KDPV(この写真はおそらくその関連性を失うことはありません):

免責事項:以下のプロセスの説明はすべて、特定の企業で得られた著者の個人的な経験に基づいており、読者の客観的な現実とは無関係かもしれません。 開発の各段階に関する情報は要約形式で提示されており、1つの記事の枠組み内でプロセスの主要なポイントのみを明らかにすることを目的としています。
ステージ
最初は言葉でした...
私にとっては、新しい機能(別名「機能」)の出現の3つの段階を区別します。
1.一般的な用語で説明されているアイデアがあります 。
例:「プログラムに電子メール通知サポートを追加します。」
2.アイデアはユーザーの観点から開発されます。つまり、ユースケースが作成されます。
例:「特定の操作が完了すると、プログラムは事前定義されたSMTPサーバーを介してユーザーが指定したアドレスに電子メールを送信します。」
3.アイデアは開発者/テスターに説明され、実装が直接開始されます。
したがって、第3段階に到達するために、アナリストは主題領域を徹底的に研究する必要があります。まず、「それ」がどのように機能するかを、開発の観点から(程度は低いが)ユーザーの観点から理解する必要があります。 第一段階での要件の不十分な研究は、実装された機能がアナリストによって期待されるようにまったく機能しないという事実につながる可能性がありますが、開発者がそれを理解しただけです(残念ながら、現代世界では非常に頻繁に起こります)。
次のような詳細が適切に解決されない場合、適切なエラボレーションのないそのような一見単純な「機能」でも破損する可能性があります。
- 複数の宛先メールアドレスをサポートする必要がありますか?
- SSL / TLS暗号化をサポートする必要がありますか?
- 電子メール通知を送信する特定の操作は何ですか?
- スケジュールされた通知を送信する必要がありますか?
- 通知にはどのようなテキストを含める必要がありますか?
- 件名を設定するときにテンプレートが必要ですか?
- 操作ログを通知で送信する必要がありますか? もしそうなら、テキストとして、または添付されたテキストファイルとして?
- 等 など
それにもかかわらず、要件の初期開発にどれだけ時間がかかったとしても、特に新しい機能が非常に膨大である場合は、未説明の使用シナリオがほとんど常に現れます。 そのため、新機能をまったく異なる角度から見て、単純なユーザーには決して起こらないスクリプトを考案できる開発者やテスターと「機能」について話し合う必要があります。 このプロセスについては、記事の次のセクションで詳しく説明します。
以下は、実際の生活から新しい「機能」を設計する際に自分の製品を知ることの重要性の例です。 多くの手紙と特定の用語があることを警告します。 誰も恐れていません-彼らはネタバレを調べることができます:
例
当社の製品Acronis Backupには、バックアップ計画などがあります(一般の人々では「バックアップ計画」)。 次に、バックアップ計画は、計画のさまざまな段階を担当する複数のアクティビティ(「タスク」と呼ばれる)で構成されます。 そのため、直接バックアップはバックアップタイプのタスク(計画に含まれる各マシンごとに1つのタスク)、および作成されたバックアップを追加のストレージにコピーする(「ステージング」とも呼ばれる)、または「タイプタスク」の古いコピーのストレージをクリアするなどの追加のアクティビティで実行されますレプリケーションとクリーンアップのそれぞれ。
一度に、オプション「レプリケーション/クリーンアップ非アクティブ時間」が追加されました。これは、アイデアに従って、作成されたバックアップのバックアップを実行できる期間、つまりタイプ「レプリケーション」/「クリーンアップ」のタスクのアクティビティ期間を制限する必要があります(たとえば、この操作を許可します)営業時間中にネットワークをロードしないように、1〜3泊のみ)。
このオプションの動作は、「レプリケーション/クリーンアップ非アクティブ時間」オプションの設定で指定された時間より前にバックアップタスクを完了する時間がない場合のユーザーの期待とは異なることが判明しました。 バックアップタスクの終了を待って「レプリケーション」タスクの開始を防ぐ代わりに、プログラムはバックアップタスク自体の速度を低下させ、「非アクティブ」期間の終了を待ちます。
