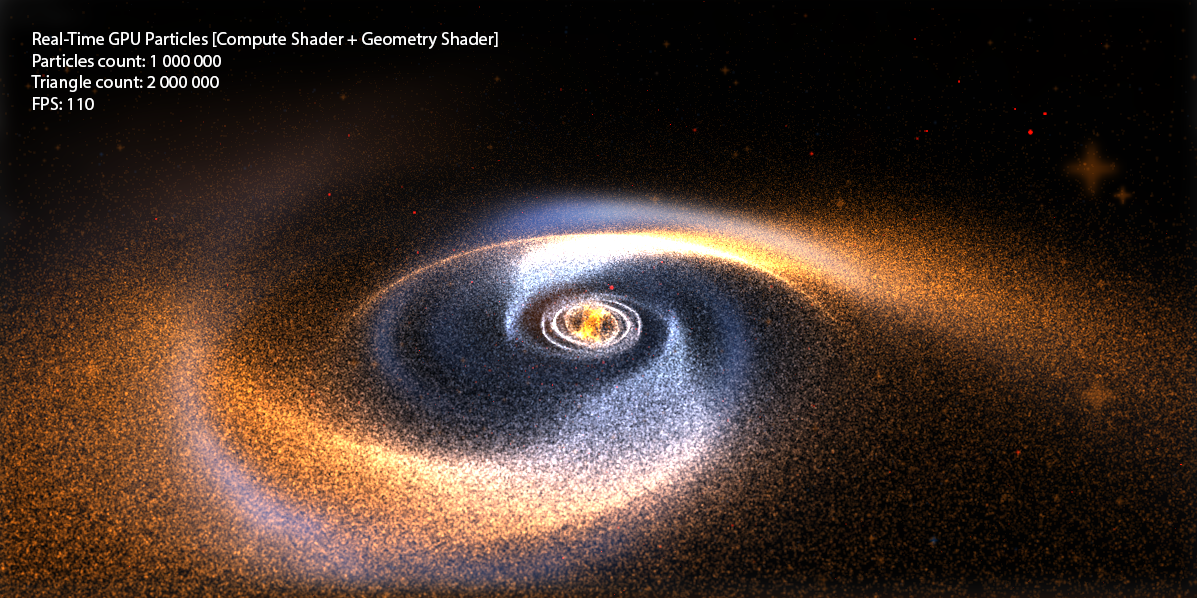
今日は、グラフィックパイプラインの研究を続けます.100,000以上のパーティクルのシステムを作成する例で、 Compute ShaderやGeometry Shaderなどのすばらしいことについて話します。これらのシステムは、ポイントではなく、正方形( ビルボードクワッド )であり、独自のテクスチャを持っています。 言い換えると、 FPS> 100の 2,000,000以上のテクスチャ付き三角形を出力します (予算GeForce 550 Tiグラフィックカード上 )。
はじめに
私は自分の記事の中でシェーダーについて多くのことを書きましたが、私たちは常に2つのタイプのみを操作しました: 頂点シェーダー 、 ピクセルシェーダー 。 ただし、 DX10 +の登場により、 ジオメトリシェーダー、ドメインシェーダー、ハルシェーダー、コンピュートシェーダーという新しいタイプのシェーダーが登場しました。 念のため、グラフィックスパイプラインがどのように見えるかを思い出させてください。
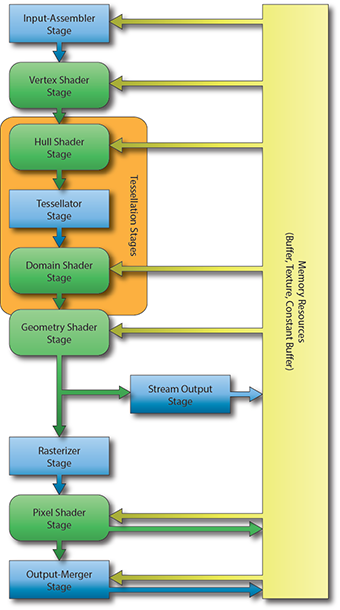
この記事ではDomain ShaderとHull Shaderについては触れないことをすぐに言わなければなりません。次の記事でテッセレーションについて書きます。
ジオメトリシェーダーのみが未探索のままです。 ジオメトリシェーダーとは何ですか?
