最後の部分では、不正防止サービスの機能要件と非機能要件に注目しました。 記事のこの部分では、サービスのソフトウェアアーキテクチャ、そのモジュール構造、およびそのようなサービスの実装の主要な詳細について検討します 。
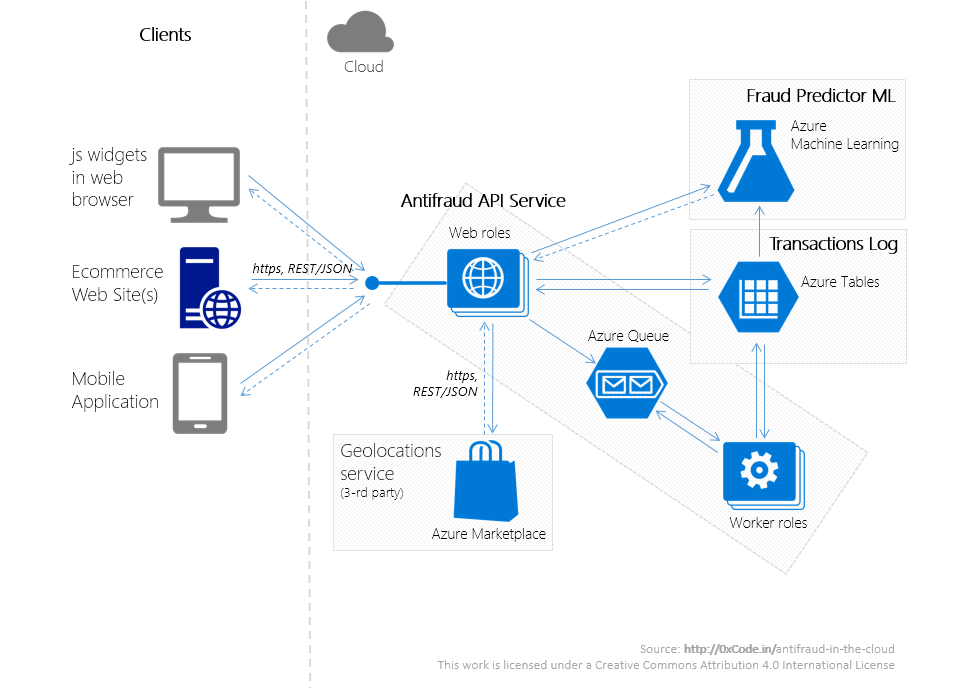
インフラ
このサービスは、Microsoft Azureで実行されるいくつかのアプリケーションです。 オンプレミスプレースメントの代わりにクラウドプラットフォームを使用するプレースメントは、「非機能要件-> 品質属性 」のセクションの2番目の部分にリストされているすべての要件を満たすサービスを開発するためのわずかな時間投資を可能にするだけでなく、ハードウェアおよびソフトウェアの初期財務コストも大幅に削減しますプロビジョニング。
不正防止サービスは、次のシステムで構成されています。
- 不正防止APIサービス-Fraud Predictor MLサービスと対話するためのAPIを提供するRESTサービス。
- Fraud Predictor MLは、機械学習アルゴリズムに基づく不正検出サービスです。
- トランザクションログ -トランザクション情報のNoSQLストレージ。
さらに、このサービスには多数のClientがあります。これらは、商人のWebアプリケーション、またはAntifraud API Service RESTサービスを呼び出すjsウィジェットです。
これらのシステムの相互作用の概略図を上に示します。
使用された建築パターン
インフラストラクチャは、サブジェクトエリアおよび立法行為とともに、潜在的にアーキテクチャレベルで考慮しなければならない多数の制限を伴います。 また、この記事の前の部分でドメインと法的制限について既に説明した場合は、以下のMicrosoft Azureクラウドプラットフォームの選択に関連する利点と制限について説明します。
不正防止システムで使用されるAzureサービスは、Web /ワーカーロール用のクラウドサービス、Azureテーブル、Azureキュー、Azure MLなどです。 -インフラストラクチャの初期財務コストがほぼゼロであることに加えて、次の利点がすぐに利用できます。
- 高可用性 :99.95%以上のSLA。
- ストレージの信頼性 :高冗長性ストレージシステム。
- ストレージセキュリティ :ISO 27001/27002およびその他の証明書(PCI DSS 3.0を含む)。
- 耐障害性 :すべての作業ノードを複数のインスタンスで実行することができます(推奨)。
- スケーラビリティ :負荷に応じた作業ノードの数の自動スケーリング、PartitionKeyに基づくNoSQLストレージテーブルのパーティション分割。
ボーナスとして、私は考えます:
- 便利なアプリケーション監視。
- Visual Studioとの深い統合。
しかし、次のように、クラウド下の不正防止サービスアーキテクチャの「シャープ化」のおかげで、これらすべての利点を活用できることが判明しました。
- web / workerノードはステートレスです。
- 構造化または半構造化データを保存するための水平分割 (シャーディングパターン[1])。
- ネットワークの相互作用は非同期的にのみ発生し、 再試行ポリシーを使用した場合にのみ発生します(再試行パターン[1])。
- 負荷分散と保証されたタスク処理のために、 メッセージキューが使用されます (キューベースの負荷平準化パターン[1])。
