前のパーツ
このパートで説明する内容
このパートでは、次のことを理解します。
- クエリに条件式を含めることができるCASE式を使用します。
- SELECT ... WHERE ...演算子で受信した詳細データに基づいて計算されたさまざまな種類の合計(集計値)を取得できる集計関数。
- GROUP BY句を使用すると、集計関数とともに、グループのコンテキストで詳細データの合計を取得できます。
- グループ化されたデータによるフィルタリングを可能にするHAVING句を使用します。
CASE式-SQL条件ステートメント
この演算子を使用すると、特定の条件が満たされたかどうかに応じて、条件を確認し、結果を返すことができます。
CASEステートメントには2つの形式があります。
| 最初のフォーム: | 2番目の形式: |
|---|---|
| 事例
condition_1の場合 THEN return_value_1 ... condition_Nの場合 THEN return_value_N [ELSE return_value] 終了 | CASE checked_value
comparison_value_1の場合 THEN return_value_1 ... compare_value_Nの場合 THEN return_value_N [ELSE return_value] 終了 |
ここで式は値としても機能します。
例として、CASEの最初の形式を分析しましょう。
SELECT ID,Name,Salary, CASE WHEN Salary>=3000 THEN ' >= 3000' WHEN Salary>=2000 THEN '2000 <= < 3000' ELSE ' < 2000' END SalaryTypeWithELSE, CASE WHEN Salary>=3000 THEN ' >= 3000' WHEN Salary>=2000 THEN '2000 <= < 3000' END SalaryTypeWithoutELSE FROM Employees
| ID | お名前 | 給料 | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | イワノフI.I. | 5000 | ZP> = 3000 | ZP> = 3000 |
| 1001 | ペトロフP.P. | 1500 | ZP <2000 | ヌル |
| 1002 | シドロフS.S. | 2500 | 2000 <= ZP <3000 | 2000 <= ZP <3000 |
| 1003 | アンドレエフA.A. | 2000年 | 2000 <= ZP <3000 | 2000 <= ZP <3000 |
| 1004 | ニコラエフN.N. | 1500 | ZP <2000 | ヌル |
| 1005 | アレクサンドロフA.A. | 2000年 | 2000 <= ZP <3000 | 2000 <= ZP <3000 |
条件は、上から下に順番にチェックされます。 最初の条件を満たす条件に到達すると、さらなるチェックが中断され、このWHENブロックに関連するワードTHENの後に指定された値が返されます。
WHEN条件のいずれも満たされない場合、ELSEという語の後に指定された値が返されます(この場合は「ELSE BEFORE ...」を意味します)。
ELSEブロックが指定されておらず、WHEN条件が満たされない場合、NULLが返されます。
最初の形式と2番目の形式の両方で、ELSEブロックはCASEコンストラクトの最後にあります。 すべてのWHEN条件の後。
例として、CASEの2番目の形式を分析しましょう。
新しい年に、すべての従業員に報いることにし、次のスキームに従ってボーナスの額を計算するように要求したとします。
- IT部門の従業員にRFPの15%を発行します。
- 給与の10%の会計スタッフ。
- それ以外は全員がRFPの5%です。
このタスクでは、CASE式を使用したクエリを使用します。
SELECT ID,Name,Salary,DepartmentID, -- CASE DepartmentID -- WHEN 2 THEN '10%' -- 10% WHEN 3 THEN '15%' -- 15% - ELSE '5%' -- 5% END NewYearBonusPercent, -- CASE, Salary/100* CASE DepartmentID WHEN 2 THEN 10 -- 10% WHEN 3 THEN 15 -- 15% - ELSE 5 -- 5% END BonusAmount FROM Employees
| ID | お名前 | 給料 | DepartmentID | NewYearBonusPercent | ボーナス額 |
|---|---|---|---|---|---|
| 1000 | イワノフI.I. | 5000 | 1 | 5% | 250 |
| 1001 | ペトロフP.P. | 1500 | 3 | 15% | 225 |
| 1002 | シドロフS.S. | 2500 | 2 | 10% | 250 |
| 1003 | アンドレエフA.A. | 2000年 | 3 | 15% | 300 |
| 1004 | ニコラエフN.N. | 1500 | 3 | 15% | 225 |
| 1005 | アレクサンドロフA.A. | 2000年 | ヌル | 5% | 100 |
ここでは、WHEN値を使用してDepartmentID値の順次チェックを行います。 WHEN値を持つ最初のDepartmentIDに到達すると、チェックが中断され、このWHENブロックに関連するワードTHENの後に指定された値が返されます。
したがって、DepartmentIDがどのWHEN値とも一致しない場合、ELSEブロックの値が返されます。
ELSEブロックがない場合、DepartmentIDがどのWHEN値とも一致しない場合、NULLが返されます。
CASEの2番目の形式は、最初の形式を使用すると簡単に想像できます。
SELECT ID,Name,Salary,DepartmentID, CASE WHEN DepartmentID=2 THEN '10%' -- 10% WHEN DepartmentID=3 THEN '15%' -- 15% - ELSE '5%' -- 5% END NewYearBonusPercent, -- CASE, Salary/100* CASE WHEN DepartmentID=2 THEN 10 -- 10% WHEN DepartmentID=3 THEN 15 -- 15% - ELSE 5 -- 5% END BonusAmount FROM Employees
したがって、2番目の形式は、同じテスト値が各WHEN値/式と等しいかどうかを比較する必要がある場合の単純化された表記です。
ご注意 CASEの1番目と2番目の形式はSQL言語標準に含まれているため、多くのDBMSに適用できる可能性が高いです。
MS SQLバージョン2012では、IIF表記の簡略化された形式が導入されています。 2つの値のみが返される場合、CASE構文の記述を簡素化するために使用できます。 IIFの設計は次のとおりです。
IIF(, true_, false_)
つまり これは、基本的に次のCASE構造のラッパーです。
CASE WHEN THEN true_ ELSE false_ END
例を見てみましょう:
SELECT ID,Name,Salary, IIF(Salary>=2500,' >= 2500',' < 2500') DemoIIF, CASE WHEN Salary>=2500 THEN ' >= 2500' ELSE ' < 2500' END DemoCASE FROM Employees
