
私たちの多くは、大学や自宅でプログラミングを勉強しているときに、C / C ++でこれを行いました。 もちろん、それはすべてプログラミング言語の知識が始まった時間に依存します。 誰かがFortranで始め、他の人がBasicまたはDelphiで始めたとしましょうが、C / C ++で厄介な道を始めたプログラマの割合が最大であることを認識する価値があります。 なぜ私はこれをすべてしているのですか? 新しい言語を学習し、その言語でコードを書くという課題に直面するとき、私たちはしばしば「ベース」言語でそれを書く方法に依存します。 質問を絞り込みます。Fortranで何かを書く必要がある場合は、Cでどのように実装するかを思い出して、類推してください。 再び言語の微妙さに直面しましたが、それは絶対に機能しないアルゴリズムと私にエスカレートした大きな問題につながりました、私は個人的に遭遇したCと比較してFortran言語の可能な限り多くのニュアンスを見つけることにしました(Fortran 90/95)。 これは一種の「予想外の人々」であり、明らかにあなたが見ることを計画していなかったが、彼らは強打し、浮上した!
もちろん、構文については説明しません-各言語では異なります。 私はすべてを「逆さまに」変えることができるグローバルなことについて話そうとします。 行こう!
関数に引数を渡す
Cでのこのようなコードでは、呼び出し元のメイン関数で変数aの値を変更することは不可能であることを皆覚えています。
void modify_a(int a) { a = 6; } int main() { int a = 5; modify_a(a); return 0; }
そうです-Cの関数への引数は値で渡されるため、 modify_a関数のaの変更は失敗します。 これを行うには、参照によって引数を渡す必要があり、その後、呼び出された関数から渡された同じaを使用します。
そのため、「予期しない」「回数」の数は、Fortranでは逆のことが当てはまります。 引数は参照によって関数に渡され、そのようなコードはaの値を完全に変更します。
a = 5 call modify_a (a) contains subroutine modify_a (a) integer a a = 6 end subroutine modify_a end
私は誰もがこの事実の無知から生じるかもしれない問題を理解していると思います。 さらに、この特異性は、特にポインターを操作する場合など、多くの場所で現れますが、これについては別の議論があります。
配列を操作する
デフォルトでは、Fortranの配列のインデックス付けは、Cのように0ではなく1から始まります。つまり、 real a(10)は1〜10の配列を与え、C floatでは[10]は0〜9になります。 ただし、Fortran では配列を実数a(0:100)として定義できます。
さらに、多次元配列はFortranメモリの列に格納されます。 したがって、通常の行列

次のようにメモリ内にあります。
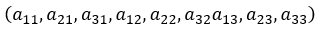
特にライブラリを介してCの関数との間で配列をやり取りする場合は、配列を操作するときにこのことを忘れないでください。
宣言されていない変数
暗黙のデータ型の概念があるため、Fortranは明示的に宣言していないデータをデフォルトで誓います。 それは古くから行われており、アイデアはすぐにデータを操作できることであり、そのタイプは名前の最初の文字に応じて決定されます。
Cコンパイラでコードをコンパイルしようとすると、予想どおりにエラー'b:undeclared identifier'が生成されます 。
int main() { b = 5; }
Fortranでは、強打で動作します。
i = 5 end
コード内の絶対に多様なエラーの数は、これに起因する可能性があります。 したがって、コードにIMPLICIT NONEを追加することを忘れないでください。これにより、暗黙的な宣言を伴う「ゲーム」が禁止されます。
implicit none i = 5 end
そして、すぐにエラーが表示されます。 エラー#6404:この名前にはタイプがなく、明示的なタイプが必要です。 [I]
ところで、Fortran言語では大文字と小文字が区別されないため、変数aとAは同一です。 しかし、これは私が話さないと約束した構文です。
ローカル変数の初期化
そのような初期化は悪いように思われるでしょう:
real :: a = 0.0
そして、これとどう違うのですか:
real a a = 0.0
Cの開発者にとって予想外の驚き-Fortranでは、これには根本的な違いがあります! ローカル変数が宣言時に初期化されると、 SAVE属性が暗黙的に適用されます。 この属性は何ですか? 変数が(明示的または暗黙的に) SAVEとして宣言されている場合、その変数は静的です。つまり、変数が初めて関数に入ったときにのみ初期化されます。 関数への後続のエントリは以前の値を保持します。 そして、これは我々が期待するものではないかもしれません。 ヒントとして、このような初期化を避け、必要に応じてSAVE属性を明示的に使用してください。 ところで、コンパイラーには個別のオプション-saveがあり、デフォルト設定(スタックの強調表示)を変更し、すべての変数を静的にすることができます(再帰関数およびAUTOMATICとして明示的に宣言されている変数を除く)。
ポインタ
はい、Fortranにはポインターの概念もあります。 しかし、それらのメモリはメモリなしで動的に割り当てることができ、引数は参照によって渡されるため、あまり使用されません。 Fortranではポインターメカニズム自体の動作が異なることに注意する価値があります。そのため、これについて詳しく説明します。
