
OpenMPは、マルチスレッドプログラムを作成するためのコンパイラディレクティブ、ライブラリプロシージャ、および環境変数のセットを定義する標準です。
多くの記事はOpenMPに関する記事でした。 ただし、この記事にはいくつかの間違いを避けるためのヒントが含まれています。 これらのヒントは、講義や本ではあまり取り上げられていません。
1. クリティカルセクションに名前を付ける
キューで、あなたは愚痴の息子、キューで! // M A.ブルガコフ「犬の心」
criticalディレクティブを使用して、一度に1つのスレッドのみによって実行されるコードのセクションを指定できます。 スレッドの1つが指定された名前のクリティカルセクションの実行を開始した場合、同じセクションの実行を開始した他のスレッドはブロックされます。 彼らは並んで待ちます。 最初のスレッドがセクションの実行を完了するとすぐに、ブロックされたスレッドの1つがセクションに入ります。 クリティカルセクションを実行する次のスレッドの選択はランダムです。
#pragma omp critical [()]
クリティカルセクションには、名前を付けることも名前を付けないこともできます。 さまざまな状況で、パフォーマンスが向上します。 標準に従って、名前のないすべてのクリティカルセクションは1つの名前に関連付けられます。 名前を割り当てると、2つ以上のクリティカルセクションを同時に実行できます。
例:
#pragma omp critical (first) { workA(); } #pragma omp critical (second) { workB(); } // workA() workB() #pragma omp critical { workC(); } #pragma omp critical { workD(); } // workC() , workD()
名前を割り当てるときは、システム関数または既に使用されている名前に名前を付けないように注意してください。 クリティカルセクションが同じリソース(単一のファイルへの出力、画面への出力)で機能する場合、同じ名前を割り当てるか、まったく割り当てない価値があります。
2. 使用しないでください!=ループ制御
forディレクティブは、対応するループの構造に制限を課します。 確かに、対応するサイクルは標準的な形式である必要があります。
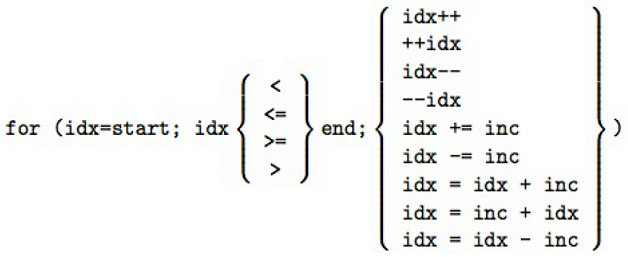
OpenMPアーキテクチャレビューボードからの開発者の応答
許可すれば!=、プログラマは無限のループ反復を取得できます。 問題は、反復回数を計算するコードを生成するコンパイラーにあります。
次のような単純なループの場合:
for( i = 0; i < n; ++i )
反復回数を決定することができます。n> = 0の場合はn、n <0の場合はゼロの反復です。
for( i = 0; i != n; ++i )
n> = 0の場合、n回の反復を決定できます。 n <0の場合、反復回数はわかりません。
for( i = 0; i < n; i += 2 )
反復回数は、n> = 0の場合は((n + 1)/ 2)の整数部であり、n <0の場合は0です。
for( i = 0; i != n; i += 2 )
iがnに等しいかどうかを判断できません。 nが奇数の場合はどうなりますか?
for( i = 0; i < n; i += k )
反復回数は、n> = 0の場合は((n + k-1)/ k)の最大整数であり、n <0の場合は0です。 k <0の場合、これは有効なOpenMPプログラムではありません。
for( i = 0; i != n; i += k )
増減しますか? 平等はありますか? これはすべて無限ループにつながる可能性があります。
3. nowaitを慎重にインストールする
ハチコが待ちたいのなら、彼は待たなければならない。//ハチコ:最も忠実な友人
nowait句が指定されていない場合、 forコンストラクトは暗黙的にバリア同期で終了します。 並列サイクルの終わりに、並列実行フローの暗黙的なバリア同期が発生します。それらのさらなる実行は、すべてが特定のポイントに到達したときにのみ発生します。 このような遅延が不要な場合、nowaitオプションを使用すると、すでにループの終わりに達したスレッドは、他のスレッドと同期せずに実行を継続できます。
例:
#pragma omp parallel shared(n,a,b,c,d,sum) private(i) schedule(dynamic) { #pragma omp for nowait for (i = 0; i < n; i++) a[i] += b[i]; #pragma omp for nowait for (i = 0; i < n; i++) c[i] += d[i]; #pragma omp for nowait reduction(+:sum) for (i = 0; i < n; i++) sum += a[i] + c[i]; }
この例にはエラーがあり、 スケジュール(動的)にあります。 実際、データに依存するnowaitサイクルはc schedule(static)でのみ有効です。 この作業スケジューリングの方法でのみ、標準は、データ依存ループを待つことなく正しい作業を保証します 。 私たちの場合、ほとんどの実装ではスケジュール(動的)を消去するだけで十分です。デフォルトではスケジュール(静的)が使用されます。
4. アンタイドタスクを使用する前に、コードを注意深く確認します
int dummy; #pragma omp threadprivate(dummy) void foo() {dummy = …; } void bar() {… = dummy; } #pragma omp task untied { foo(); bar(); }
task untiedは、タスクがそれを開始したスレッドに結び付けられていないことを指定します。 中断後、別のスレッドがタスクの実行を継続する場合があります。 この例では、 タスクuntiedの誤った使用。 プログラマは、タスク内の両方の機能が1つのスレッドによって実行されることを想定しています。 ただし、タスクバーを一時停止した後に()が異なる方法で実行される場合。 各スレッドは独自のダミー変数を持っているため(この場合、 threadprivateです )。 バー()の割り当ては正しく行われません。
これらのヒントが初心者に役立つことを願っています。
便利なリンク:
OpenMP 4.0 pdfの例
OpenMP 4.0 githubの例
OpenMP 4.0標準pdf
4枚のC ++ pdfのすべてのディレクティブ
4シートのすべてのディレクティブFortran pdf
ミハイル・クルノソフによるロシア語の最高のOpenMPスライドのいくつかpdf