- インテル®データ分析アクセラレーションライブラリ(インテル®DAAL) -C ++およびJavaデータ分析ソリューション(統計、機械学習など)。
- インテル®Advisor XE 2016ベータの一部としての新しいベクトル化アドバイザー 。SIMD命令のコードを最適化します。 ベクトル化。
- MPIプログラムのパフォーマンスの全体的な評価をすばやく行うためのMPIパフォーマンススナップショット 。
ベータ版は一般公開されており、無料でプログラムは6月23日まで有効ですが、ライセンスは2015年9月25日まで有効です。ベータ版を入手するには、 ここで登録する必要があります 。
この記事は、新しい機能のレビューに専念します。個々の製品については、後続のブログで詳しく説明します。興味のあることについてのコメントを書いてください。
インテル®Advisor XE 2016ベータ
インテル®Advisor XEは、伝統的にスレッドのプロトタイプ同時実行プロトタイプです。 バージョン2016ベータ版では、実際には2つの大きな製品に分割されています。
- スレッドアシスタント-以前はIntel Advisorにあったすべてのものに、いくつかの改善が加えられました。
- ベクトル化アドバイザーは、SIMDプログラムを分析するためのまったく新しいツールです。
ベクトル化アドバイザーの主な機能:
- サイクルのベクトル化に関するすべての情報は、1つの場所で収集されます。CPU時間、コンパイラからの診断、使用される命令の分析、データ型などです。 これにより、重要なことに集中することができます-最もホットなサイクルを最適化する。
- 反復(トリップカウント)および呼び出し(呼び出しカウント)サイクルの数をカウントします。
- 反復的な依存関係を検索する
- メモリアクセスパターン分析
- 収集されたデータに基づく最適化の推奨事項 。
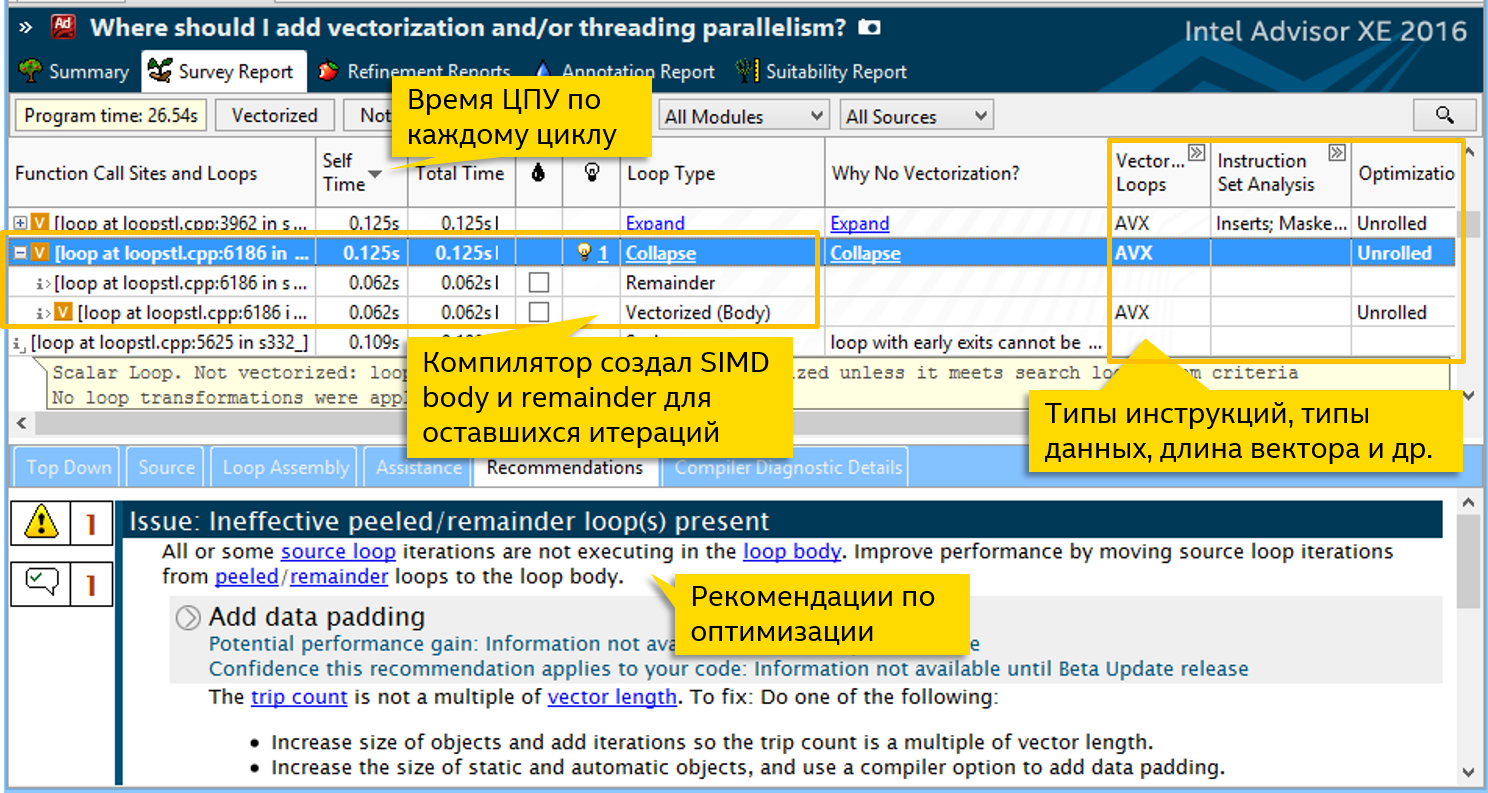
ベクトル化アドバイザーについては、次のブログで詳しく説明します。
Intel®Data Analytics Acceleration Library(Intel®DAAL)2016 Beta
さまざまな段階で「ビッグデータ」を操作するための最適化されたライブラリ:ソースからのデータの受信、前処理、変換、データマイニング、モデリング、検証、意思決定。
- データマイニング -データの類似性計算、マトリックス分解(SVD、QR、コレスキー)、統計モーメント、変分および共分散マトリックス、1次元および多次元の外れ値および連想ルールの検索。
- 教師ありと教師なしの機械学習法 :線形回帰、単純ベイズ分類器、ブースティングアルゴリズム(AdaBoost、LogitBoost、BrownBoost)、サポートベクトル法、k平均クラスタリング、尤度関数など
- ファイルおよびメモリ内のCSV、MySQL、HDFS、Apache SparkのResilient Distributed Dataset(RDD)オブジェクトなど、 ローカルおよび分散データソースのサポート 。