ここでは、オブジェクトへのポインタを作成することはできません-特別な方法で宣言されたオブジェクトのみにポインタを作成してください。 たとえば、次のように:
real, target :: a real, pointer :: pa pa => a
演算子=>を使用して、ポインターpaをオブジェクトaに関連付けます。 =>の代わりに割り当て操作を実行しないでください。 すべてが正常にアセンブルされますが、実行時に落ちます。 そのため、単純にCにポインターを割り当てることに慣れている人は、毎回=の代わりに= >を書かなければなりません。 最初は忘れますが、それから参加します。
ポインターをオブジェクトに関連付けたくない場合は、 nullify(pa)を使用します-これはポインターの一種の初期化です。 単にポインタを宣言するだけでは、Fortranでのステータスは未定義であり、オブジェクトとの関連付け( 関連付けられた(pa) )をチェックする関数は正しく動作しません。
ところで、Cのように、同じ型の変数にポインターを関連付けることができないのはなぜですか? まず、標準化委員会でそれがとても欲しかった。 冗談です。 ほとんどの場合、すべてが潜在的なエラーに対するさらに別のレベルの保護にあります。ちょうどそのように、今ではポインターをランダム変数に関連付けることができません。
ポインターとオブジェクトのタイプが一致しなければならず、オブジェクト自体がTARGET属性で宣言されなければならないという事実に加えて、配列の次元にも制限があります。 たとえば、1次元配列を使用する場合、それに応じてポインターを宣言する必要があります。
real, target :: b(1000) real, pointer :: pb(:)
配列が2次元の場合、ポインターはpb(:、:)になります。 当然、ポインター内の配列のサイズは指定されていません-ポインターがどの配列に関連付けられるかはわかりません。 論理は明確だと思います。 関連付けの後、通常どおりポインターを操作できます。
b(i) = pa*b(i+1)
b(i)= a * b(i + 1)と書くのと同じです。 pa = 1.2345などの値を割り当てることもできます。
したがって、aの値は1.2345になります。 Fortranポインターの興味深い機能は、配列の一部を操作するために使用できることです。
b => pbと書いた場合、配列bの 1000個の要素をポインターpbで操作できます。
しかし、次のように書くことができます:
pb => b(201:300)
この場合、 100要素のみの配列で作業し、 pb(1)はb(201)です。
ポインタの場合にメモリ割り当て機能を使用する方法はおもしろいです。 allocate(pb(20))を記述することにより、 pbポインターを介してのみ使用できるreal型の配列の追加の20要素を割り当てます。
一般的に、Cに慣れている人は、これはすべて異常に見えるでしょう。 しかし、コードを書き始めると、すぐに慣れてしまい、すべてが便利に見えるようになります。
このブログを書くように私に促した開発者もそう思い、左右のポインターを積極的に使用して、アルゴリズムがツリーを使用するコードを作成しましたが、1つの機能を考慮しませんでした。 このフォーチュンコードは、Fortranに対応しています。
void rotate_left(rbtree t, node n) { node r = n->right; ...
ノード構造には、 ノード*ポインターを含むフィールド(たとえばright)があります。
ローカル変数rは関数内で作成され、値n-> rightなどが割り当てられます。 Fortranでの実装は次のようになりました。
subroutine rotate_left(t, n) type(rbtree_t) :: t type(rbtree_node_t), pointer :: n type(rbtree_node_t), pointer :: r r => n%right ...
そして、ここで、最初に「エラーのエラー」があります。 rポインターをn%rightに関連付けました。 後続のコードでrを変更すると、ローカル変数rのみが変更されるCとは対照的に、 n%rightが変更されます。 その結果、ツリー全体が不可解なものに変わりました。 出口は別のローカルポインターです。
subroutine rotate_left(t, n_arg) type(rbtree_t) :: t type(rbtree_node_t), pointer :: n_arg type(rbtree_node_t), pointer :: r type(rbtree_node_t), pointer :: n n => n_arg r => n%right ...
この場合、ポインターnの関連付けをさらに変更しても、これは「外部」 n_argに影響を与えません。
ひも
そして最後に、混合アプリケーション(CおよびFortran)で膨大な量のメモリを損なう1つの小さな機能。 Cで文字列を操作するときの違いは何だと思いますか:
char string[80]="test";
Fortran
character(len=80) :: string string = "test"
デバッガは簡単に役立ちます。 この場合、Fortranでは、残りの未使用バイトはスペースで詰まります。 同時に、Cに典型的な行終了文字/ Cはありません。したがって、皮ひもをFortranからCに、またはその逆に転送するときは、非常に注意する必要があります。 繰り返しますが、CとFortranを安全に使用するには、この違いと他の多くの問題を解決する特別なモジュールISO_C_BINDINGを使用する必要があります。
これで私の話は終わりです。 これで、CとFortranの最も重要な違いを正確に知ったので、後者についてコードを書かなければならない場合、Cよりも悪くはないと思いますよね? まあ、この投稿は役立ちます。