
私はすべてのクロスワードがかなり前にプログラムで生成されたと確信しており、これが問題になる可能性があることに多少驚きました。 「カナディアン」クロスワードについて話していることに注意してください。クロスワードでは、各単語が各文字の別の単語と交差するか、非常に複雑になります。 私の仕事である分析では、それほど複雑なタスクは多くないため、これを実行できるアルゴリズムを開発しようとするのは興味深いことでした。 クロスワードを生成するためのプログラムでサポートされているリフレクションの結果は、この記事に記載されています。
クロスワードパズルを埋めるためには、常にブルートフォースが使用されます。 最初の単語を配置し、次にすべての単語を配置して、交差点の文字が前に設定した単語の文字と一致することを確認します。 そして、すべての言葉が伝えられるまで。 それは思われる-より簡単なものはありません。 ただし、平均長のクロスワードのワードマッチングの反復回数を50ワードだけカウントすると、この意見が変わる可能性があります。 したがって、最初の単語を除く任意の単語をインストールするには、データベースに対応する長さの単語が1,000個あり、交差点で満たされた単語が1つだけ早い場合、平均1,000 / 33 = 30回の反復が必要になります(平均で30単語を調べる必要があります)交差点の位置に目的の文字が以前に入力されている単語に出会う前に)。 以前に入力された交差ワードが複数ある場合、この数は急激に増加します。 簡単な計算では、50語を埋めるには30 ^(50-1)回の反復が必要であることがわかります。 これらは数十億回の反復です。 最新のコンピューターでも、数日から数か月の作業が必要になります。 そして、ここでは、検索自体はそもそもではなく、クロスワードパズルを生成するのにかかる時間を何桁も短縮するアルゴリズムです。
トラックへ...
すぐに、「陸上」で、クロスワードパズルの生成が2つの段階で構成されることを受け入れる必要があります。
- 分析-生成計画の作成。その主な結果は、生成段階で役立つクロスワードワードやその他のデータを生成する特定のシーケンスです。
- 生成-分析の段階で得られたデータを考慮に入れて、可能なすべてのオプションを徹底的に検索する方法により、クロスワードパズルグリッドに単語を順番に入力します。
これに基づいて、以下に示すソリューションをマークし、どの段階に適用できるかを説明します。
すべての実験は、下図に示すクロスワードパズルで実行されます。

これは最も難しいクロスワードパズルではありませんが、それに関連するソリューションは他のすべてのクロスワードに関連します。 少数の単語は、比較的迅速な結果を保証します。
そして最後の1つ。 この記事では、プログラムの単語ベースの生成に関連するすべてを省略します。 この部分は、費やした合計時間の少なくとも50%の「価値」がありました。 現在、データベースには15万8千以上の単語があり、そのうち12万5千以上が一意です。 ベースはプログラムによって最大限にクリーニングされていますが、手動モードでは引き続き注意が必要です。 何らかの方法でデータベースを閉じたり暗号化したりすることはありませんでした-データベースはテキスト形式で、最も単純なキー値形式で開かれています。 単語を削除または追加したり、説明を修正したり、(たとえば、別の言語で)独自の単語に完全に置き換えたりできます。
道の始まり
最初に決定することは、単語を埋める順序です。 これには非常にシンプルで明白な解決策があります。
決定番号1:単語は、主にその長さに依存するシーケンスで生成されます。 単語が長いほど、交差点が多くなり、設定する単語を見つけるのが難しくなります。 それどころか、最短の単語である2文字または3文字の長さの交点は最小限に抑えられ、生成の最終段階で選択するのに最も便利です。 このソリューションは、分析段階で使用されます。
解決策2:同じ長さの単語のうち、インストールが最も困難な単語が最初にインストールされます。 インストールの複雑さは、「この単語の意味を理解するのがどれだけ難しいか」と「単語が理解できなかった場合にエラーの価格がいくらになるか」を示す計算されたパラメータです。 インストールの複雑さは完全に異なりますが、同じ長さの単語(5文字など)が1つの単語または5つの単語と一度に交差できることは明らかです。 このソリューションは、分析段階で使用されます。