- データの圧縮と解凍 -Intel DAALユーティリティは、ZLIB、LZO、RLE、およびBZIP2の効率的な実装を提供します。
- 効果的な通信のためのデータのシリアル化と逆シリアル化 。
コンパイラ
正式名称は、Intel®Parallel Studio XE 2016 Beta、Composer Editionです。 この製品は、コンパイラとライブラリを組み合わせています。 インテル®コンパイラーは、サポートされている一連の標準を拡張します。
OpenMP * 4.0:
-
simdlen
およびsafelen
forループ、 - 配列縮約(Fortran)、
- ユーザー定義の削減(C / C ++)、
-
omp simd
collapse(N)
オプションcollapse(N)
。
OpenMP * 4.1 TR 3:
-
omp target [enter | exit ] data
をomp target [enter | exit ] data
非構造化データの割り当てomp target [enter | exit ] data
omp target [enter | exit ] data
-
omp task
nowait
オプションをomp task
した非同期オフライン -
omp task
dependオプションをomp task
した依存関係でのオフロード -
always
map
修飾子をdelete
しmap
C / C ++標準:
- C11:Unicode文字列、C11匿名
_Alignas, _Alighof, _Static_assert, _Thread_local, _Noreturn
キーワード_Alignas, _Alighof, _Static_assert, _Thread_local, _Noreturn
、および_Generic
。 - C ++ 14:汎用ラムダ、汎用ラムダキャプチャ、桁区切り記号、[[非推奨]]属性、関数の戻り値型の推測、およびメンバーの初期化。
Fortranコンパイラは、サブモジュールのサポート、初期化されていない変数の実行時チェックの改善(オプション
[Q]init
)、IMPURE ELEMENTALのサポートの追加(F2008)、Cの相互運用性の改善(F2015)を開始しました。
インテル®VTune™Amplifier XE 2016ベータ版
VTune™Amplifier XEの新しいバージョンは、OpenMPおよびMPIアプリケーションのプロファイル機能を拡張しました。 OpenMPの場合、このツールは並列領域に関する統計を提供し、最適化の可能性が最も高い領域を強調表示します。 VTune Amplifierは、OpenMPの非効率性の主な原因(負荷の不均衡、オーバーヘッド、同期など)を認識します。OpenMP分析の詳細はすでに記述されています 。