CASE、IIF構造は、互いに入れ子にすることができます。 抽象的な例を考えてみましょう:
SELECT ID,Name,Salary, CASE WHEN DepartmentID IN(1,2) THEN 'A' WHEN DepartmentID=3 THEN CASE PositionID -- CASE WHEN 3 THEN 'B-1' WHEN 4 THEN 'B-2' END ELSE 'C' END Demo1, IIF(DepartmentID IN(1,2),'A', IIF(DepartmentID=3,CASE PositionID WHEN 3 THEN 'B-1' WHEN 4 THEN 'B-2' END,'C')) Demo2 FROM Employees
CASEおよびIIF構造は結果を返す式であるため、SELECTブロックだけでなく、式の使用を許可する他のブロック(WHEREブロックやORDER BYブロックなど)でも使用できます。
たとえば、次のように、手持ちの給与を発行するためのリストを作成するために、彼らにタスクを設定させます。
- まず、給与が2500未満の従業員は給与を受け取る必要があります
- 給与が2500以上の従業員は、二級給与を受け取ります
- これらの2つのグループ内では、名前(名前フィールド)で文字列を配置する必要があります
CASE式をORDER BYブロックに追加して、この問題を解決してみましょう。
SELECT ID,Name,Salary FROM Employees ORDER BY CASE WHEN Salary>=2500 THEN 1 ELSE 0 END, -- 2500 Name --
| ID | お名前 | 給料 |
|---|---|---|
| 1005 | アレクサンドロフA.A. | 2000年 |
| 1003 | アンドレエフA.A. | 2000年 |
| 1004 | ニコラエフN.N. | 1500 |
| 1001 | ペトロフP.P. | 1500 |
| 1000 | イワノフI.I. | 5000 |
| 1002 | シドロフS.S. | 2500 |
ご覧のように、イワノフとシドロフは最後に仕事を辞めます。
WHEREブロックでCASEを使用する抽象的な例:
SELECT ID,Name,Salary FROM Employees WHERE CASE WHEN Salary>=2500 THEN 1 ELSE 0 END=1 -- 1
IIF関数を使用して、最後の2つの例を自分でやり直すことができます。
最後に、NULL値についてもう一度思い出してください。
SELECT ID,Name,Salary,DepartmentID, CASE WHEN DepartmentID=2 THEN '10%' -- 10% WHEN DepartmentID=3 THEN '15%' -- 15% - WHEN DepartmentID IS NULL THEN '-' -- ( IS NULL) ELSE '5%' -- 5% END NewYearBonusPercent1, -- NULL , NULL CASE DepartmentID -- WHEN 2 THEN '10%' WHEN 3 THEN '15%' WHEN NULL THEN '-' -- !!! CASE ELSE '5%' END NewYearBonusPercent2 FROM Employees
| ID | お名前 | 給料 | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | イワノフI.I. | 5000 | 1 | 5% | 5% |
| 1001 | ペトロフP.P. | 1500 | 3 | 15% | 15% |
| 1002 | シドロフS.S. | 2500 | 2 | 10% | 10% |
| 1003 | アンドレエフA.A. | 2000年 | 3 | 15% | 15% |
| 1004 | ニコラエフN.N. | 1500 | 3 | 15% | 15% |
| 1005 | アレクサンドロフA.A. | 2000年 | ヌル | - | 5% |
もちろん、それは書き換えられ、どういうわけか次のようになります。
SELECT ID,Name,Salary,DepartmentID, CASE ISNULL(DepartmentID,-1) -- NULL -1 WHEN 2 THEN '10%' WHEN 3 THEN '15%' WHEN -1 THEN '-' -- , ID (-1) ELSE '5%' END NewYearBonusPercent3 FROM Employees
一般に、この場合の空想の飛行は制限されません。
例として、CASEとIIFを使用して、ISNULL関数をモデル化する方法を見てみましょう。
SELECT ID,Name,LastName, ISNULL(LastName,' ') DemoISNULL, CASE WHEN LastName IS NULL THEN ' ' ELSE LastName END DemoCASE, IIF(LastName IS NULL,' ',LastName) DemoIIF FROM Employees
CASEコンストラクトは、結果セットの値を計算するための追加のロジックを課すことができる非常に強力なSQL言語ツールです。 この部分では、CASE構造の所有権は依然として有用であるため、この部分では主に注意が払われます。
集計関数
ここでは、基本的で最も一般的に使用される集計関数のみを検討します。
| 役職 | 説明 |
|---|---|
| COUNT(*) | SELECT ... WHERE ...演算子によって受信された行の数を返します。 WHEREがない場合、すべてのテーブルエントリの数。 |
| COUNT(列/式) | 指定された列/式の値の数(null以外)を返します |
| COUNT(DISTINCT列/式) | 指定された列/式の一意の非null値の数を返します |
| SUM(列/式) | 列/式の値の合計を返します |
| AVG(列/式) | 列/式の値の平均を返します。 カウント用のNULL値は考慮されません。 |
| MIN(列/式) | 列/式の値の最小値を返します |
| MAX(列/式) | 列/式の値の最大値を返します |
集計関数を使用すると、SELECTステートメントを使用して取得した一連の行の合計値を計算できます。
例を使用して各機能を検討してください
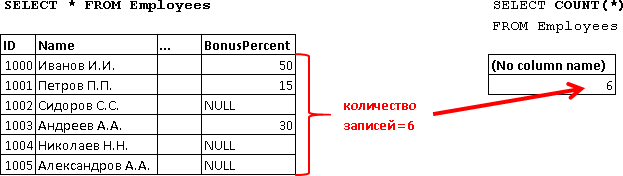
SELECT COUNT(*) [ - ], COUNT(DISTINCT DepartmentID) [ ], COUNT(DISTINCT PositionID) [ ], COUNT(BonusPercent) [- % ], MAX(BonusPercent) [ ], MIN(BonusPercent) [ ], SUM(Salary/100*BonusPercent) [ ], AVG(Salary/100*BonusPercent) [ ], AVG(Salary) [ ] FROM Employees
| 総従業員数 | 一意の部門の数 | ユニークな投稿の数 | %ボーナスが表示されている従業員の数 | 最大ボーナス率 | 最低ボーナス率 | すべてのボーナスの合計 | ボーナス平均 | RFPの平均サイズ |
|---|---|---|---|---|---|---|---|---|