決定No. 3:以前の決定に基づいて、単語は、2つの隣接する単語が互いに交差することを保証しないような順序で配置されます。 つまり、インストールする単語が見つからなかった場合は、前の単語ではなく、この単語と交差する以前にインストールされた単語の1つを変更し、基本的に選択の条件を設定する必要があります。 以前に確立されたすべての交差ワードのうち、最後のワードセットを置き換えて、生成ワードの最小数にロールバックすることは論理的です。 このソリューションは、生成段階で使用されます。
フラグメント
決定No. 1とNo. 2に基づいて決定された順序で単語のインストールをトレースすると、いくつかの単語のインストールがローカルに独立したフラグメントを形成することに気付くでしょう。 下の写真を見てください。
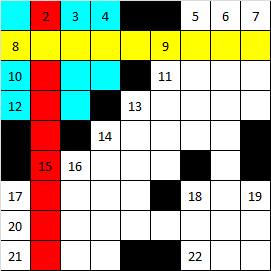
カラー図面は、よく知られている「すべてのハンターがキジが座っている場所を知りたい」に対応する順序で、クロスワードパズルグリッドに最初の単語をインストールする順序を示しています。 設定する最初の単語は赤です。 その後、黄色でマークされた単語などです。 クロスワードパズルに2単語だけをインストールすると、ローカルフラグメントが形成され、青色でマークされます。
続行する前に、まず用語を決定します。
- フラグメントは、クロスワードパズルの1単語から単語の合計数の50%までの単語のグループであり、その生成は、まだ設定されていない残りの単語すべてに依存しません。
- 開始語は、インストール後にフラグメントが形成された語です(上の図では、黄色で強調表示されている語です)。
- 最初の単語はフラグメントワードであり、フラグメント内のすべてのワードのインストール順序が最も低くなります。
- フラグメントの深さ-フラグメントを構成する単語の数。
フラグメントが出現すると、ジレンマが発生します。定義済みのシーケンスでクロスワードを生成し続けるか、最初にフラグメント内のすべての単語を生成して、開始ワードが正しく設定されていることを確認します。 これは、全体的なパフォーマンスに重大な影響を与える可能性があり、明確な論理的解決策がないアルゴリズム内の場所の1つです。
解決策4:設定されている各単語について、フラグメントが検索されます。 1つのフラグメントに属するすべての単語には、開始単語から、またはフラグメントの最初の単語から順に、インストールの順番が付けられます。 このソリューションは、分析段階で使用されます。
現時点では、フラグメントのワードを生成するシーケンスを変更するアルゴリズムの一部は次のとおりです。
- 断片を見つけます。
- フラグメントを埋める複雑さを判断します。
- 次の規則に従って、フラグメントのすべての単語を配置する必要がある単語を決定します。
- フラグメントのメンバーである単語は、次々に設定されます。
実際のところ、これですべてです。通常の列挙によってクロスワードパズルを生成するアルゴリズムが準備できました。 最小限の詳細で、次のようになります。
- 単語生成の順序が決定されます。
- 単語の選択とインストールは、以前にインストールされた単語を考慮して実行されます。
- インストール用の単語がない場合、それと交差する最後の単語に対してロールバックが実行され、その検索は、以前の値がまったく見つからなかったかのように続行されます。
チェック済み-難易度が中程度のグリッドで本当に機能します。 ただし、クロスワードパズルグリッドがより複雑になり、単語数が増えると、生成試行の成功回数は0になる傾向があります。実際、この瞬間から最も興味深いことが始まります。
パターン
頭に浮かぶ最初の質問は、どういうわけかロールバックの数を減らすことは可能ですか? 結局、数ワードをロールバックするたびに、数万から数十万回の反復が発生する可能性があります。 論理的な手順は、単語のインストールエラーの数を減らすルールを追加することです。たとえば、単語が始まるセルにソフトまたはハードサインを入れないなどです。 深く掘り下げていない場合、ロシア語のこれらのルールのほとんどを説明するのは非常に簡単ですが、問題があります-たとえば英語では絶対に役に立たないでしょう。 言語に依存しない汎用アルゴリズムを作りたかった。
この問題について考察した結果、次のようになりました。「まだ特定されていない各単語について、現在の単語がインストールされるようになると、インストールオプションの可用性が保証されます。」
そこで、Transact-SQLのLIKEコマンドに似たテンプレートを使用するというアイデアが生まれました。 パターンは、単語の比較に使用される文字列です。 テンプレート自体には、文字とワイルドカードが含まれています。 パターンと比較する場合、文字が行に示されている文字と正確に一致する必要があります。 パターン文字は、文字列の任意の要素と一致できます。
