
まだ見ていなければ、これらは深い畳み込みネットワークによるImageNet-2010分類によるヒントンとクリジェフスキーの結果です
その右隅を見てみましょう。アルゴリズムは、十分な自信を持ってヒョウを特定し、ジャガーとチーターを2位と3位に大きなマージンで配置します。
考えてみると、これは一般的に非常に奇妙な結果です。 なぜなら、ある大きな猫を別の大きな猫と区別する方法を知っているとしましょう。 たとえば、私はしません。 確かに、全体的な調和/堅牢性や体の比率など、動物学上のやや微妙な違いがありますが、私たちはまだ、人間の観点からはかなり愚かなある種の間違いを犯すコンピューターアルゴリズムについて話しています。 彼は一体どうしてるの? コンテキストと背景に関連するものがあるかもしれません(ヒョウは木や茂みに多く見られ、チーターはサバンナにいます)? 一般に、この特定の結果について最初に考えたとき、非常にクールでパワフルで、インテリジェントマシンがすぐ近くにあり、私たちを待っている、長生きのディープラーニングなどが行われているように思えました。
したがって、実際には、すべてが完全に間違っています。
1つの小さな動物学的事実
それでは、猫をもう少し詳しく見てみましょう。 これはジャガーです。

南北アメリカ大陸で最大の猫ですが、牙で頭蓋骨を刺し、脳に噛みついて犠牲者を定期的に殺す唯一の猫です。 これは、私たちのトピックにとって重要な動物学的事実ではありませんが、それでもなお重要です。 特徴的な特徴の中には、目の色、大きな顎があり、一般に、これらは3つ全体の中で最も大きなものです。 ご覧のとおり、詳細は非常に薄いです。
これはヒョウです:

アフリカに住んでおり、この大陸のライオンに次いで2番目です。 彼らは明るい(黄色)目を持ち、ジャガーよりも著しく小さい足を持っています。
そして最後に、チーター:

2人の兄弟よりもサイズがかなり小さい。 彼は長くて細い体を持ち、最後に視覚的に目立つ兆候として機能する少なくとも何か-目から鼻への涙の暗い道のような銃口の独特のパターン。
そして、ここで彼は非常に動物学的な事実です:これらの猫の皮膚の斑点は全くランダムに配置されていないことが判明しました。 それらは「ソケット」と呼ばれる小さなグループにいくつかの部分にまとめられます。 さらに、ヒョウには比較的小さなソケットがあり、ジャガーにははるかに多く(そして小さな黒い点が内部にあります)、チーターにはまったくありません-孤独なスポットが散在しています。

これはここでよく見られます。 自発的な教育のスポンサーはImgurであり、資材から何かを誤解した場合には謝罪します。
蜂が疑い始める
その瞬間のどこかで恐ろしい推測が脳に忍び込み始めます-しかし、スポットのテクスチャのこの違いが、アルゴリズムが3つの可能な認識クラスを互いに区別する主な基準である場合はどうでしょうか? つまり、実際には、畳み込みネットワークは、描かれたオブジェクトの形状、足の数、顎の厚さ、ポーズの特性、およびこれらすべての微妙な違いに注意を払っていません。
この仮定を検証する必要があります。 ノイズ、歪み、または認識寿命を複雑にする他の要因なしに、検証のためにシンプルで洗練されていない写真を撮ってみましょう。 私は誰でもこの絵を一目で簡単に認識できると確信しています。

検証のために、 Caffeと事前トレーニングモデルの認識チュートリアルを使用します。これは、Webサイトに直接あります。 ここでは、投稿の冒頭で述べたものと同じモデルではなく、類似の(CaffeNet)を使用します。一般的に、すべての畳み込みネットワークはほぼ同じ結果を示します。
import numpy as np import matplotlib.pyplot as plt caffe_root = '../' import sys sys.path.insert(0, caffe_root + 'python') import caffe MODEL_FILE = '../models/bvlc_reference_caffenet/deploy.prototxt' PRETRAINED = '../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel' IMAGE_FILE = '../sofa.jpg' caffe.set_mode_cpu() net = caffe.Classifier(MODEL_FILE, PRETRAINED, mean=np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1), channel_swap=(2, 1, 0), raw_scale=255, image_dims=(500, 500)) input_image = caffe.io.load_image(IMAGE_FILE) prediction = net.predict([input_image]) plt.plot(prediction[0]) print 'predicted class:', prediction[0].argmax() plt.show()
何が起こった:

