あなたが+100の評価で出版物を書いたとします-これはあなたの個人的な評価に値Xを追加します。数十日後、同じXが差し引かれ、それによってあなたを前の場所に戻します。それから、彼らはおそらくそれがどのようなXであり
今日はこの質問に答えます。

(オウムのHabra評価を測定します)
記事の構造
分析的結論
このパートでは、評価関数が満たさなければならない基本的なプロパティを検討し、サブジェクト領域の知識を使用して、特定のタイプの関数を推測しようとします。
主要な前提
原則として、評価に依存するものは何ですか? 任意のユーザーの評価は、他のユーザーのアクション、またはむしろカルマ、トピック、コメントへの投票を使用して形成されます。 Habraの居住者には、ユーザーインジケーターに影響を与える他の方法はありません。 つまり、関数は入力値のカルマ(有理数)、トピック別の投票(整数)、コメント(整数)を受け取り、有理数を返します。
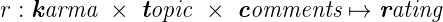
さらに、カルマとコメントおよびトピックへの投票が独立して評価に影響することを知っています。つまり、3項関数は3つの単項関数の構成に分割されます。 これが3つの関数の合計であるとします。
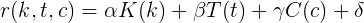
評価関数はどの境界条件を満たすべきですか? 境界条件-新規ユーザーの評価はゼロです。 ユーザーが単一の投稿を書いていない場合、評価に対する投稿の貢献度もゼロであることを意味します。
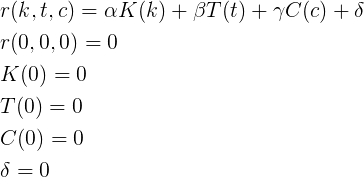
これらの機能について他に何を知っていますか? それらは単調に増加し、計算が簡単である必要があります(つまり、何らかの方法で単純に基本関数で表現される)。 最も単純なオプション、つまり各パラメーターの線形関係を検討してください。
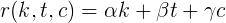
オッズ出力
境界条件を使用すると、これらの係数を簡単に導出できます。 カルマのみが評価に貢献している(つまり、過去30日間に投稿やコメントがない)場合を考えます。

数式の10分の1に等しいアルファを代入します。

最初の係数を受け取ったら、未定義の係数の1つがゼロである別のユーザーを取得し、2番目の係数を計算できます。

式のベータの場所を4/5に置き換えます。
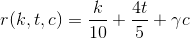
そして最後の仕上げ。
最終式
他のユーザーを取得し、すべてのパラメーターを代入すると、ガンマは1/100になります。
次に、カルマkの評価関数、トピックtの投票、コメントcは、
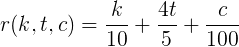
回帰
3つのポイントから推定される式が間違っている可能性があることは明らかです。3つのポイントを通過する関数の数は無限です。 したがって、この仮説は確認する価値があります。 どうやって? 古典的な回帰を使用してデータからこれらの係数を直接取得し、取得した係数と比較してみましょう。
仮説が当てはまる場合、分析に似た係数を持つモデルを取得します(モデルの正確さの信頼性の高いパラメーター)。
カルマの評価とそれに対応するパラメーター、投稿とコメントの投票に関するデータ(Habrには他にも興味深くておいしいデータがたくさんあります)は、ここから入手できます。
github.com/SergeyParamonov/HabraData/blob/master/users_rating.csv
さあ始めましょう
1478 users regular regression Call: lm(formula = rating ~ karma + topic_score + comment_score - 1, data = data) Coefficients: Estimate Std. Error t value Pr(>|t|) karma 0.1017172 0.0006097 166.842 < 2e-16 *** topic_score 0.7862749 0.0020999 374.428 < 2e-16 *** comment_score 0.0153159 0.0031884 4.804 1.72e-06 ***
ご覧のとおり、カルマと投稿の係数の値は実際に一致しており、パラメーターによって判断すると、モデルはこれら2つのパラメーターの評価にかなり自信を持っています。 しかし、3番目のパラメーター(評価へのコメントの寄与)はどうでしょうか。 関数が決定論的であることがわかっている場合、係数の違いはどこから来たのですか?
例外
古典的な回帰は、私たちによって得られた式と真剣に矛盾しているように思われます。それは、3番目のパラメーターの推定が50%異なり、他の2つでは理想的に一致しません。 ただし、古典的な回帰は統計的外れ値に対して非常に不安定であることが知られています。 それらを見てみましょう。つまり、評価値が受け取った分析式とは大幅に異なるポイントのセットです。
>data$dif <- abs(rating - karma/10 - topic_score*0.8 - comment_score/100) >print(data[data$dif > 2, ]) user rating karma topic_score comment_score dif akrot 80.21 25.00 91 13 4.780 anegrey 60.30 31.50 114 15 34.200 Guderian 56.02 119.00 32 6 18.460 ilusha_sergeevich 154.27 157.75 177 11 3.215 ParyshevD 69.27 42.00 130 7 39.000 PatapSmile 48.75 246.00 0 0 24.150 rw6hrm 38.81 33.00 71 1 21.300 varagian 81.34 170.00 50 34 24.000
ここでは、この記事の著者がリストに載っていることを確認できます。 なんで? 30日前に書かれた記事があるため、それはデータサンプルに該当しなかったが、同時に3日以内に投票が消えることを意味します。 したがって、得られた式の評価と証言の違い。
しかし、これはすべてのポイントに当てはまるわけではありません。たとえば、 グデリアンのエントリを取得します。 彼には、過去30日間に境界記事がありません。 違いはどこから来ますか? すべてが非常に簡単です。 TMは、彼の記事がmegamozgに移行したため、Habréでの評価を誤って計算しました。そして、彼が記事に票を失ったのはまさにその上です。