また、不正防止サービスはほぼリアルタイムのシステムであるため、不正防止サービスを実装する場合は次のようになります。
- データで並列アルゴリズムを使用します (最も単純で、最も効果的なMapReduceの 1つ)。
- トランザクションログに単一のレコードを保存するような場所では、 Push'n'Forgetアプローチを使用します(機械学習アルゴリズムの精度、10Kのうち1つの欠損レコードが成功しても、強い影響はありません)。
- タイムスタンプフィールドをトランザクション情報に追加することにより、トランザクションログ(共有リソース)のブロックを回避します。
- 長いリクエストを 「殺す」(または少なくとも彼らと何かをする)。
また、すべてのクラウドサービスには制限があることに留意する必要があります。
- 技術的な性質として:最も頻繁なのは、1秒あたりの最大リクエスト数、最大メッセージサイズです。
- 本質的に技術的:最も深刻なのは、PaaSサービスとやり取りするためにサポートされているプロトコルです。
サービスコンポーネント間の相互作用
マーチャントの場合、サービスはhttpsプロトコル(不正防止APIサービス)を介して対話できるRESTサービスです。 Antifraud APIサービスは、いくつかのステートレスWebロールで構成されるクラスターで動作します (AzureのWebロールは、Webアプリケーションとして機能するアプリケーション層です)。
次のシーケンス図は、マーチャントと不正防止サービスのすべてのサブシステムとの可能な相互作用を示しています。

- ステップ1.支払い情報を含むリクエストを送信します。
- ステップ2.モデルの変換(MVCの観点から)。
- ステップ3.支払い予測サービスのリクエストを送信する。
- ステップ4.結果を返す-支払いが成功するかどうか。
- ステップ5.データを保存します。
- ステップ6.結果をクライアントに返す。
- ステップ7、8。トレーニングサンプルの再計算と更新、モデルの再トレーニング。
- ステップ9-12(オプション)。 クライアントは、支払い結果に関する情報を含むリクエストの送信を開始します(予測結果がリクエストで送信された実際の支払い結果と異なる場合)。
各ステップをより詳細に検討してください。
マーチャントからのリクエストは、コントローラーに(MVCの観点から)到着します(ステップ1)。 その後、結果のモデル(MVCの観点から)が通過します。
- コントローラーモデルからドメインオブジェクトへの変換。
- 外部のジオロケーションサービス(Azure Marketplace)へのリクエスト。支払者インデックスにより国を、カードから資金を引き出すリクエストが来たホストのIPにより国を検索します。
- グローバルフィルタによる検証手順。
- 支払いデータの検証の段階;
- 受信したトランザクションの予備分析-5秒、1分、24時間の時間枠のヒューリスティックを考慮します。
- 購入者の個人データと支払いデータの隠蔽-カード所有者の名前、販売者のウェブサイトのアカウント所有者の名前、支払人の住所、電話番号、メールがハッシュされます。
- 不要なデータを削除します。たとえば、手順4の後のカードの有効期限に関するデータは必要ありません。
ヒューリスティック、グローバルフィルター、および支払いデータの有効性の兆候については、この記事の前の部分で詳しく説明しました。
ステップ2では、ドメインオブジェクトがDTOオブジェクトに変換されます。
- Fraud Predictor MLサービスに転送されます(ステップ3)。