>> predicted class: 290

おっと
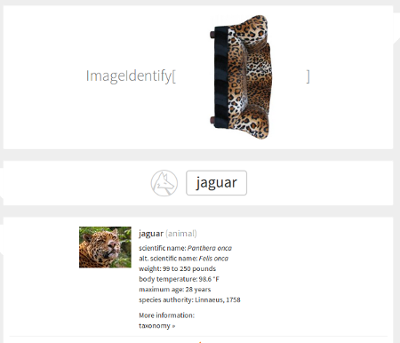
でも、たぶん、これは単一のモデルの問題でしょうか? さらに確認しましょう:
クラリファイ
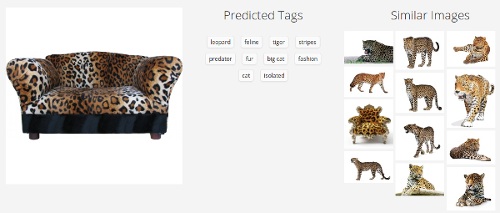
スティーブン・ウルフラムの最近のメガサービス
ここで、写真は横向きになっています。これは、サービスが適切に配置されたソファに対応したことを意味しますが、90度回転すると破損しました。 ある意味では、これは彼がまったくそれを行えなかった場合よりもさらに悪いことです。そのような単純な変換は結果を根本的に変えるべきではありません。 テクスチャについての私たちの推測は真実に近いようです。
驚くべきことに、オープンな認識Webサービスはそれほど多くありません。 私はいくつかのチェックを行いました( Microsoft 、 Google )-それらのいくつかはジャガーを滑らせることなくより良く動作しますが、誰もソファを片側に倒すことができませんでした。 「{Somebody}のディープラーニングプロジェクトが画像認識で人間をしのぐ」などの見出しが既に点滅している世界では、悪い結果ではありません。
なぜこれが起こっているのですか?
ここに1つの推測があります。 アーキテクチャの詳細に立ち入らずに、通常の教師付き分類器の代わりに自分自身を想像してみましょう。 入力で多数の画像を取得し、それぞれに対応するクラスがマークされます。次に、各画像の出力がこのクラス自体に対応するようにパラメーターを調整します。 したがって、画像からいくつかの内部構造、特徴的な特徴を抽出して、分析的に表現できない認識ルールを定式化することを望みます。そうすることで、これらの特徴を持つ新しい、見慣れない画像が目的のクラスに分類されます。 学習プロセスでは、予測の誤差の大きさによって導かれ、サンプルのサイズと比率が重要です-クラスAの画像が99枚、クラスBの画像が1枚ある場合、分類器の最も愚かな動作(「常にA」と言います)で誤差は1になります%、特に何も学ばなかったという事実にもかかわらず。
したがって、この観点からはここで問題はありません。 アルゴリズムは動作するはずです。 突然のヒョウ色のソファーは異常であり、ImageNetサンプルでは珍しいことであり、私たちの日常の経験でも同様です。 一方、明るい背景の暗い斑点の特徴的なパターンは、大きな斑点のある猫の素晴らしい特徴です。 最後に、どこでそのようなパターンが表示されますか? さらに、異なるタイプの猫を区別するという精神で、非常に難しいタスクが分類器に割り当てられることを考慮して、パターンの使用はさらに大きくなります。 サンプルに十分なヒョウのソファを投げた場合、彼は違いの新しい基準を考え出す必要があります(結果はどうなるのでしょうか)が、何もないので、そのようなまれなケースの間違いは完全に自然です。
かどうか?
私たち人間がすること
数字を書くことを学んだとき、学校の1年生を覚えておいてください。
その後、各生徒は「MNISTデータベース」という名前の重い本を持ってきて、何百ものページに6万の数字が、さまざまな手書きやスタイルで、太字でほとんど目立たない斜体で書き出されました。 特に頑固なものは、より大きなアプリケーション「Permutation MNIST」に到達しました。同じ番号が異なる角度で回転し、上下左右に伸び、右と左にシフトしました-これがないと、それを見て数字を判断することができませんでした斜めに。 その後、長くて退屈なトレーニングが終了すると、それぞれに10,000桁の小さな(比較的)リストが与えられ、一般クラステストで正しく識別される必要がありました。 しかし、数学が次のレッスンに来た後、もっとたくさんのアルファベットを学ぶ必要がありました...
ふむ 言う、それはすべて間違っていましたか?
好奇心が強いですが、あなたと私は学習プロセスでサンプルを実際に必要としないようです。 少なくとも、それが必要な場合、それが現在トレーニング分類器で使用されている理由ではありません-空間的順列と歪みに対する耐性を開発するために。 手書きの数字は、抽象的なプラトニックの概念と同じように認識されます-縦棒、上下に2つの円。 たとえば、これらの概念のいずれも存在しないイメージに遭遇した場合、「数ではない」としてそれを拒否しますが、教師付き分類器はそれを行いません。 私たちのコンピューターアルゴリズムは概念を探しません-大量のデータをすくい上げ、それらをヒープに押し出し、各画像は他の画像よりも少し共通点のある種類のヒープになります。
あなたの人生でヒョウを何匹見ましたか? それはまともですが、メガネ、コンピューター、顔(ImageNetの他のクラス)よりも確かに少ないかもしれません。 この色のソファに会ったことはありますか? 私には思えますが、ほとんどありません。 それでも、このテキストを読んだ人の誰も、上記の画像を正しく分類する前に少しも考えませんでした。
畳み込みネットワークは状況を悪化させる

