐにこの間隔のサンプリングレートに興味を持ちます。 「待機中のリソース」という用語を見ると、正確にどのくらいの時間待機する必要があるか、そして短時間で高いLAを取得するために必要な些細なプロセスの数が興味深いものになります。 そして最も重要なのは、これらの質問に対する答えが5分間のGoogleとの連携を提供しないのはなぜですか? これらの微妙さにも興味があるなら、猫にようこそ。
ここで何かが間違っています...
まず、知っていることを判断します。 一般に、負荷平均は、3つの時間間隔のいずれかで保留中のCPU CPUリソースの平均数です。 また、通常の状態でのこの値は0〜1の範囲であり、ユニットは過負荷のないシングルコアシステムの100%の負荷に対応することもわかっています。 将来的には、このシステムはよりシンプルでより指標的であるため、このシステムをシングルコアと見なします。
ここで何が間違っていますか?
最初に 、いくつかの量の算術平均は 、これらの量の合計をその数で割ったものに等しいことを知っています。 私たちが絶対に理解できないこの情報の量から。 1分間に保留中のプロセスをカウントすると、平均値は、1分あたりのプロセス数を1で割った値に等しくなります。 1秒ごとにカウントする場合、各計算のプロセス数は範囲とともに減少し、60で除算します。したがって、データ取得中のサンプリング周波数が高くなるほど、平均値が低くなります。
第二に、 「リソース待機プロセス」とはどういう意味ですか? 多数の高速プロセスを一度に開始すると、それらはすべてキューに入れられ、論理的には短期間でLAは完全に許容できない値に成長し、継続的な監視では一定のジャンプが表示されますが、通常の状況ではそうではありません。
第三に 、100%負荷のシングルコアシステムでは、負荷平均が1になります。ただし、プロセス数は大幅に異なる可能性がありますが、このカーネルのパラメーターには依存しません。 この質問は、「保留中のプロセスリソース」の正しい定義によって、またはカーネルパラメーターに対する何らかの正規化の存在によって対処できます。
文学
これらの質問に対する答えを見つけることはそれほど難しくありませんでした。 真実は英語のみであり、すべてがすぐに明らかになったわけではありません。 2つの記事が特に見つかりました。
負荷平均を調べる
「UNIXの負荷平均」
ユーザーRondoは、数学的装置のより詳細な調査で記事の第2部も提案しました。「UNIX Load Average。 パート2»
また、2番目の記事で示されている、すべてをすでに理解している人のための小さなテストです。
興味のある方は、両方の記事を読むことをお勧めしますが、非常に近いものについて説明しています。 最初に、システム操作のさまざまな興味深い詳細を一般的な用語で説明し、2番目に、LA計算をより詳細に分析し、負荷と専門家のコメントを含む例を示します。
ちょっとした核の魔法
これらの資料から、呼び出された各プロセスにはCPUを使用するための限られた期間が与えられていることがわかります。標準のIntelアーキテクチャでは、この期間は10ミリ秒です。 これは100分の1秒であり、ほとんどの場合、プロセスにそれほど時間はかかりません。 ただし、割り当てられたすべての時間を使用するプロセスがある場合、ハードウェア割り込みが呼び出され、システムはプロセッサの制御を取り戻します。 さらに、10msごとにティックカウンタ(jiffiesカウンタ)が増加します。 これらのティックは、システムが起動した瞬間からカウントされ、500ティックごと(5秒ごと)に負荷平均が計算されます。
計算コード自体は、timer.cファイルのカーネルにあります(コードはバージョン2.4用であり、バージョン2.6ではすべて分散していますが、ロジックは変更されていません。したがって、重要な変更もないことを願っていますが、率直に言って、最新リリースは確認していません) :
646 unsigned long avenrun[3]; 647 648 static inline void calc_load(unsigned long ticks) 649 { 650 unsigned long active_tasks; /* fixed-point */ 651 static int count = LOAD_FREQ; 652 653 count -= ticks; 654 if (count < 0) { 655 count += LOAD_FREQ; 656 active_tasks = count_active_tasks(); 657 CALC_LOAD(avenrun[0], EXP_1, active_tasks); 658 CALC_LOAD(avenrun[1], EXP_5, active_tasks); 659 CALC_LOAD(avenrun[2], EXP_15, active_tasks); 660 } 661 }
ご覧のとおり、同じ3つのLA値が順番に計算されますが、正確に何が考慮され、どのように考慮されるかは示されていません。 これも問題ではありません。関数count_active_tasks()のコードは同じファイルにあり、もう少し高いです:
625 static unsigned long count_active_tasks(void) 626 { 627 struct task_struct *p; 628 unsigned long nr = 0; 629 630 read_lock(&tasklist_lock); 631 for_each_task(p) { 632 if ((p->state == TASK_RUNNING || 633 (p->state & TASK_UNINTERRUPTIBLE))) 634 nr += FIXED_1; 635 } 636 read_unlock(&tasklist_lock); 637 return nr; 638 }
また、CALC_LOADは、いくつかの興味深い定数とともにsched.hにあります。