第1章:ジオメトリシェーダー
頂点シェーダーは頂点処理を処理し、 ピクセルシェーダーはピクセル処理を処理します。ご想像のとおり 、 ジオメトリシェーダーはプリミティブ処理を処理します。
このシェーダーは、パイプラインのオプション部分です。 まったく存在しない場合があります。頂点は直接プリミティブアセンブリステージに進み、その後、プリミティブがラスタライズされます。
ジオメトリシェーダーは、 プリミティブアセンブリステージとラスタライザーステージの間にあります。
入り口で、彼は組み立てられたプリミティブと隣接するプリミティブの両方に関する情報を取得できます。
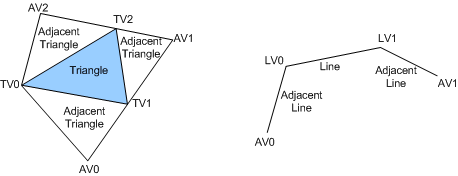
出力には、プリミティブのストリームがあり、プリミティブを追加します。 さらに、返されるプリミティブのタイプは入力のものと異なる場合があります。 たとえば、 Pointを取得してLineを返します。 何もせずに単純に入力を出力に接続する単純な幾何学的シェーダーの例:
struct PixelInput { float4 Position : SV_POSITION; // System-Value }; [maxvertexcount(1)] // - , void SimpleGS( point PixelInput input[1], inout PointStream<PixelInput> stream ) { PixelInput pointOut = input[0]; // stream.Append(pointOut); // stream.RestartStrip(); // ( Point – ) }
第2章:StructuredBuffer
DirectX10 +は、 構造化バッファなどのタイプのバッファを導入しました。このようなバッファは、プログラマが望むように記述することができます。 古典的な意味では、それはGPUのメモリに格納されている特定のタイプの構造の同種の配列です。
パーティクルシステム用に同様のバッファを作成してみましょう。 粒子が持つ特性を説明しましょう( C#側 ):
public struct GPUParticleData { public Vector3 Position; public Vector3 Velocity; };
そして、バッファー自体を作成します( SharpDX.Toolkitヘルパーを使用 ):
_particlesBuffer = Buffer.Structured.New<GPUParticleData>(graphics, initialParticles, true);
initialParticlesは、必要な数のパーティクルのサイズを持つGPUParticleDataの配列です。
バッファの作成時に次のフラグが設定されることに注意してください。
BufferFlags.ShaderResource-シェーダーからバッファーにアクセスする機能用
BufferFlags.StructuredBuffer-バッファーを示します
BufferFlags.UnorderedAccess-シェーダーからバッファーを変更する機能用
1,000,000要素のバッファを作成し、ランダムな要素で埋めます:
GPUParticleData[] initialParticles = new GPUParticleData[PARTICLES_COUNT]; for (int i = 0; i < PARTICLES_COUNT; i++) { initialParticles[i].Position = random.NextVector3(new Vector3(-30f, -30f, -30f), new Vector3(30f, 30f, 30f)); }
その後、ランダムな値を持つ1,000,000要素のバッファーがGPUメモリに保存されます。
第3章点粒子のレンダリング
次に、このバッファをどのように描画するかを理解する必要がありますか? 結局のところ、頂点すらありません! 構造バッファーの値に基づいて、その場で頂点を生成します。
頂点シェーダーとピクセルシェーダーの 2つのシェーダーを作成します。
まず、シェーダーの入力データについて説明します。
struct Particle // GPU { float3 Position; float3 Velocity; }; StructuredBuffer<Particle> Particles : register(t0); // cbuffer Params : register(b0) // { float4x4 View; float4x4 Projection; }; // .. , ID Vertex Buffer struct VertexInput { uint VertexID : SV_VertexID; }; struct PixelInput // Vertex Shader { float4 Position : SV_POSITION; }; struct PixelOutput // { float4 Color : SV_TARGET0; };