ビンゴ! 間違ったポイントがどこから来るのかを説明しました:
- 30〜33日前にフェードボイスで書かれた境界記事。
- Habrの移動と分割。
- ドラフトまたはオフトピック(UFOまたは著者)で削除された記事。
しかし、これはすべて、答えに対する適合のように聞こえますが、仮説の美しい検証ではありませんか? そして、ここで救助に来ます...
持続可能な回帰
サンプルに外れ値ポイントのセットがあり、それが小さく、たとえば最大5%、ユーザーの十分なサンプル(実験的には1,500のトップで十分)であると仮定します。次に、外れ値に強い回帰法( 堅牢な回帰 )を使用します。 興味深いKDDトピックチュートリアル )。
すぐにメソッドを使用してみましょう:
library("MASS") ... Call: rlm(formula = rating ~ karma + topic_score + comment_score - 1, data = data) Coefficients: Value Std. Error t value karma 0.10 0.00 23463021.30 topic_score 0.80 0.00 54494665.88 comment_score 0.01 0.00 448681.05
出来上がり、係数が見つかり、それらは分析的に得られたものと正確に一致します。
スクリプトとデータ
ここからダウンロードして 、 このデータに適用できます。
スクリプトを使いたくない人のために:
R回帰コード
library("MASS") data <- read.csv("users.csv", header=T, stringsAsFactors=F) names(data) <- c("user","rating","karma","topic_score","comment_score") fit <- lm(data=data, rating ~ karma + topic_score + comment_score - 1) print("regular regression") print(summary(fit)) fit <- rlm(data=data, rating ~ karma + topic_score + comment_score - 1) print("robust regression") print(summary(fit)) attach(data) data$dif <- abs(rating - karma/10 - topic_score*0.8 - comment_score/100) print(data[data$dif > 2, ])
関数を非表示にするのが役に立たない理由
ここでは、もちろん、注意深い読者は次のように言うことができます。「さて、今TMは新しい秘密の評価計算機能を考え出す必要があります」。