なぜこれが起こったのですか? 問題のあるオプションは、「レプリケーション」タイプの個別のアクティビティではなく、全体としてバックアップ計画全体に「ボルトで固定」されることが判明したため、この動作が発生しました。
この問題は、このオプションが「レプリケーション」アクティビティにのみ適用され、他のアクティビティに影響を与えないという条件が最初に設定されていた場合(バックアップタスクの構造に関する知識を考慮して)回避できた可能性があります。 したがって、そのような条件を確立するために、アナリストはバックアップ計画の構造を知る必要があります。つまり、ユーザーが期待する動作だけでなく、機能の実装を台無しにする場所を想像する必要もあります。
一度に、オプション「レプリケーション/クリーンアップ非アクティブ時間」が追加されました。これは、アイデアに従って、作成されたバックアップのバックアップを実行できる期間、つまりタイプ「レプリケーション」/「クリーンアップ」のタスクのアクティビティ期間を制限する必要があります(たとえば、この操作を許可します)営業時間中にネットワークをロードしないように、1〜3泊のみ)。
このオプションの動作は、「レプリケーション/クリーンアップ非アクティブ時間」オプションの設定で指定された時間より前にバックアップタスクを完了する時間がない場合のユーザーの期待とは異なることが判明しました。 バックアップタスクの終了を待って「レプリケーション」タスクの開始を防ぐ代わりに、プログラムはバックアップタスク自体の速度を低下させ、「非アクティブ」期間の終了を待ちます。
なぜこれが起こったのですか? 問題のあるオプションは、「レプリケーション」タイプの個別のアクティビティではなく、全体としてバックアップ計画全体に「ボルトで固定」されることが判明したため、この動作が発生しました。
この問題は、このオプションが「レプリケーション」アクティビティにのみ適用され、他のアクティビティに影響を与えないという条件が最初に設定されていた場合(バックアップタスクの構造に関する知識を考慮して)回避できた可能性があります。 したがって、そのような条件を確立するために、アナリストはバックアップ計画の構造を知る必要があります。つまり、ユーザーが期待する動作だけでなく、機能の実装を台無しにする場所を想像する必要もあります。
議論
アナリストが新しい「機能」の最初の説明(ステージ2)を編集した後、このテキストは少なくとも2人のユーザーによって読み取られ、分析されます。開発者(実装者)とテスター(テストスクリプトの作成者)です。
私たちの場合の議論は「ソファで」行われます。アナリスト、テスター、および/または開発者は
ヒント
一部の特にunningなテスターは、これらの会話をボイスレコーダーに記録して、次のような状況で証拠ベースを作成します。
-なぜこれがテストされないのですか?
-そして、あなたはこのシナリオは有効ではなく、除外できると言っていました!
-いつ言ったの?!
-音声録音。 すべての動きが記録されています。
-なぜこれがテストされないのですか?
-そして、あなたはこのシナリオは有効ではなく、除外できると言っていました!
-いつ言ったの?!
-音声録音。 すべての動きが記録されています。
設計とメンテナンス
自宅では、 JIRAを使用してすべてのアクティビティ(バグ、QAタスク、テクニカルサポートからのチケットなど)を追跡し、統計を保持し、メトリックを作成します。 Confluenceは、プロセス、内部ドキュメント、機能要件などの説明に使用されます。
JIRA <-> Confluenceは、これら2つのシステムの要素間のリンクを構築する際の柔軟性が高いために選択されました。 たとえば、Confluenceでは、JIRAの定義済みフィルターに従ってテーブルを作成し、美しいグラフを作成し、1ページで複数のJIRAプロジェクトのステータスを追跡できます。 さらに、組み込みのConfluenceテキストエディターは、JIRAの対応するテキストエディターよりもはるかに柔軟性が高いため、機能の記述に適しています。