さて、シェーダー、スターター、頂点を詳しく見てみましょう:
PixelInput DefaultVS(VertexInput input) { PixelInput output = (PixelInput)0; Particle particle = Particles[input.VertexID]; float4 worldPosition = float4(particle.Position, 1); float4 viewPosition = mul(worldPosition, View); output.Position = mul(viewPosition, Projection); return output; }
この魔法の国では、現在のVertexIDに従ってパーティクルバッファから特定のパーティクルを読み取り( 0〜999999の範囲にあります)、パーティクルの位置を使用して、スクリーンスペースに投影します。
まあ、 ピクセルシェーダーを使用すると、それはそれと同じくらい簡単です:
PixelOutput DefaultPS(PixelInput input) { PixelOutput output = (PixelOutput)0; output.Color = float4((float3)0.1, 1); return output; }
パーティクルの色をfloat4(0.1、0.1、0.1、1)として設定します。 なぜ0.1なのか? 100万個の粒子があるため、 Additive Blendingを使用します。
バッファを定義し、ジオメトリを描画します。
graphics.ResetVertexBuffers(); // graphics.SetBlendState(_additiveBlendState); // Additive Blend State // SRV ( ). _particlesRender.Parameters["Particles"].SetResource<SharpDX.Direct3D11.ShaderResourceView>(0, _particlesBuffer); // _particlesRender.Parameters["View"].SetValue(camera.View); _particlesRender.Parameters["Projection"].SetValue(camera.Projection); // _particlesRender.CurrentTechnique.Passes[0].Apply(); // 1000000 graphics.Draw(PrimitiveType.PointList, PARTICLES_COUNT);
さて、最初の勝利を楽しみましょう:

第4章:QuadBillboardパーティクルのレンダリング
最初の章を忘れていない場合は、ポイントのセットを2つの三角形で構成される本格的なビルボードに安全に変更できます。
QuadBillboardについて少し説明します 。これは2つの三角形で構成される正方形で、この正方形は常にカメラの方向を向いています。
この正方形を作成するには? このような正方形をすばやく生成するためのアルゴリズムを考え出す必要があります。 頂点シェーダーで何かを見てみましょう。 SV_Positionを構築するとき、3つのスペースがあります。
- ワールド空間 -ワールド座標での頂点の位置
- ビュー空間 -ビュー座標の頂点位置
- 投影空間 -スクリーン座標の頂点位置
ビュースペースは必要なものです。これらの座標は、カメラとプレーン(-1 + px、-1 + py、pz)に相対的であるためです->(1 + px、1 + py、pz)このスペースで作成された常にカメラに向けられた法線を持ちます。
したがって、シェーダーで何かを変更します。
PixelInput TriangleVS(VertexInput input) { PixelInput output = (PixelInput)0; Particle particle = Particles[input.VertexID]; float4 worldPosition = float4(particle.Position, 1); float4 viewPosition = mul(worldPosition, View); output.Position = viewPosition; output.UV = 0; return output; }
SV_Positionの出力は、 ViewSpaceのGeometry Shaderで新しいプリミティブを作成するために、 ProjectionSpace-positionではなくViewSpace-positionに転送されます。
新しいステージを追加します。