評価の主な特性は次のとおりです。
- 評価は、他のユーザーと投票チャネルのアクションのみに依存しますが、そのうち3つのみです。投稿、コメント、カルマへの投票。
- 投稿、カルマ、コメントの投票は互いに独立しています。 関数は常に、投稿、コメント、およびカルマからの3つの独立した単項関数の構成に分解されます。
- 評価指標は多数のユーザーに対して絶えず再集計する必要があるため、これらの各関数は簡単かつ迅速に計算する必要があります。
- 同じ理由で、単調に増加する初等関数で表現できるはずです。
- 関数は確定的でノイズのないものである必要があります。つまり、カルマが同じで投稿とコメントが2人のユーザーの場合、評価は同じでなければなりません(有効期間= 30日)。
これにより、安定した回帰の方法と単項関数の選択を互いに別々に使用して、基本的な収集データを使用してこの関数を自動的に復元できます。 ノイズ、非決定的要素、および確率の導入は、タスクをわずかに複雑にするだけであり、パラメータの精度にわずかに影響する可能性があります。
ここでも、あいまいさによるセキュリティは機能しません。
これで何ができますか?
Habr-monitorを書いたとき(これはHabr-analyticsの一部であり、 Habrに書き込むと、リソースが役に立つかもしれません)、記事のパラメーターの変更を時間内に表示します。最初に留めたいのは、時間内の音声の変更です。 いくつかの理由により、このオプションは投稿に投票する前に表示できません。 ユーザー評価の分析機能を使用すると、現在の記事の評価をいつでも表示できます(1であり、現時点で投票が「失われた」記事がない場合)。
実際、この機能を使用すると、 記事評価パラメーターをモニターに固定できます(下図)。
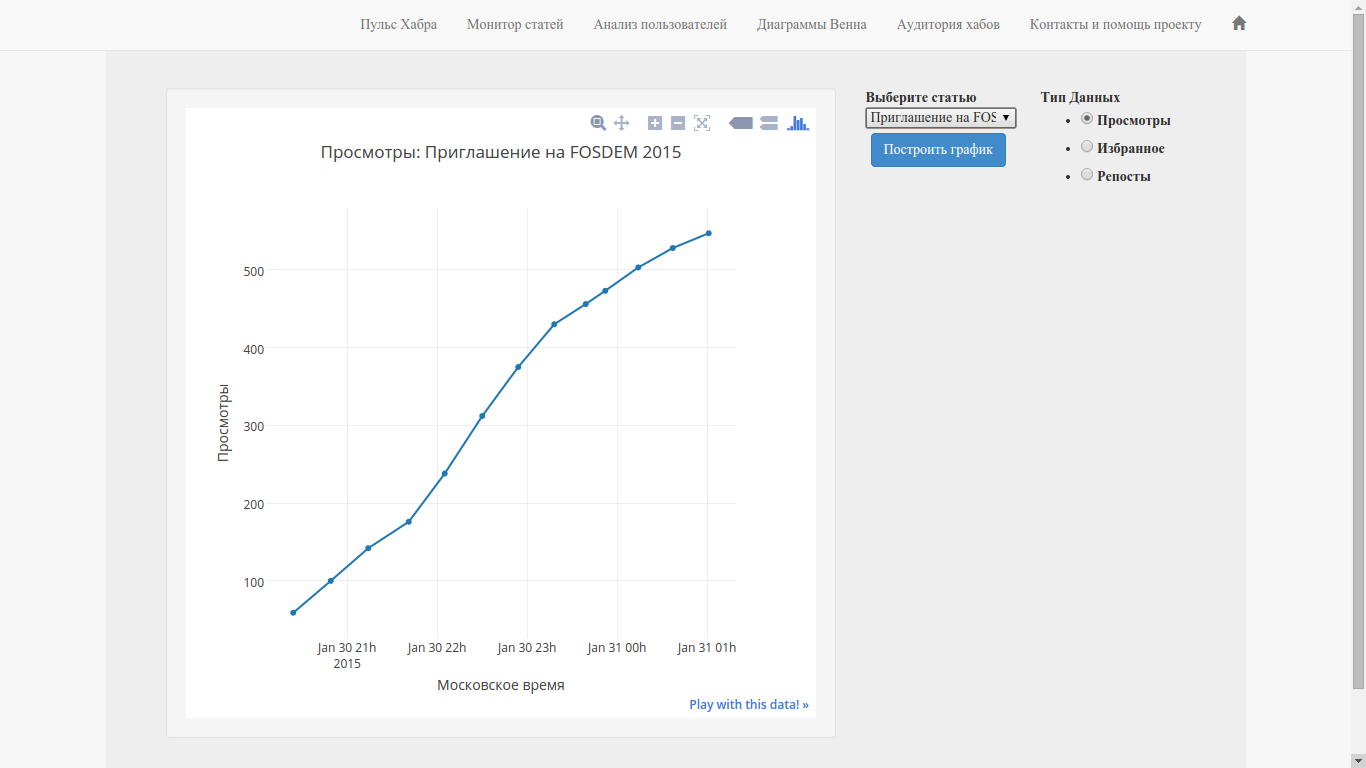
これにより、 SoHabrは記事の評価を固定することもできます。
式の解釈
コメントへの投票は、実質的に評価に寄与しません。Habrの歴史全体で最も評価の高いコメント(〜400 +)でも、評価に4〜5ポイント、つまり6〜7プラスの記事が追加されます。
カルマは格付けに関して重みを失いました。以前は係数が0.5でしたが、現在は0.1であるため、トップはより動的になります(以前はトップ10に入ることはほとんど不可能でした)。
記事の5票ごとに評価に4ポイントが加算されます。つまり、記事の0.8票を掛けると、評価が増加します。 現時点では、これが最も重要であり、実際にユーザーの評価を決定する唯一の要因です。
それでも、 X = 80です。
PSステートメント( ここから )
[...]時間が経つにつれて、評価はカルマの半分の値になります。すでに間違っています。