Confluenceの新機能の説明には厳密な規則はありませんが、遵守することが推奨されているテンプレートがあります。 テンプレートの例を次に示します。
見出し、JIRAのチケットへのリンク、および主な目標:
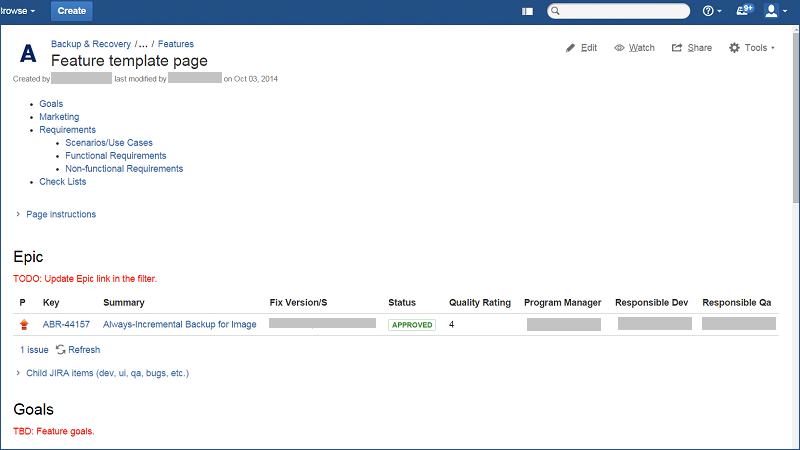
マーケティングに関する情報と要件の作成手順:

ユーザーインターフェイス(「モックアップ」)、使用シナリオ、機能要件および非機能要件を表示するチケットへのリンク:

設計は、次の手順で構成されます。
1.必要な機能の簡単な説明とともに、「Epic」タイプのチケットがJIRAで開始されます。
2.この「機能」を実装するバージョン/アップデートを決定します。
3. Confluenceのページはテンプレート(上記の例)に従って作成され、アナリストがあらゆる形式のスクリプトのスケジュールを自由形式で記入します。
4. Confluence のページがテスター(QA)および開発者に表示され、テストケースを調査および作成します。
5. JIRAは、元の「Epic」に関連付けられた「dev task」タイプのチケットを作成し、評価します。
さらに、開発は直接行われ、その最後に、以前に作成されたスクリプトに従って機能を「実行」するために機能がテスターに転送されます。
同時に、多くの新機能があり、まず会社の現在の目標に応じて最高の優先度で「機能」を実装する必要があることを考慮して、ステップ1と2の間にかなりの時間が経過する場合があります。
開発
私たちの場合、開発は2〜4週間の多数の反復(スプリント)に分割され、その後デモンストレーションが行われます。 デモンストレーションの主な目的は、開発中の機能が元のアイデアに対応し、追加のリスクがないことを確認することです。 つまり、 アジャイル開発の原則を(少なくとも試して)順守します。
最初は、開発者はそのようなデモンストレーションに時間の無駄を考慮して懐疑的でしたが、実践が示すように、デモンストレーション中に追加のアイデアが生まれ、見逃されたシナリオが明らかにされ、プロセスのすべての参加者のビジョンを同期できます(アナリスト、テスター、開発者、上司) 。
開発プロセス中、特に機能が膨大な場合、初期要件の変更が必要になる場合があります(現実との互換性を確保するため)。 すべての変更はConfluence / JIRAで文書化され、それに応じてタスクスコアが調整されます。
ヒント
私たちが順守している一般的なルールは、「 JIRAにエントリがない=作業が完了していない 」です。 つまり、開発活動はすべてJIRAに反映される必要があります。 これはプロセスの過度の形式化のように思えるかもしれませんが、この規則への移行は、ドキュメンテーションユニバースのエントロピーと、記述されたコードに伴うカオスの削減に役立ちました。
発売日
「機能」の受け入れは、いくつかの段階で実行されます。
1.開発者は「 完了!」と言います。 アセンブリ番号XXを見ることができます »
2.テスターは、コンパイルされたテストスクリプトに従って新しい機能を実行し、バグを引き起こします。
3.アナリストは、ユーザーシナリオの観点から、実装された「機能」を確認します(実際、これは正式な手順です。デモ中に同じことが既に行われているためです)。
4. 「機能」は、内部テストのために他の部門に与えられます。
まず(QA後)「生産システム」ですべての製品をテストします。 私たちの勇敢な管理者
これまでのすべての手順を経て初めて、製品はエンドユーザーが見る価値があると見なされます。
製品自体の公開リリースは、多くの微妙な点を伴う別個のプロセスです。これは、別個の記事に値する大きなトピックです。
おわりに
上記の要約:
A.あなたのアイデアを徹底的に考え、それらを正しく作成します(少なくとも1つの合意された基準を順守します)
B.開発全体を通してプログラマーとテスターと通信する
C.製品開発期限の終了を待たずに中期デモを開催する
G.
製品の開発時に同様の方法論を使用する場合は、コメントでプロセスを改善、高速化、最適化する方法を教えてください。