IT専門家の声明に絶えず直面している「ネットワークの負荷は20%...プロセッサは50%...ディスクのキューはほとんどありません...そのため、ネットワークとサーバーは対処しています... 1Cのコードのみを参照してください。」
実際、次のことが発生しました(1CサーバーとSQLは異なるコンピューターに分離されていました):ネットワークは実際に最大限に使用されていました( これらの「 ネットワークインターフェイスの20%の負荷 」=「20%の有用なデータ」+「80%の公式処理の損失」 )。 したがって、「有用な」データ交換チャネルの幅が狭いため、「Server 1C」を備えたSQLサーバーは常に相互に待機しており、CPUおよびディスクシステムリソースの使用率が低くなりました。
実施: まず、1Cプラットフォームとは何かに焦点を当てたいと思います。
それでは、メインの1Cから始めましょう。ORM (オブジェクトリレーショナルマッピング) 上に構築されたシステムで 、そのプログラマーはリレーショナル表現ではなくオブジェクトを直接操作します。
en.wikipedia.org/wiki/ORM
1C環境のプログラマーはオブジェクトロジックを記述します。プラットフォーム自体は、データベーステーブルに従ってオブジェクトを「フラットビュー」でアセンブル/逆アセンブルし、記述します。
ORMの観点からの主な「+」と「-」:
"+" ORM環境のプログラマーは、コードの量の削減と、専らリレーショナルプログラムコード(例:SQLクエリ)に比べてシンプルであるため、アプリケーション開発の速度に利点があります。 また、リレーショナルDBMSのテーブルのエントリで直接動作するコードを書く必要もありません。 * 1
「-」 ORM「プラットフォーム」の作成者にとっての問題とパフォーマンスの問題:
リレーショナルデータベースを使用してオブジェクト指向データを保存すると、「セマンティックギャップ」が発生し、プログラマはオブジェクト指向形式でデータを処理し、このデータをリレーショナル形式で保存できるソフトウェアを作成する必要があります。 この2つの異なる形式のデータ間での絶え間ない変換の必要性は、パフォーマンスを大幅に低下させるだけでなく、両方の形式のデータが相互に制限を課すため、プログラマにとっても困難になります。