| 6 | 3 | 4 | 3 | 50 | 15 | 3325 | 1108.3333333333333 | 2416.66666666667 |
わかりやすくするために、ここで例外を作成することにし、構文[...]を使用して列エイリアスを指定しました。
返された各値がどのようになったかを調べてみましょう。1つは、SELECTステートメントの基本構文の構築を思い出してください。
第一に、なぜなら リクエストでWHERE条件を指定しなかった場合、リクエストで受信した詳細データの合計が考慮されます。
SELECT * FROM Employees
つまり Employeesテーブルのすべての行。
わかりやすくするために、集計関数で使用されるフィールドと式のみを選択します。
SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent [Salary/100*BonusPercent], Salary FROM Employees
| DepartmentID | 位置ID | ボーナスパーセント | 給与/ 100 * BonusPercent | 給料 |
|---|---|---|---|---|
| 1 | 2 | 50 | 2500 | 5000 |
| 3 | 3 | 15 | 225 | 1500 |
| 2 | 1 | ヌル | ヌル | 2500 |
| 3 | 4 | 30 | 600 | 2000年 |
| 3 | 3 | ヌル | ヌル | 1500 |
| ヌル | ヌル | ヌル | ヌル | 2000年 |
これはソースデータ(詳細な行)であり、これに応じて、集約されたクエリの結果が考慮されます。
それでは、各集計値を解析しましょう。
COUNT(*) -なぜなら WHEREブロックのクエリでフィルター条件を指定しなかったため、COUNT(*)はテーブル内のレコードの合計数、つまり これは、クエリが返す行の数です。
|
COUNT(DISTINCT DepartmentID) -値3、つまり この数は、NULL値を除く、DepartmentID列で指定された一意の部門値の数に対応します。 DepartmentID列の値を調べて、同じ値を1色で色付けします(恥ずかしがらずに、すべての方法が学習に適しています)。

NULLを破棄すると、3つの一意の値(1、2、3)が取得されます。 つまり COUNT(DISTINCT DepartmentID)によって取得された値は、展開された形式で、次の選択によって表すことができます。

|
COUNT(DISTINCT PositionID) -COUNT(DISTINCT DepartmentID)について述べたのと同じ、PositionIDフィールドのみ。 PositionID列の値を見て、色を後悔しません。

|
COUNT(BonusPercent) -BonusPercent値を持つ行の数を返します。 BonusPercent IS NOT NULLのレコードの数をカウントします。 ここでは私たちにとって簡単です 一意の値を読み取る必要はなく、NULL値を持つレコードを削除するだけです。 BonusPercent列の値を取得し、すべてのNULL値を取り消します。

残りの3つの値があります。 つまり 展開された形式では、サンプルは次のように表すことができます。

なぜなら DISTINCTという単語を使用しなかった場合、BonusPercentがNULLに等しい場合を除き、BonusPercentが繰り返し存在する場合はそれらがカウントされます。 たとえば、DISTINCTがある場合とない場合の結果を比較してみましょう。 より明確にするために、DepartmentIDフィールドの値を使用します。

|
| MAX(BonusPercent)-NULL値を除外してBonusPercentの最大値を返します。
BonusPercent列の値を取得し、それらの中で最大値を探します。NULL値に注意を払わないでください。 
つまり 次の値を取得します。
|
MIN(BonusPercent)-NULL値を除いてBonusPercentの最小値を返します。 MAXの場合と同様に、NULLを無視して最小値のみを検索します。

つまり 次の値を取得します。
MIN(BonusPercent)およびMAX(BonusPercent)の視覚的表現: 
|
SUM(給与/ 100 * BonusPercent) -すべての非NULL値の合計を返します。 式の値を解析します(給与/ 100 * BonusPercent):

つまり 以下の値が合計されます。

|
AVG(給与/ 100 * BonusPercent) -値の平均を返します。 NULL式は考慮されません。 これは2番目の式に対応します。
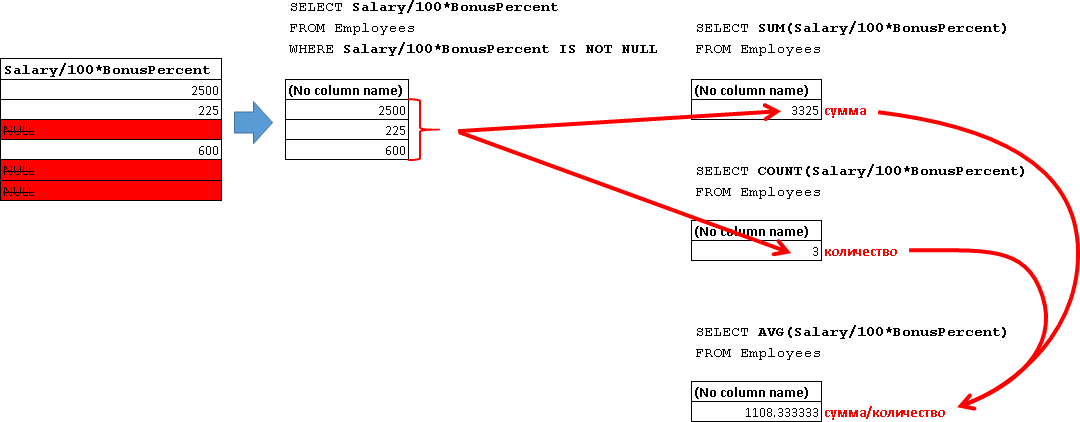
つまり この場合も、数量をカウントするときにNULL値は考慮されません。 554.166666666667を与える3番目の式のように、すべての従業員の平均を計算する必要がある場合は、NULL値のゼロへの予備変換を使用します。
|
| AVG(給与) -実際、すべては前のケースと同じです。 給与従業員がNULLの場合、考慮されません。 すべての従業員をそれぞれ考慮するために、NULL値のAVGへの予備変換を行います(ISNULL(Salary、0))
|
結果の一部を要約するには:
- COUNT(*)-SELECT ... WHERE ...演算子によって受信される行の総数を計算するために使用されます
- 上記の他のすべての集計関数では、合計を計算するときにNULL値は考慮されません
- すべての行を考慮する必要がある場合、これはAVG関数に関連性が高いため、たとえば、上記の「AVG(ISNULL(Salary、0))」のようにNULL値を処理する必要があります
したがって、WHEREブロックで集計関数を使用して追加の条件を定義すると、行ごとに条件を満たす合計のみが計算されます。 つまり 集合値は、SELECT構造を使用して取得される最終セットに対して計算されます。 たとえば、IT部門のコンテキストでのみ同じことを行います。
SELECT COUNT(*) [ - ], COUNT(DISTINCT DepartmentID) [ ], COUNT(DISTINCT PositionID) [ ], COUNT(BonusPercent) [- % ], MAX(BonusPercent) [ ], MIN(BonusPercent) [ ], SUM(Salary/100*BonusPercent) [ ], AVG(Salary/100*BonusPercent) [ ], AVG(Salary) [ ] FROM Employees WHERE DepartmentID=3 -- -
| 総従業員数 | 一意の部門の数 | ユニークな投稿の数 | %ボーナスが表示されている従業員の数 | 最大ボーナス率 | 最低ボーナス率 | すべてのボーナスの合計 | ボーナス平均 | RFPの平均サイズ |
|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 2 | 2 | 30 | 15 | 825 | 412.5 | 1666.6666666666767 |
集計関数の操作をよりよく理解するために、受け取った各値を個別に分析することをお勧めします。 ここでは、リクエストで受信した詳細データに従って、それぞれ計算を実行します。
SELECT DepartmentID, PositionID, BonusPercent, Salary/100*BonusPercent [Salary/100*BonusPercent], Salary FROM Employees WHERE DepartmentID=3 -- -