61 #define FSHIFT 11 /* nr of bits of precision */ 62 #define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */ 63 #define LOAD_FREQ (5*HZ) /* 5 sec intervals */ 64 #define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */ 65 #define EXP_5 2014 /* 1/exp(5sec/5min) */ 66 #define EXP_15 2037 /* 1/exp(5sec/15min) */ 67 68 #define CALC_LOAD(load,exp,n) \ 69 load *= exp; \ 70 load += n*(FIXED_1-exp); \ 71 load >>= FSHIFT;
上記のすべてから、カーネルは5秒ごとにRUNNINGおよびUNINTERRUPTIBLE状態にあるプロセスの数を調べて(他のUNIXシステムではそうではない)、各プロセスに対して1 << FSHIFTに等しいFIXED_1だけカウンターをインクリメントすると言うことができます。または1 << 11は、2 ^ 11と同等です。 これは、32ビット長の標準int変数を使用して浮動小数点計算をシミュレートするために行われます。 計算後、結果を11ビット右にシフトした後、余分な注文を破棄します。 同じsched.hから:
49 /* 50 * These are the constant used to fake the fixed-point load-average 51 * counting. Some notes: 52 * - 11 bit fractions expand to 22 bits by the multiplies: this gives 53 * a load-average precision of 10 bits integer + 11 bits fractional 54 * - if you want to count load-averages more often, you need more 55 * precision, or rounding will get you. With 2-second counting freq, 56 * the EXP_n values would be 1981, 2034 and 2043 if still using only 57 * 11 bit fractions. 58 */
少しの核崩壊
いいえ、システムのコアはここでは減衰せず、CALC_LOAD式のみです。これに従って、負荷平均は放射性崩壊の法則 、または単に指数関数的減衰に基づきます。 この法則は微分方程式の解に過ぎません
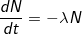 つまり、新しい値はそれぞれ前の値から計算され、要素数の減少率は要素数に直接依存します。
つまり、新しい値はそれぞれ前の値から計算され、要素数の減少率は要素数に直接依存します。
この微分方程式の解は指数法則です:
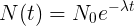
実際、負荷平均は、算術平均の通常の意味での平均値ではありません。 これは離散関数であり、システムが起動した瞬間から定期的に計算されます。 さらに、関数の値は、指数関数的減衰の条件下でシステムで実行されるプロセスの数です。
CALC_LOADの計算部分を数学言語で書き換えることにより、このような構造を観察します。
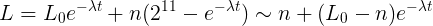
この場合の2 ^ 11は単一性に相当します。最初に修正し、どこにでも追加しました。新しいプロセスの数もこれらの数量で計算されます。 A
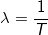 ここで、Tは測定間隔(1、5、または15分)です。
ここで、Tは測定間隔(1、5、または15分)です。
測定間の固定時間間隔と固定時間については、指数の値を事前に計算し、コードで行われる定数として使用できることに注意してください。 最後の操作-11ビット右にシフトすると、低次を破棄して、希望する負荷平均値が得られます。
結論
LAの計算方法を理解したら、記事の冒頭にある質問に答えてみましょう。
1)平均値は算術平均ではなく、システムの開始から5秒ごとに計算される関数の平均値です。
2)「保留中のCPUリソース」は、RUNNINGおよびUNINTERRUPTIBLEの状態にあるすべてのプロセスです。 また、減衰指数は平滑化機能の役割を果たしているため、連続監視中に負荷平均の大幅なジャンプは観察されません(ただし、1分間を考慮すると、それらに気付くことができます)。
3)そして、これは最も興味深い結論の1つです。 事実、nの任意の値に対する上記の負荷平均関数は、この値まで単調に増加しますが、n <Lの場合、指数関数的に減衰します。 したがって、LA = 1は、CPUが常に1つのプロセスに占有されており、キューがないことを示します。一般に、100%の負荷と見なすことができます。 同時に、LA <1はCPUがアイドル状態であることを示し、アイドル状態のnfsをノックしているプロセスが多数ある場合は、
こちらは 
ただし、元々利用可能であった質問に答えるだけでなく、コードを解析すると新しい問題が発生します。 たとえば、フェージング指数は保留中のプロセスの数を減らすのに適用できますか? 放射性崩壊を考慮すると、その速度は原子核の数によってのみ制限されます。この場合、多数のプロセスがあるため、すべてがCPU帯域幅に対して停止します。 また、結果の式を指数法則と比較すると、次のことが明らかになります。
ここで、Tはデータセット間隔の期間(1、5、または15分)です。 したがって、カーネル開発者は、負荷平均の減少率は測定の継続時間に反比例すると考えています。これは少なくとも私にとっては明らかではありません。 巨大なLA値がシステム負荷を実際に表示しない、またはその逆の状況をシミュレートすることは難しくありません。
最終分析では、負荷平均を計算するために、値を可能な限り迅速に減少させる平滑化関数が選択されたようです。これは一般に有限数を取得するための論理ですが、実際のプロセスは表示しません。 そしてもし誰かが私に、なぜ出展者で、なぜこの形式で説明するのか、とても感謝しています。