VTune Amplifierは、MPIアプリケーションのプロファイル機能を大幅に拡張しました。最も興味深いのは、ハイブリッド、MPI + OpenMPです。 つまり OpenMPとMPI通信の不均衡を同時に分析できます。

ボトムアップテーブルでは、MPIプロセスとその中のOpenMPリージョン、およびリージョン内の個々のバリア(ループなど)ごとにグループ化できます。

インテル®HDグラフィックスで実行されているOpenCLプログラムのパフォーマンスの分析は、GPUハードウェアブロックとその負荷(コンピューティングコアとデータトラフィックの忙しさ)を明確に見ることができる新しい「アーキテクチャ図」によりさらに便利になります。

VTune Amplifier XEに対するその他の変更:
- サンプリング統計の信頼性を評価するために、一般探査分析を更新しました。
- 「タスクとフレーム」の代わりに新しいタブ「プラットフォーム」
- Linuxでドライバーなしでハードウェアイベントを収集する
インテル®MPIライブラリー5.1ベータ
- MPI v3.0標準の主な機能のサポート。
- Intel®True Scale Fabricのサポートを追加しました。
-
-use-app-topology
オプションを使用すると、Hydraは以前に収集された統計と動的に識別されたクラスタートポロジに基づいてMPIプロセスの配置を調整できます。 -
mpitune
の--fast
オプションは、ユーザーアプリケーションの代わりにIMBベンチマークを起動することにより、自動構成をmpitune
します。 IMBはプログラムのパターンを(MPI通信に関して)繰り返し、プログラムのチューニングはプログラム自体のチューニングに近くなりますが、実際の計算は実行されず、チューニング時間は短縮されます。 -
--rank-placement
オプションは、通信パターンに基づいて特定のクラスタートポロジのMPI設定を最適化します。
新しい
-gtool
オプションを使用
-gtool
と、MPIアプリケーションのアナライザーツールを便利に実行でき
-gtool
。 たとえば、ベクトル化分析のためのベクトル化アドバイザー:
mpirun -n 4 -gtool "advixe-cl -collect survey:2,3" ./your_app
または、個々のランクのパフォーマンスを分析するVTuneアンプ:
mpirun -n 4 -gtool "amplxe-cl -collect hostpots:2,3" ./your_app
この例では、分析は4つのランクのうちランク2および3でのみ実行されることに注意してください。 つまり 個々のプロセスを選択的にプロファイルできます。
Intel®Trace Analyzer and Collector 9.1ベータ版
主な革新はMPIパフォーマンススナップショットです。 このツールは、トップレベルのパフォーマンス評価を迅速に行うために使用されます。アプリケーションのスケーリング方法、MPI、OpenMP、およびコンピューティング負荷のバランス。

ハイブリッドアプリケーション分析の改善:インテル®トレースアナライザーでは、インテル®MPIライブラリの新しい<code-gtoolオプションを使用して、MPIランクを選択し、VTune™Amplifierコマンドラインを生成できます。 つまり まず、インテル®トレースアナライザーで問題のあるMPIプロセスを特定し、次にVTune™アンプで詳細に調査します。

まとめ
インテル®Parallel Studio 2016ベータ版は、さまざまな方法で一連の重要な新機能を提供します。
- ベクトル化、SIMD命令の使用の最適化(Intel Advisor XE)
- ビッグデータ分析(Intel®DAAL)
- MPIおよびOpenMP上のハイブリッドHPCアプリケーションの統合分析(Intel Trace Analyzer and Collector、VTune Amplifier XE)
- GPU分析(VTune Amplifier XE)
- 新しい標準(インテル®コンパイラー、インテル®MPI)
これの一部は、HPC開発者向けの従来のセットの開発ですが、多くはマルチメディアやデータ分析などの他の分野に拡大しています。
これは簡単な概要でしたが、次の投稿でさらに詳しく説明します-そもそも何が面白いのか教えてください。
Intel®Parallel Studio XE 2016 Betaに登録します。