| DepartmentID | 位置ID | ボーナスパーセント | 給与/ 100 * BonusPercent | 給料 |
|---|---|---|---|---|
| 3 | 3 | 15 | 225 | 1500 |
| 3 | 4 | 30 | 600 | 2000年 |
| 3 | 3 | ヌル | ヌル | 1500 |
さらに来て。 集計関数がNULLを返す場合(たとえば、すべての従業員に給与値がない場合)、または選択にレコードがありませんが、レポートでは、この場合0を表示する必要がある場合、集計式はISNULL関数でラップできます:
SELECT SUM(Salary), AVG(Salary), -- ISNULL ISNULL(SUM(Salary),0), ISNULL(AVG(Salary),0) FROM Employees WHERE DepartmentID=10 -- ,
| (列名なし) | (列名なし) | (列名なし) | (列名なし) |
|---|---|---|---|
| ヌル | ヌル | 0 | 0 |
各集計関数の目的と計算方法を理解することは非常に重要だと思います。 SQLでは、これは合計を計算するためのメインツールです。
この場合、各集計関数が独立して動作する方法、つまり SELECTコマンドによって受信されたレコードのセット全体の値に適用されました。 さらに、これらの同じ関数を使用して、GROUP BY構文を使用してグループごとに合計を計算する方法を検討します。
GROUP BY-データのグループ化
その前に、おおよそ次のように特定の部門の合計をすでに計算していました。
SELECT COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 --
ここで、各部門のコンテキストで同じ数字を取得するように求められたとします。 もちろん、袖をまくり、各部門で同じリクエストを処理できます。 したがって、言われたとおり、4つのリクエストを作成します。
SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 -- SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 -- SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL --
その結果、4つのデータセットが取得されます。
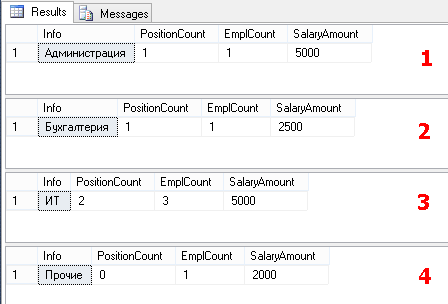
「管理」、「会計」などの定数の形式で指定されたフィールドを使用できることに注意してください。
一般に、求められたすべての数字を取得し、Excelですべてを組み合わせてディレクターに渡します。
監督は報告書を気に入っており、「平均給与に関する情報を含む別の列を追加します。」 そして、いつものように、これは非常に緊急に行われる必要があります。
どうする?! さらに、3つの部門ではなく15の部門があるとします。
そのような場合のGROUP BY句については次のとおりです。
SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg -- FROM Employees GROUP BY DepartmentID
| DepartmentID | PositionCount | 雇用者 | 給与額 | サラリャフ |
|---|---|---|---|---|
| ヌル | 0 | 1 | 2000年 | 2000年 |
| 1 | 1 | 1 | 5000 | 5000 |
| 2 | 1 | 1 | 2500 | 2500 |
| 3 | 2 | 3 | 5000 | 1666.6666666666767 |
すべて同じデータを取得しましたが、現在は1つのリクエストのみを使用しています
今のところ、部門が数字の形式で表示されているという事実に注意を払わずに、すべてを美しく表示する方法を学びます。
GROUP BY句では、複数のフィールド「GROUP BY field1、field2、...、fieldN」を指定できます。この場合、これらのフィールド「field1、field2、...、fieldN」の値を形成するグループに従ってグループ化が行われます。
たとえば、部門と役職のコンテキストでデータをグループ化します。
SELECT DepartmentID,PositionID, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID,PositionID
| DepartmentID | 位置ID | 雇用者 | 給与額 |
|---|---|---|---|
| ヌル | ヌル | 1 | 2000年 |
| 2 | 1 | 1 | 2500 |
| 1 | 2 | 1 | 5000 |
| 3 | 3 | 2 | 3000 |
| 3 | 4 | 1 | 2000年 |
次に、この例でGROUP BYがどのように機能するかを理解してみましょう。
EmployeesテーブルのGROUP BYの後にリストされているフィールドの場合、すべての一意の組み合わせはDepartmentIDとPositionIDの値によって決まります。 次のようなことが起こります:
SELECT DISTINCT DepartmentID,PositionID FROM Employees
| DepartmentID | 位置ID |
|---|---|
| ヌル | ヌル |
| 1 | 2 |
| 2 | 1 |
| 3 | 3 |
| 3 | 4 |
その後、各組み合わせに対して実行が行われ、集計関数の計算が行われます。
SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL AND PositionID IS NULL SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 AND PositionID=2 -- ... SELECT COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 AND PositionID=4
そして、これらの結果はすべて組み合わされて、単一のセットで提供されます。
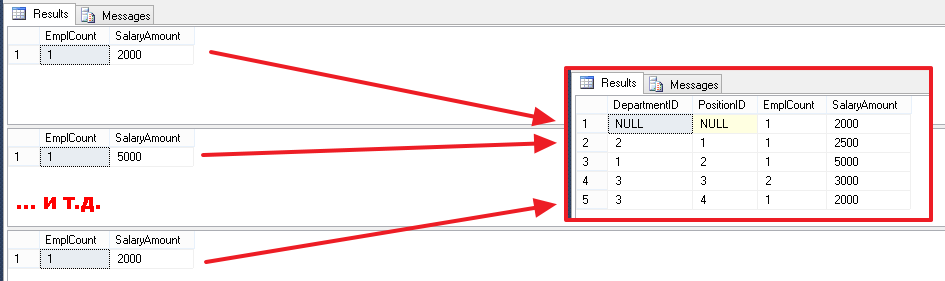
メインから、グループ化(GROUP BY)の場合、SELECTブロックの列のリストで次のことに注意する必要があります。
- GROUP BYブロックにリストされている列のみを使用できます
- GROUP BYブロックのフィールドで式を使用できます
- 定数を使用できます。なぜなら グループ化の結果には影響しません
- 他のすべてのフィールド(GROUP BYブロックにリストされていない)は、集約関数(COUNT、SUM、MIN、MAX、...)でのみ使用できます。
- SELECT列リストにGROUP BYブロックのすべての列をリストする必要はありません。
そして言われたすべてのデモンストレーション:
SELECT ' ' Const1, -- 1 Const2, -- -- CONCAT(' № ',DepartmentID) ConstAndGroupField, CONCAT(' № ',DepartmentID,', № ',PositionID) ConstAndGroupFields, DepartmentID, -- -- PositionID, -- , COUNT(*) EmplCount, -- - -- : COUNT, SUM, MIN, MAX, … SUM(Salary) SalaryAmount, MIN(ID) MinID FROM Employees GROUP BY DepartmentID,PositionID -- DepartmentID,PositionID