畳み込みネットワークは、ImageNetベースのコンペティションで常に高い結果を示しており、2014年の時点では畳み込みネットワークのアンサンブルに次ぐようです。 それらについてさらに多くの詳細を読む必要があります。今のところ、これらは学習プロセスで小さな「フィルター」(またはカーネル)を形成するネットワークであり、特定のフィルターに対応する要素が存在する場所でアクティブ化される画像を通過するという事実に限定されます。 彼らは画像を認識するときにそれを使用することを非常に好んでいます-第一に、写真の異なる場所に現れる可能性のある局所的な兆候があるため、そして第二に、巨大なものを押すよりもかなり計算的に安価であるため(1024x768 =〜800000パラメーター)通常のネットワークへの画像。
再びヒョウを想像してみましょう。 これらは非常に複雑な物理体であり、空間内のさまざまな位置を取り、さまざまな角度から撮影することもできます。 ほとんどの場合、各ヒョウの写真には、ユニークで、ほとんど繰り返されないアウトラインが含まれます-口ひげ、足、尾が見えるところ、どこかに-かすんだ背中だけが含まれます。 このような状況では、畳み込みネットワークは単なる救世主です。なぜなら、このような多くのすべての形式に対して1つのルールを考え出す代わりに、「この一連の小さな際立った特徴を取り、写真でそれらを調べて、一致する数を合計する」と言うからです。 当然、ヒョウの斑点のテクスチャは良い兆候になります-それは多くの場所を持ち、オブジェクトのポーズが変わっても実質的に変わりません。 そのため、CaffeNetなどのモデルは、写真内のオブジェクトの空間的変化に非常によく反応します。そのため、ソファにそれらが発生します。
これは実際には非常に不快なプロパティです。 画像内のオブジェクトの形状を完全に分析することを拒否すると、単純に一連の機能として認識し始めます。各機能は、他のユーザーと通信せずにどこにでも配置できます。 畳み込みネットワークを使用して、床に座っている猫と天井に座っている倒立猫を区別する機会をすぐに拒否します。 これは、インターネット上のどこかで個々の写真を認識する場合に便利ですが、そのようなコンピュータービジョンが実際の生活であなたの行動を調整する場合、それはまったく素晴らしいことではありません。
この議論に納得がいかない場合は、すでに数年前のヒントンの記事をご覧ください 。「畳み込みネットワークが破滅する」というフレーズが明確に聞こえるのはこのためです。 この記事の主要な部分は、代替概念-「カプセル理論」(彼が現在取り組んでいる )の設定に当てられており、読む価値もあります。
合計
しばらく考えてください(あまり真剣ではありません)-私たちはすべて間違っています。
膨大なデータセットに写真、毎年の大会、さらに深いネットワーク、さらに多くのGPUを詰め込みます。 MNISTの数字の認識を0.83のエラーから3年で0.23( 証明 )に改善しました(人がどのような間違いを犯すことができるのか、まだ正確にはわかりません)。 ImageNet Challengesでは、競合他社が10分の1パーセントを占めています。これはもう少し増えたようで、間違いなく勝ち、実際のコンピュータービジョンを獲得するでしょう。 それでも、いや。 私たちがしていることは、それらに描かれていることを理解せずに、たくさんの写真を可能な限り正確にカテゴリーにまき散らそうとすることです(ここでは「理解」という言葉は危険です)。 何か違うはずです。 私たちのアルゴリズムはオブジェクトの空間的位置を決定できなければならず、横向きのソファはまだソファとして識別できますが、「マスター、家具はあなたから取り外されています」というトピックに関するわずかな警告があります。 あなたや私のようなほんの数例ですぐに学習でき、マルチクラスサンプルを必要とせず、オブジェクト自体から必要な属性を抽出できる必要があります。
一般的に、明らかにするべきことがあります。