決定番号5:各開始単語について、それと交差するすべての単語のパターンが計算されます。 開始単語には、交差文字の位置に対応するテンプレートのリストに厳密に一致する文字が必要です。 このソリューションは、生成段階で使用されます。
3文字の単語のパターンの例を以下に示します。
- テンプレート:「___」
- レターNo.1:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
- レターNo. 2:Y A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
- レターNo. 3:Y A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
- テンプレート:「TO_」
- 文字番号1:D
- 文字番号2:O
- 手紙番号3:G K M N
後者を例として使用すると、パターンを次のように読み取る必要があります。最初の2文字が「DO」に等しい3文字の単語には、データベースに最後の文字が「G K M N」のいずれかに等しい単語があります。
加速器
フラグメントに戻りましょう。 下の写真を見てください。
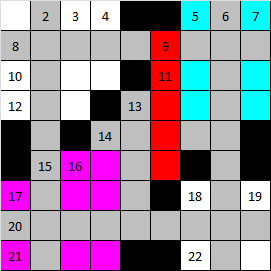
その中で、以前に確立された単語の灰色のセルがマークされます。 赤でマークされた単語を設定すると、青と紫の色でマークされた2つのフラグメントが同時に形成されます。
紫色のフラグメントを見ると、単一の交差点を持つ開始ワードに関連付けられていることがわかります。 そしてこれは素晴らしい! これにより、別のソリューションを使用する機会が与えられます。
もう少し用語:
- アクセラレータ-子フラグメントがあり、単一の交差点を持つ開始語。 彼は、断片の生成を1桁以上加速するために、このプロパティの名前を取得しました。
解決策6:開始ワードがアクセラレーターであるフラグメントが失敗した場合、アルゴリズムはフラグメントのワードの1つとの交差点で開始ワードにインストールされた文字のリストを保管し、これらの文字がその交差点にあるワードの再設定をブロックします。 このソリューションは、生成段階で使用されます。
アクセラレータを使用するためのアルゴリズムを以下に示します。
まず、アクセラレータなしでどのように機能するか:
- フラグメントのすべての単語の検索とインストールが実行されます。
- フラグメントの充填が成功した場合、次に進みます。そうでない場合、開始ワードが変更され、フラグメントのワードを充填するプロセスが繰り返されます。
フラグメントの深さは十分に大きくすることができ、フラグメントを満たすための反復の合計数は数百万になる可能性があります。 可能なすべてのオプションを並べ替えるには、フラグメントを1回満たすための反復回数が必要です。データベース内の単語数(開始単語(数万)のような)を掛けます。
アクセラレーターとの連携:
- フラグメントの単語を検索して設定します。
- フラグメントの充填が成功した場合は、先に進みます。そうでない場合は、アクセラレータとフラグメントの単語の交点にある文字を覚えておいてください。
- アクセラレータにインストールされている単語が変更され、新しい単語には、上記の交差点で以前に記憶されていた文字が含まれていてはなりません。
フラグメントの深さは同じです。 ただし、考えられるすべてのオプションを並べ替えるには、フラグメントを埋めるための反復回数に、開始ワードのオプション数ではなく、33(アルファベットの文字数)だけを掛ける必要があります。
インストールの複雑さの動的なバランス
実際、以前の決定は、パレートの原則によれば、結果の80%をもたらす努力の20%を使い果たしました。 それから、私たちはますます複雑なアプローチを使用しなければなりません。
かつて、クロスワードパズルを生成するときに、プログラムは次のメッセージを発行しました:「徹底的な検索の時間:11,471日...」。 このメッセージは、最初の単語のすべてのバリエーションが列挙されており、その新しい意味を見つける必要がある場合にのみ表示されます。 プログラムはすでに時間を費やし、残りのオプションの数を単純に乗算します。 これは私を楽しませ、この時間を結果に変換できるかどうか疑問に思いましたか? アイデアは、成功の可能性が最小限であるいくつかの検索オプションを意図的にトリミングすることです。
この決定の主な理論は、考えられるすべての境界を超えるほど長い時間選択を行うよりも、プログラムが最短時間で(つまり、選択が失敗した最適なオプションの中で)否定的な結果をもたらす方が良いということです。