| Const1 | Const2 | ConstAndGroupField | ConstAndGroupFields | DepartmentID | 雇用者 | 給与額 | ミニ |
|---|---|---|---|---|---|---|---|
| 文字列定数 | 1 | 部門番号 | 部門番号、役職番号 | ヌル | 1 | 2000年 | 1005 |
| 文字列定数 | 1 | 部門番号2 | 部門番号2、ポジション番号1 | 2 | 1 | 2500 | 1002 |
| 文字列定数 | 1 | 部門番号1 | 部門番号1、位置番号2 | 1 | 1 | 5000 | 1000 |
| 文字列定数 | 1 | 部門3 | 部門番号3、ポジション番号3 | 3 | 2 | 3000 | 1001 |
| 文字列定数 | 1 | 部門3 | 部門番号3、ポジション番号4 | 3 | 1 | 2000年 | 1003 |
また、グループ化はフィールドだけでなく式でも実行できることに注意してください。たとえば、生年ごとに従業員ごとにデータをグループ化します。
SELECT CONCAT(' - ',YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday)
より複雑な式の例を考えてみましょう。例として、出生年までに従業員を卒業します。
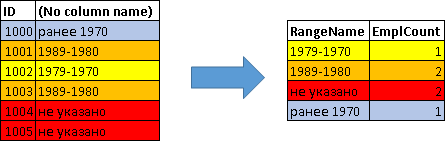
SELECT CASE WHEN YEAR(Birthday)>=2000 THEN ' 2000' WHEN YEAR(Birthday)>=1990 THEN '1999-1990' WHEN YEAR(Birthday)>=1980 THEN '1989-1980' WHEN YEAR(Birthday)>=1970 THEN '1979-1970' WHEN Birthday IS NOT NULL THEN ' 1970' ELSE ' ' END RangeName, COUNT(*) EmplCount FROM Employees GROUP BY CASE WHEN YEAR(Birthday)>=2000 THEN ' 2000' WHEN YEAR(Birthday)>=1990 THEN '1999-1990' WHEN YEAR(Birthday)>=1980 THEN '1989-1980' WHEN YEAR(Birthday)>=1970 THEN '1979-1970' WHEN Birthday IS NOT NULL THEN ' 1970' ELSE ' ' END
| 範囲名 | 雇用者 |
|---|---|
| 1979-1970 | 1 |
| 1989-1980 | 2 |
| 指定なし | 2 |
| 1970年前 | 1 |
つまり この場合、グループ化は各従業員に対して以前に計算されたCASE式によって行われます。
SELECT ID, CASE WHEN YEAR(Birthday)>=2000 THEN ' 2000' WHEN YEAR(Birthday)>=1990 THEN '1999-1990' WHEN YEAR(Birthday)>=1980 THEN '1989-1980' WHEN YEAR(Birthday)>=1970 THEN '1979-1970' WHEN Birthday IS NOT NULL THEN ' 1970' ELSE ' ' END FROM Employees
そしてもちろん、GROUP BYブロック内のフィールドと式を組み合わせることができます。
SELECT DepartmentID, CONCAT(' - ',YEAR(Birthday)) YearOfBirthday, COUNT(*) EmplCount FROM Employees GROUP BY YEAR(Birthday),DepartmentID -- SELECT ORDER BY DepartmentID,YearOfBirthday --
元のタスクに戻りましょう。すでにご存知のとおり、ディレクターはこのレポートを本当に気に入っており、会社の変化を監視できるように、毎週報告するように依頼しました。Excelで毎回部門のデジタル値をその名前に割り込まないために、既に持っている知識を使用して、要求を絞り込みます。
SELECT CASE DepartmentID WHEN 1 THEN '' WHEN 2 THEN '' WHEN 3 THEN '' ELSE '' END Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg -- FROM Employees GROUP BY DepartmentID ORDER BY Info -- Info
| 情報 | PositionCount | 雇用者 | 給与額 | サラリャフ |
|---|---|---|---|---|
| 運営 | 1 | 1 | 5000 | 5000 |
| 簿記 | 1 | 1 | 2500 | 2500 |
| IT | 2 | 3 | 5000 | 1666.6666666666767 |
| その他 | 0 | 1 | 2000年 | 2000年 |
外からは怖いように見えるかもしれませんが、元の状態よりはまだましです。欠点は、新しい部門とその従業員が設立された場合、新しい部門の従業員が「その他」グループに分類されないようにCASE式を追加する必要があることです。
しかし、何も、時間の経過とともに、データベース内の新しいデータの外観に依存せずに動的に選択できるように、すべてを美しく行う方法を学習しません。少し先に進んで、どのような種類のクエリを作成しようとしているかを示します。
SELECT ISNULL(dep.Name,'') DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg -- FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID GROUP BY emp.DepartmentID,dep.Name ORDER BY DepName
一般的に、心配しないでください-誰もが簡単なものから始めました。とりあえず、GROUP BY構文の本質を理解する必要があります。
最後に、GROUP BYを使用して概要レポートを作成する方法を見てみましょう。
たとえば、部門ごとに集計表を表示し、役職ごとに従業員が受け取る賃金の合計が計算されるようにします。
SELECT DepartmentID, SUM(CASE WHEN PositionID=1 THEN Salary END) [], SUM(CASE WHEN PositionID=2 THEN Salary END) [], SUM(CASE WHEN PositionID=3 THEN Salary END) [], SUM(CASE WHEN PositionID=4 THEN Salary END) [ ], SUM(Salary) [ ] FROM Employees GROUP BY DepartmentID
| DepartmentID | 会計士 | 取締役 | プログラマー | 上級プログラマー | 部門合計 |
|---|---|---|---|---|---|
| ヌル | ヌル | ヌル | ヌル | ヌル | 2000年 |