* 1「明確化」。 1C 8.xでは、1Cの「Request」オブジェクトでリレーショナルのようなコード(読み取り専用)を使用できるにもかかわらず、リレーショナルDBMSに変換されたデータストレージテーブルへの直接的な1対1のクエリではなく、全体として、「オブジェクト要求」は、オブジェクトを分解するアセンブリ段階を通過していません。 したがって、多くの場合、コード速度と開発速度の点で最適な数千行の「オブジェクトクエリ」の代わりに、オブジェクトのない非リレーショナルのようなコードを記述します。
第1章: クライアントサーバーモデル1C 8.xを検討する
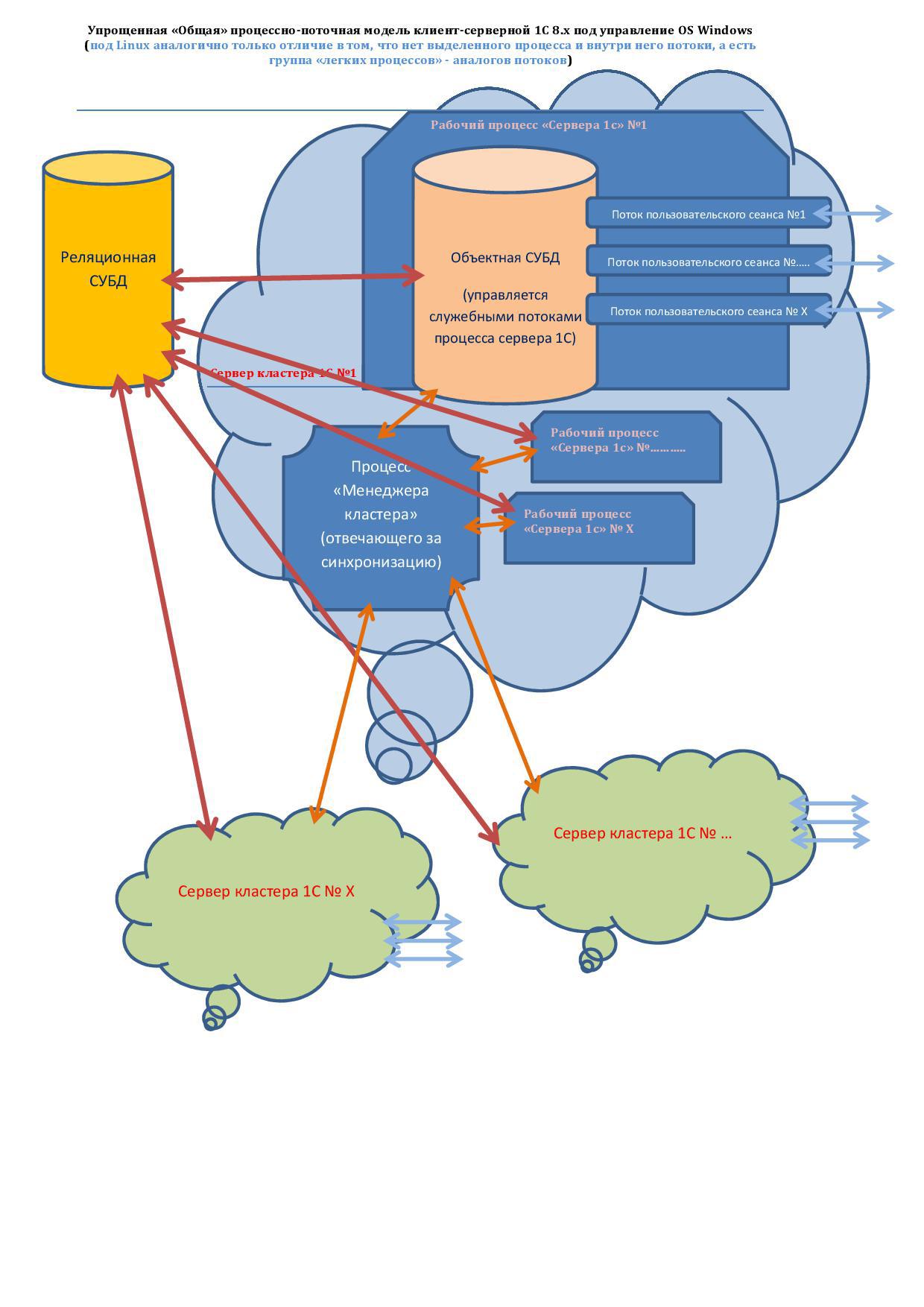
生産性に影響する主なボトルネックに注目します。
1)最初のボトルネックは、データ伝送の通信媒体です 。
図では、矢印はデータ交換フローを示しています。「赤」はリレーショナルDBMS <->オブジェクトDBMS、「オレンジ」はオブジェクトDBMS間の同期です。
なぜなら DBMSと1Cクラスターに別々のサーバーを使用する場合-通信環境はネットワーク接続です-インターフェースの物理的な実装の待ち時間とこのネットワーク内のノードの待ち時間の両方のために、多数の小さな部分でのデータ送信に大きな遅延があります。
イーサネットギガビットネットワーク標準の例を見てみましょう ( データ転送速度依存性のグラフ...以下 )
MS SQLを使用したサーバー1Cの操作例( デフォルトでは、通信パケットのサイズは4 kb) :
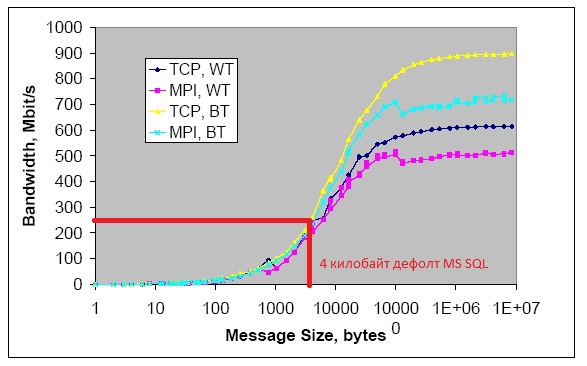
グラフは、DATAパケット= 4 kbを使用する場合、対象となるネットワークのスループットは250メガビット/秒のみであることを示しています。 (出版物の解説に正しく記載されているとおり: これらは TCPレイヤーなどのプロトコルパケットではなく 、交換に関与するアプリケーションが生成するDATAパケットです)
...