決定No. 7:インストールが非常に困難な単語と交差する単語をインストールする場合、単語の交差点での使用頻度が最小である前述の交差文字の位置に配置することは禁止されています。 このソリューションは、生成段階で使用されます。
単純な理由で、このソリューションが特定の数のロシア語のアルファベット(場合によっては20文字まで)を破棄し、より頻繁に使用される文字(ここでは21文字のイタリア語のアルファベットはチョコレート)から単語から複雑なセクションを生成する機会を増やします。 その結果、ターンになると設定するのが難しい単語を選択するためのオプションが増えます。つまり、クロスワードパズル全体が成功する可能性が高くなります。
欠点もあります-検索オプションの一部は回復不能なほど失われます。 おそらく、それらの中には、グリッドを埋める唯一の可能なオプションがあります。 あなただけが30年でそれを手に入れることができます-あなたは少し待つ必要があります。
もう1つのマイナス点は、交差点が10を超える長い単語が最もブロックされることです。 これは、オプションがなくなるまで最初の単語をブロックすることでプログラムが生成を開始できないという事実につながります。 このマイナスは、ブロックの度合いの低下、したがってこのソリューションの有効性によって、部分的にしかコストがかかりません。
テスト中
生成の複雑さに従ってグリッドを編成するために、「生成の複雑さ」属性が導入されます。これは、単語の数、その長さ、および交差の数に基づいて計算されます。 実際、最大600ユニットの複雑さで、多少安定した結果を得ることができます。 上記のすべては運のためです。
以下は、生成の複雑さの昇順で配置されたいくつかのグリッドの10回の試行の平均生成時間です。
グリッド1
少数の単語を含む、実験用のシンプルなテストグリッド。
- 世代の難易度:248
- ワード数:28
- 成功した生成の平均時間、秒:5(1から32)
小計:このような複雑なグリッドは、迅速かつ安定して生成されます。
グリッドNo. 2

このグリッドはより複雑です。 これは小さな「カナダの」クロスワードで、すべての単語にすべての文字の交差があります。
- 世代の難易度:372
- ワード数:34
- 生成に成功した平均時間、秒:62(1から472)
小計:ほとんどの場合、このような複雑なグリッドは非常に迅速に生成されますが、生成が10分以上続くこともあります。
グリッドNo. 3

このかなり複雑なグリッドは、生成に非常に「便利」であることが判明しました。
- 世代の難易度:544
- ワード数:46
- 成功した生成の平均時間、秒:1(1から2)
小計:このグリッドは非常に細かく断片化されており、長い単語のすべての文字で交差点が見つからないため、プログラムはほぼ瞬時に生成します。
ネットNo.4

しかし、このグリッドにはすでに「ターゲット」の複雑さがあります。 これは本格的な「カナダ」クロスワードパズルですが、最も難しいものとはほど遠いものです。
- 世代の難易度:570
- ワード数:78
- 成功した生成の平均時間、秒:250(10から989)
小計:プログラムがやった! 最も極端な場合、生成結果はわずか17分で得られます。 平均生成時間はわずか4分を超えています。
グリッドNo. 5
そして最後に、それをすべて始めた最も複雑なクロスワードパズル。 72語ありますが、それほど多くはありません。 しかし、世代の複雑さは非常に高いことが判明しました。 生成の主な問題は、クロスワードの他のほとんどすべての単語が交差する4つの最も長い単語です。 それらはスケルトンボーンのようなもので、その上で他のすべての単語をストリング化する必要があります。 ロールバックは、生成プロセスによってほぼ最初の段階で破棄されます。 したがって、このグリッドを生成するプロセスは、Sisyphusが石を押し上げているのと比較できます。 そして、ゴールに残っているものがほとんどないときはいつでも、石は道の一番最初まで転がり落ちます。
悲しいかな-このピークは征服されなかった! 最大10時間の制限で、さまざまな設定で複数の世代を開始しましたが、どれも正常に完了しませんでした。 明らかに十分な時間がない。 おそらく、この征服されていないピークが誰かを新しい攻撃に駆り立てるでしょう。
まとめ
そしてまだはい! 最新のコンピューターであっても、クロスワードパズルを作成するのは大変な作業です。 このアルゴリズムを改善する可能性は尽きることはないと確信していますが、アルゴリズムの能力とコンピューターの能力に関係なく、クロスワードパズルグリッドを常にもう少し複雑にして、プログラムが20-30年後に結果を約束するようにすることができます。
あなたが興味を持っていて、最後まで読んでくれたらいいのにと思います。