| 1 | ヌル | 5000 | ヌル | ヌル | 5000 |
| 2 | 2500 | ヌル | ヌル | ヌル | 2500 |
| 3 | ヌル | ヌル | 3000 | 2000年 | 5000 |
つまり集計関数内で任意の式を自由に使用できます。
もちろん、IIFを使用して書き換えることができます。
SELECT DepartmentID, SUM(IIF(PositionID=1,Salary,NULL)) [], SUM(IIF(PositionID=2,Salary,NULL)) [], SUM(IIF(PositionID=3,Salary,NULL)) [], SUM(IIF(PositionID=4,Salary,NULL)) [ ], SUM(Salary) [ ] FROM Employees GROUP BY DepartmentID
ただし、IIFの場合、NULLを明示的に指定する必要があります。NULLは、条件が満たされない場合に返されます。
同様のケースでは、もう一度NULLを書き込むよりも、ELSEブロックなしでCASEを使用することを好みます。しかし、これはもちろん議論の余地のない味の問題です。
また、集計中の集計関数では、NULL値は考慮されないことに注意してください。
統合するには、詳細なリクエストで受信データの独立した分析を行います。
SELECT DepartmentID, CASE WHEN PositionID=1 THEN Salary END [], CASE WHEN PositionID=2 THEN Salary END [], CASE WHEN PositionID=3 THEN Salary END [], CASE WHEN PositionID=4 THEN Salary END [ ], Salary [ ] FROM Employees
| DepartmentID | 会計士 | 取締役 | プログラマー | 上級プログラマー | 部門合計 |
|---|---|---|---|---|---|
| 1 | ヌル | 5000 | ヌル | ヌル | 5000 |
| 3 | ヌル | ヌル | 1500 | ヌル | 1500 |
| 2 | 2500 | ヌル | ヌル | ヌル | 2500 |
| 3 | ヌル | ヌル | ヌル | 2000年 | 2000年 |
| 3 | ヌル | ヌル | 1500 | ヌル | 1500 |
| ヌル | ヌル | ヌル | ヌル | ヌル | 2000年 |
NULLの代わりにゼロを表示したい場合は、集約関数によって返された値を処理できることを思い出してください。 例:
SELECT DepartmentID, ISNULL(SUM(IIF(PositionID=1,Salary,NULL)),0) [], ISNULL(SUM(IIF(PositionID=2,Salary,NULL)),0) [], ISNULL(SUM(IIF(PositionID=3,Salary,NULL)),0) [], ISNULL(SUM(IIF(PositionID=4,Salary,NULL)),0) [ ], ISNULL(SUM(Salary),0) [ ] FROM Employees GROUP BY DepartmentID
| DepartmentID | 会計士 | 取締役 | プログラマー | 上級プログラマー | 部門合計 |
|---|---|---|---|---|---|
| ヌル | 0 | 0 | 0 | 0 | 2000年 |
| 1 | 0 | 5000 | 0 | 0 | 5000 |
| 2 | 2500 | 0 | 0 | 0 | 2500 |
| 3 | 0 | 0 | 3000 | 2000年 | 5000 |
実用的な目的で、次のことができます。
- , , CASE DepartmentID SELECT
- ORDER BY
通常、この形式のデータが使用されるため、集計関数を使用するGROUP BYのケチは、データベースから集計データを取得するために使用される主要なツールの1つです。通常、詳細なデータ(シート)ではなく、概要レポートを提供する必要があります。そしてもちろん、これはすべて、基本設計の知識を中心に展開します。何かを要約(集約)する前に、まず「SELECT ... WHERE ...」を使用して正しく選択する必要があります。
ここでは練習が重要な場所です。したがって、学習するのではなく、SQL言語を理解することを目標に設定する場合、練習、練習、練習、思いつくさまざまなオプションを並べ替えます。
最初の段階で、取得した集計データの正確性が不明な場合は、集計が実行されるすべての値を含む詳細な選択を行います。そして、これらの詳細データに従って、計算の正確さを手動で確認します。この場合、Excelを使用すると非常に役立ちます。
この点に到達したとしましょう
あなたがSELECTクエリの書き方を学ぶことにした会計士のS. Sidorovであると仮定します。
あなたはすでにこのチュートリアルをこの時点まで読んでおり、すでに自信を持って上記の基本構成をすべて使用していると仮定します。あなたは方法を知っています:
- 1つのテーブルからWHERE句によって詳細データを選択します
- 1つのテーブルから集計関数とグループ化を使用する方法を知っている
職場ではすでにすべてを知っていると考えられていたため、データベースへのアクセス権が与えられ(これは時々起こります)、今度は同じ週間レポートを開発して引き出しました。
はい。ただし、複数のテーブルからクエリを作成する方法がまだわからないことを考慮していませんでした。このようなことをする方法がわかりません:
SELECT emp.*, -- Employees dep.Name DepartmentName, -- Name Departments pos.Name PositionName -- Name Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID
| ID | お名前 | 誕生日 | ... | 給料 | ボーナスパーセント | 部署名 | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | イワノフI.I. | 1955年2月19日 | 5000 | 50 | 運営 | 監督 | |
| 1001 | ペトロフP.P. | 1983年12月3日 | 1500 | 15 | IT | プログラマー | |
| 1002 | シドロフS.S. | 1976/07/07 | 2500 | ヌル | 簿記 | 会計士 | |
| 1003 | アンドレエフA.A. | 1982年4月17日 | 2000年 | 30 | IT | 上級プログラマー | |
| 1004 | ニコラエフN.N. | ヌル | 1500 | ヌル | IT | プログラマー | |
| 1005 | アレクサンドロフA.A. | ヌル | 2000年 | ヌル | ヌル | ヌル |
あなたはどのようにあなたが方法を知らないという事実にもかかわらず、私を信じて、あなたはよくやった、そしてすでに多くを達成した。
それで、現在の知識をどのように活用して、より生産的な結果を得ることができますか?!私たちは集合的な精神の力を利用します-私たちはあなたのために働くプログラマー、つまりアンドレエフA.A.、ペトロフP.P.またはNikolaev N.N.に、パフォーマンスの記述を依頼してください(VIEWまたは単に「表示」。したがって、従業員テーブルのメインフィールドに加えて、次のフィールドも返されます。 「部門の名前」と「役職の役職」。これは、イワノフI.I.