練習から: 2つの別々のサーバーでのそのような多様性
MS SQL(サーバー1)<-イーサネットギガビット---> "サーバー1C"(サーバー1)
プラットフォーム速度が失われた
MS SQLの50%バージョン(サーバー1)<-共有メモリ(メモリを介したネットワークなし)--->「サーバー1C」(サーバー1)...
2)ボトルネックは、「1Cクラスター」の個々のコンピューターの数であり、それらが多いほど、同期のコストが高くなり、その結果、システムパフォーマンスが低下します。
3)ボトルネックは、個々のサーバープロセス1の数であり、それらが多いほど、それらを同期するためのコストが高くなります...しかし、ここでは、安定性を確保するために「中間点」を見つける必要があります。 2 *
2 *「明確化」-MS Windowsには次のようなルールがあります。
プロセスはスレッドよりも高価です。つまり、この場合、実際には、同じプロセス内の2つのフロー間の交換レートは、異なるプロセスのフロー間の交換レートよりもはるかに高くなります。
したがって、たとえば、「File 1C 8.x」は常に、クライアント/サーバーバージョンのプラットフォームのシングルユーザー操作の速度を超えます。 すべてがシンプルだから 「File 1C 8.x」の場合、「Relational DBMS」のフローは「Object DBMS」のフローと単一のプロセス内で通信します。
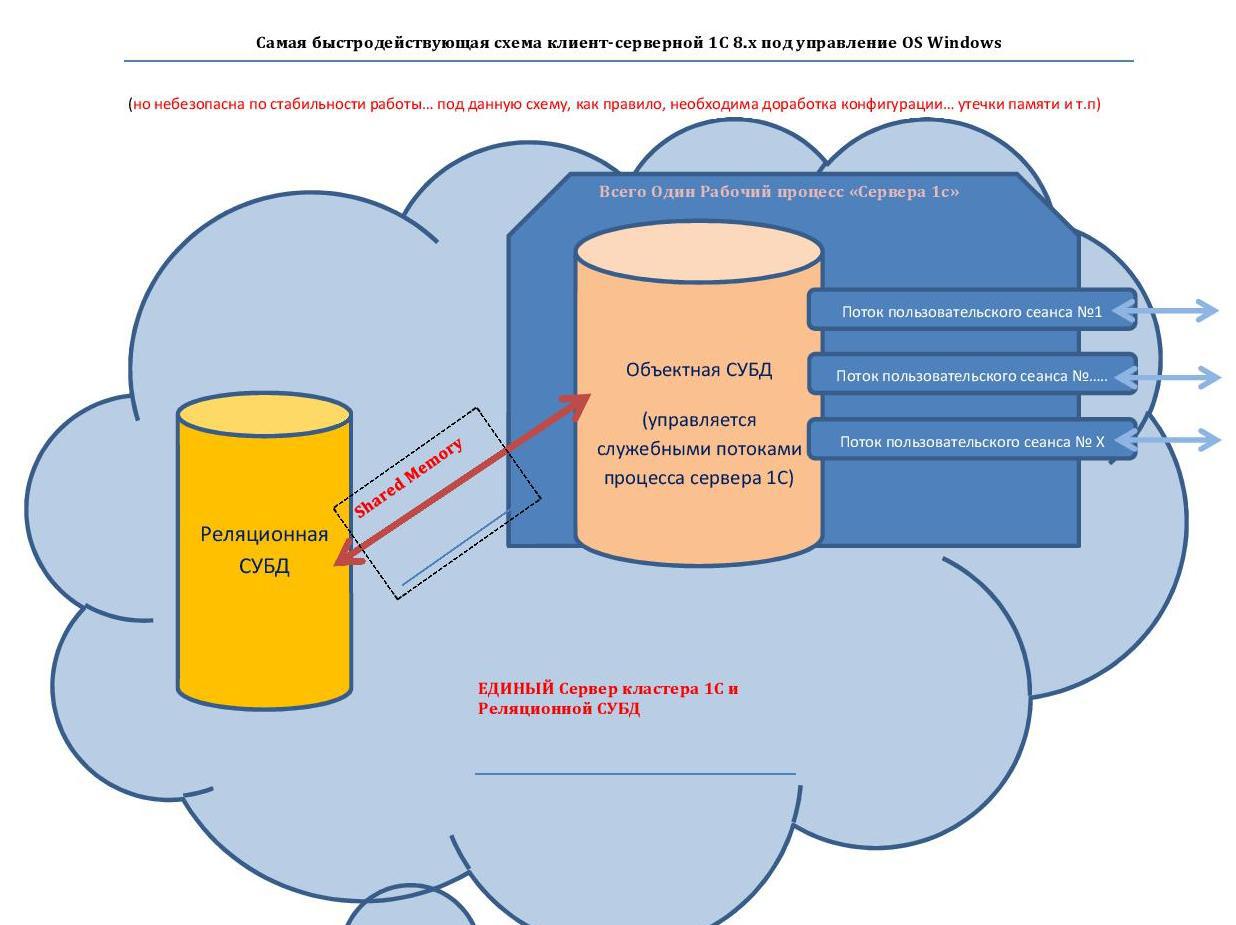
4)ボトルネック-シングルスレッドユーザーセッション 各個別-ユーザーセッションは複数のプラットフォームで並列化されないため、その動作はCPUの1つのコアのリソースの使用に制限されます。したがって、各コアの最大速度が望ましいです。 4コア3 GHz CPU上のプラットフォーム-当然、特定のスレッド数まで。
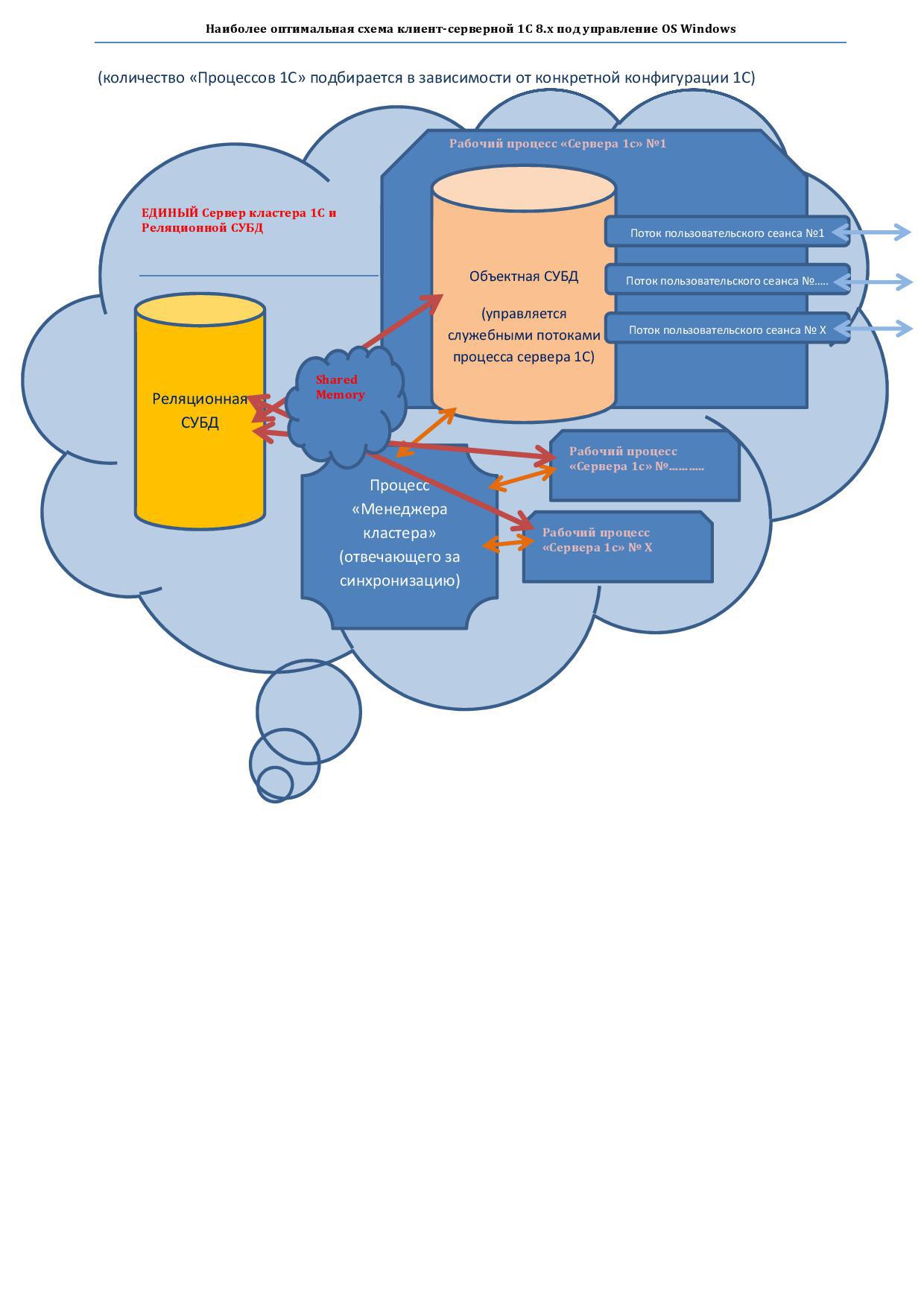
第2章(概要): 非スケーラブルおよびスケーラブルなオプションを検討してください-プラットフォーム1s 8.xの最も効果的なスキーム。 OS Windowsの場合(状況はLinuxでも同様だと思います)
1オプション(スケーラブルではありません)。 「高負荷ユーザーセッション」100個あたり
1)4コア3 GHz CPUを搭載した通常の2ソケットサーバーが効果的です。
2)SSD上の高速ディスクシステム
3)MS SQL <-共有メモリ-> "サーバー1C"
2オプション(スケーラブル)。 100個の 「高負荷のユーザーセッション」 などで 始まります....
ここでは、ドイツの1代「Sap HANA」のパスを辿るのが最も論理的です))
2ソケットマザーボード上の「ブレード」で構成されるSGIのモジュール式「スーパーコンピューター」を組み立てるために、各ブレードはNUMAチップに基づく超高速相互接続の複雑なトポロジで相互に接続され、すべてが単一のOSの制御下にあります。 つまり そのようなサーバー内のプログラムは、定義により、「ブレード」のリソースにアクセスできます。
1)必要な負荷で「ブレード」を追加します... 100ユーザーあたり約1つの「ブレード」の割合。
2)SSD上の高速ディスクシステム
3)MS SQL <-共有メモリ-> "サーバー1C"