- Fraud Predictor MLから応答を受信した後(ステップ4)、トランザクションとその結果に関する情報がトランザクションログに保存されます(ステップ5)(それについては少し後で)。
- 支払いの予測結果(不正かどうか)に関する回答をクライアントに返します。
予測アルゴリズムの品質を向上させるために、クライアントはAPIを使用してトランザクションの結果を改善できます。 したがって、支払いの実際の結果が不正防止サービスによって返された値と異なる場合、商人はトランザクションの結果を明確にするためにリクエストを送信することでこれを報告できます(ステップ9)。 そのような要求:
- 形式は<transaction_id、transaction_result、last_update_time>です。
- Merchant API Serviceによって処理され、検証後にAzure Queue (フォールトトレラントキューサービス)に配置されます。
リクエストは、 ステートレスワーカーロールであるロボットの1つによってキューから取得されます(ワーカーロールはAzureにあり、これはハンドラーとして機能するアプリケーション層です)。
トランザクションストア
トランザクションに関する情報とそれらに関する追加情報(主に統計情報)は、トランザクションログ(Azureテーブル(フェイルセーフなNoSQLストレージ(キー値)であるサービス)に基づく長期ストレージ)に保存されます。
トランザクションログは2つのテーブルです。
- トランザクションTransactionsInfoに関する情報を含むテーブル:トランザクションID(行キー)、マーチャントID、カード所有者の名前のハッシュ(利用可能な場合)、支払い金額、通貨など。
- TransactionsStatisticsの計算された統計メトリックを含むテーブル:このカードから支払った回数(数時間)、IPアドレスの数、支払間の時間間隔、顧客が商人に登録した期間、成功した支払回数など。
ステップ7、8では、モデルが再トレーニングされます。 トレーニングサンプルはトランザクションログからのデータです。なぜなら、 ログリポジトリには、支払いとその結果に関する最新情報が含まれています。 誤った予測の特定のしきい値を克服するために、トランザクションログに新しいエントリの固定値が出現することにより、スケジュールに従って再トレーニングを行うことができます。
次の最後の部分で、不正な支払いを検出するためのモデルのトレーニングの問題に触れます。
第三部のまとめ
このパートでは、不正防止サービスのアーキテクチャについて説明し、その中の機能部分を区別します-不正防止APIサービス、不正予測ML、トランザクションログ、責任範囲、および相互作用の方法を定義しました。
アーキテクチャへの適切なアプローチにより、Microsoft Azureクラウドに不正防止サービスを展開すると、インフラストラクチャの初期財務コストが大幅に削減され、システムのスケーラビリティ、信頼性の高いデータストレージ、およびサービスの高可用性に関連する問題に費やす時間が削減されます。
次の最後のパートでは、開発および所有コストが同等のものよりもはるかに安い不正防止サービスを作成し続けます.Azure Machine Learningサービスに基づいており、不正防止サービスの分析コアであるFraud Predictor MLサービスを開発します。
有用なソース
[1] クラウドデザインパターン:クラウドアプリケーションの規範的なアーキテクチャガイダンス 、MSDN。