なぜならすべてを正しく説明すると、ITスペシャリストはすぐに彼らが何を求めているかを理解し、特にViewEmployeesInfoというプレゼンテーションを作成しました。
次のコマンドが表示されないことを想像してください。なぜなら、IT専門家がそれを行います。
CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, -- Employees dep.Name DepartmentName, -- Name Departments pos.Name PositionName -- Name Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID
つまりあなたにとって、このすべてのテキストは、怖くて理解できないものの、舞台裏に残り、ITスペシャリストは、ビュー名「ViewEmployeesInfo」のみを提供します。
これで、通常のテーブルと同様に、このビューで作業できます。
SELECT * FROM ViewEmployeesInfo
| ID | お名前 | 誕生日 | ... | 給料 | ボーナスパーセント | 部署名 | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | イワノフI.I. | 1955年2月19日 | 5000 | 50 | 運営 | 監督 | |
| 1001 | ペトロフP.P. | 1983年12月3日 | 1500 | 15 | IT | プログラマー | |
| 1002 | シドロフS.S. | 1976/07/07 | 2500 | ヌル | 簿記 | 会計士 | |
| 1003 | アンドレエフA.A. | 1982年4月17日 | 2000年 | 30 | IT | 上級プログラマー | |
| 1004 | ニコラエフN.N. | ヌル | 1500 | ヌル | IT | プログラマー | |
| 1005 | アレクサンドロフA.A. | ヌル | 2000年 | ヌル | ヌル | ヌル |
なぜなら これで、レポートに必要なすべてのデータが1つの「テーブル」(ビュー)に格納され、毎週のレポートを簡単にやり直すことができます。
SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName
| 部署名 | PositionCount | 雇用者 | 給与額 | サラリャフ |
|---|---|---|---|---|
| ヌル | 0 | 1 | 2000年 | 2000年 |
| 運営 | 1 | 1 | 5000 | 5000 |
| 簿記 | 1 | 1 | 2500 | 2500 |
| IT | 2 | 3 | 5000 | 1666.6666666666767 |
これで、フィールド内のすべての部署の名前とリクエストが動的になり、新しい部署とその従業員が追加されると変更されます。今は何もやり直す必要はありませんが、リクエストを処理して結果をディレクターに返すために週に1回行う必要があります。
つまりこの場合、何も変更されていないかのように、必要なすべてのデータを返す同じテーブル(ViewEmployeesInfoビューで言う方が正しい)を引き続き使用します。IT専門家の支援のおかげで、DepartmentNameおよびPositionNameマイニングの詳細がブラックボックスに残されました。つまりビューは通常のテーブルと同じように見えますが、これはEmployeesテーブルの拡張バージョンと考えてください。
たとえば、ステートメントを作成して、すべてが本当に言ったとおりであると確信できるようにしましょう(サンプル全体が1つのビューから来ている)。
SELECT ID, Name, Salary FROM ViewEmployeesInfo WHERE Salary IS NOT NULL AND Salary>0 ORDER BY Name
| ID | お名前 | 給料 |
|---|---|---|
| 1005 | アレクサンドロフA.A. | 2000年 |
| 1003 | アンドレエフA.A. | 2000年 |
| 1000 | イワノフI.I. | 5000 |
| 1004 | ニコラエフN.N. | 1500 |
| 1001 | ペトロフP.P. | 1500 |
| 1002 | シドロフS.S. | 2500 |
このリクエストをご理解ください。
場合によっては表現を使用することで、基本的なSELECTクエリの作成に精通しているユーザーの境界を大幅に拡大することができます。この場合、ビューはユーザーに必要なすべてのデータを含むフラットテーブルです(OLAPを理解している人は、これを事実と測定値を持つOLAPキューブのおおよその類似性と比較できます)。
ウィキペディアのクリッピング。SQLはエンドユーザーツールとして考えられていましたが、最終的には非常に複雑になり、プログラマーのツールになりました。
ご覧のように、親愛なるユーザーにとって、SQL言語はもともとあなたのためのツールとして考えられていました。だから、すべてがあなたの手と欲望の中にあり、あなたの手を離さないでください。
HAVING-グループ化されたデータにサンプリング条件を課す
実際、グループ化とは何かを理解していれば、HAVINGに複雑なことはありません。HAVINGはWHEREに多少似ていますが、WHERE条件が詳細データに適用される場合のみ、HAVING条件は既にグループ化されたデータに適用されます。このため、HAVINGブロックの条件下では、グループ化に含まれるフィールドを持つ式、または集約関数に囲まれた式を使用できます。
例を考えてみましょう:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000
| DepartmentID | 給与額 |
|---|---|
| 1 | 5000 |
| 3 | 5000 |
つまりこのリクエストは、すべての従業員の合計給与が3000を超える部門(つまり、「SUM(給与)> 3000」。
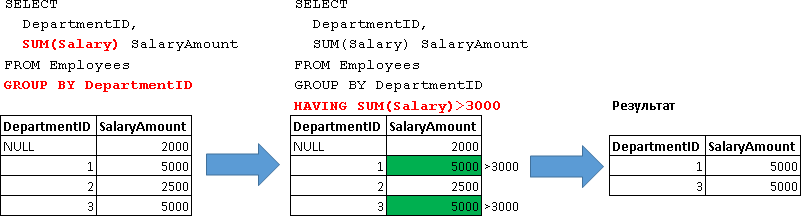
つまり ここでは、まずグループ化が行われ、すべての部門のデータが計算されます。
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1.
そして、すでにHAVINGブロックで指定された条件がこのデータに適用されています:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. HAVING SUM(Salary)>3000 -- 2.
HAVING条件では、AND、OR、およびNOT演算子を使用して複雑な条件を構築することもできます。
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- 2-
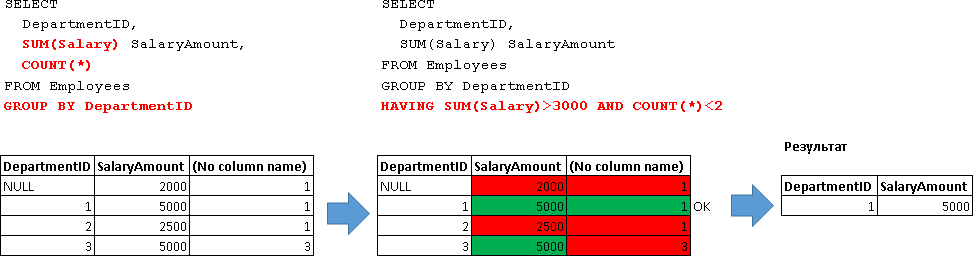
ここでわかるように、集計関数(「COUNT(*)」を参照)はHAVINGブロックでのみ指定できます。
したがって、HAVING条件に該当する部門の番号のみを表示できます。
SELECT DepartmentID FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 AND COUNT(*)<2 -- 2-
GROUP BYに含まれるフィールドでHAVING条件を使用する例:
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID -- 1. HAVING DepartmentID=3 -- 2.
これは単なる例です この場合、検証はWHERE条件を介して行う方が論理的です。
SELECT DepartmentID, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 -- 1. GROUP BY DepartmentID -- 2.
つまり 最初に従業員を部門3でフィルタリングしてから、計算を実行します。
ご注意 実際、これら2つのクエリは異なって見えるという事実にもかかわらず、DBMSオプティマイザーはそれらを同じ方法で実行できます。
これで、HAVING状態に関する話の終わりになると思います。
まとめると
2番目と3番目の部分で得られたデータを要約し、調査した各構造の特定の場所を検討し、それらの実装の順序を示します。
| 建設/ブロック | 実行順序 | 実行する機能 |
|---|---|---|
| SELECTリターン式 | 4 | リクエストで受信したデータを返す |
| ソースから | 0 | 私たちの場合、これはテーブルのすべての行です。 |
| WHEREソースフェッチ条件 | 1 | 条件に一致する行のみが選択されます |
| GROUP BYグループ化式 | 2 | 指定されたグループ化式によってグループを作成します。SELECTまたはHAVINGブロックで使用されるこれらのグループの集計値の計算 |
| グループ化されたデータによるフィルタリング | 3 | グループ化されたデータに重畳されたフィルタリング |
| ORDER BY結果のソート式 | 5 | 指定した式でデータを並べ替える |
もちろん、2番目のパートで学習したDISTINCT文とTOP文をグループ化されたデータに適用することもできます。
この場合のこれらの提案は、最終結果に適用されます。
SELECT TOP 1 -- 6. SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID HAVING SUM(Salary)>3000 ORDER BY DepartmentID -- 5.
| 給与額 |
|---|
| 5000 |
SELECT DISTINCT -- SalaryAmount SUM(Salary) SalaryAmount FROM Employees GROUP BY DepartmentID
| 給与額 |
|---|
| 2000年 |
| 2500 |
| 5000 |
どのようにしてこれらの結果を取得し、自分自身を分析します。
おわりに
このパートで設定した主な目標は、集約関数とグループ化の本質を明らかにすることです。
基本設計により必要な詳細データを取得できる場合、集計関数およびこれらの詳細データへのグループ化の適用により、それらから要約データを取得する機会が与えられました。ここでわかるように、すべてが重要です。一方は他方に基づいています-基本設計の知識がなければ、たとえば、結果を計算する必要があるデータを正しく選択することはできません。
ここでは、初心者に最も重要な構造に焦点を当て、不必要な情報で構造をオーバーロードしないように、基本のみを意図的に示します。基本構造のしっかりした理解(以降の部分で引き続き説明します)は、RDBからデータを選択するほとんどすべてのタスクを解決する機会を提供します。SELECTステートメントの基本構造は、ほとんどすべてのDBMSに同じ形式で適用できます(違いは主に、たとえば、文字列や時間などを処理するための関数の実装の詳細にあります)。
その後、データベースに関する確かな知識があれば、次のようなSQL言語のさまざまな拡張機能を自分で簡単に学ぶことができます。
- GROUP BY ROLLUP(...)、GROUP BY GROUPING SETS(...)、...
- ピボット、アンピボット
- など
このチュートリアルの一環として、これらの拡張機能について話さないことにしました。また、SQL言語の基本構造のみを所有している知識がなくても、非常に広範なタスクを解決できます。 SQL言語の拡張は、本質的に特定の範囲の問題を解決するのに役立ちます。特定のクラスの問題をよりエレガントに解決できるようにします(ただし、速度や消費リソースの点で必ずしも効率的ではありません)。
SQLの最初のステップを実行している場合、基本的な構造の研究に主に焦点を当てます。ベースを所有することで、他のすべてが理解しやすくなり、また独立したものになります。まず、SQL言語の機能を包括的に理解するにはどうすればよいでしょうか。どんな種類の操作でデータを実行できますか。初心者に情報をまとめて伝えることは、最も重要な(鉄の)構造のみを表示するもう1つの理由です。
SQL言語の学習と理解に幸運を。
パート4-habrahabr.ru/post/256045