// Projection Space PixelInput _offsetNprojected(PixelInput data, float2 offset, float2 uv) { data.Position.xy += offset; data.Position = mul(data.Position, Projection); data.UV = uv; return data; } [maxvertexcount(4)] // GS – 4 , TriangleStrip void TriangleGS( point PixelInput input[1], inout TriangleStream<PixelInput> stream ) { PixelInput pointOut = input[0]; const float size = 0.1f; // // stream.Append( _offsetNprojected(pointOut, float2(-1,-1) * size, float2(0, 0)) ); stream.Append( _offsetNprojected(pointOut, float2(-1, 1) * size, float2(0, 1)) ); stream.Append( _offsetNprojected(pointOut, float2( 1,-1) * size, float2(1, 0)) ); stream.Append( _offsetNprojected(pointOut, float2( 1, 1) * size, float2(1, 1)) ); // TriangleStrip stream.RestartStrip(); }
さて、 UVがあるので、ピクセルシェーダーでテクスチャを読み取ることができます。
PixelOutput TrianglePS(PixelInput input) { PixelOutput output = (PixelOutput)0; float particle = ParticleTexture.Sample(ParticleSampler, input.UV).x * 0.3; output.Color = float4((float3)particle, 1); return output; }
さらに、レンダリングのためにサンプラーとパーティクルテクスチャを設定します。
_particlesRender.Parameters["ParticleSampler"].SetResource<SamplerState>(_particleSampler); _particlesRender.Parameters["ParticleTexture"].SetResource<Texture2D>(_particleTexture);
チェック、テスト:
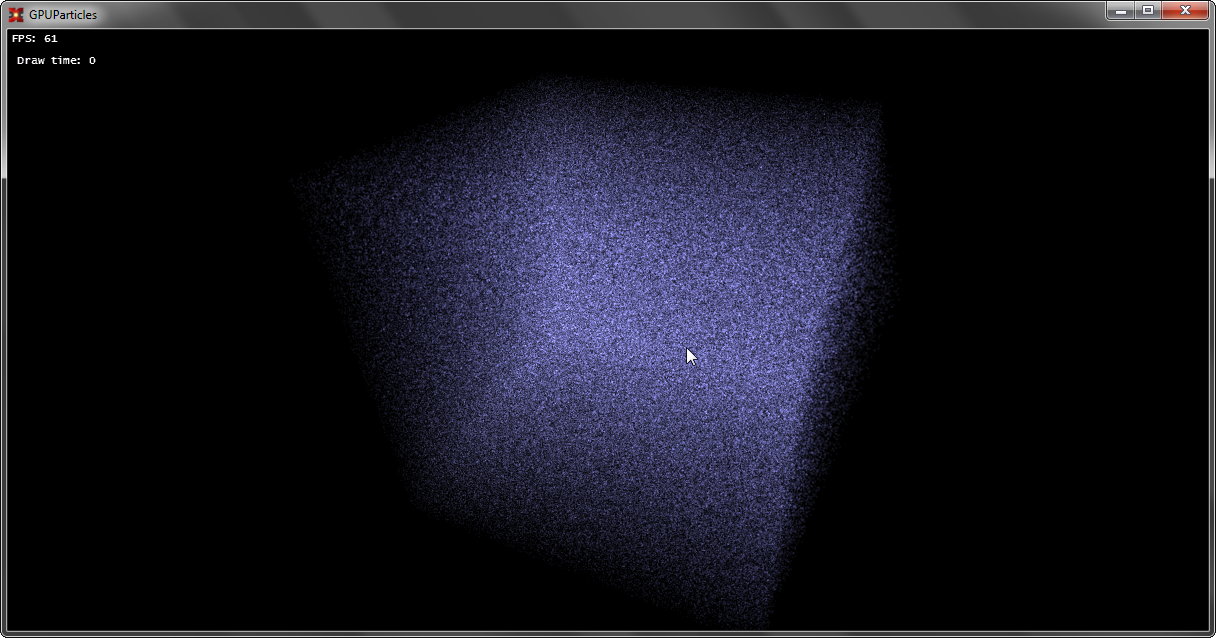
第5章:パーティクルモーション
これで、すべての準備が整いました。GPUメモリに特別なバッファーがあり、 Geometry Shaderを使用して構築されたパーティクルレンダラーがありますが、同様のシステムは静的です。 もちろん、 CPU上の位置を変更し、毎回GPUからバッファーデータを読み取って変更し、それからロードし直すこともできますが、どのような種類のGPUパワーについて話すことができますか? このようなシステムは、100,000個の粒子に耐えられません。
そして、そのようなバッファーを使用してGPUで作業するには、特別なシェーダーであるCompute Shaderを使用できます。 従来のレンダーパイプラインの外側にあり、個別に使用できます。
計算シェーダーとは何ですか?
言い換えれば、 Compute Shaderはパイプラインの特別な段階であり、従来のすべてを置き換えます(ただし、それでも使用できます) 。GPUを使用して任意のコードを実行し、バッファー(テクスチャバッファーを含む)にデータを読み書きできます。 ) さらに、このコードの実行は、開発者が設定するのと並行して発生します。
最も単純なコードの実行を見てみましょう。
[numthreads(1, 1, 1)] void DefaultCS( uint3 DTiD: SV_DispatchThreadID ) { // DTiD.xyz - // ... } technique ComputeShader { pass DefaultPass { Profile = 10.0; ComputeShader = DefaultCS; } }
コードの最初に、グループ内のスレッドの数を示すnumthreadsフィールドがあります。 グループストリームを使用し、グループごとに1つのストリームがあることを確認するまで。
uint3 DTiD.xyzは現在のストリームを指します。
次の段階はこのようなシェーダーの起動で、次のように実行されます。
_effect.CurrentTechnique.Passes[0].Apply(); graphics.Dispatch(1, 1, 1);
Dispatchメソッドでは、必要なストリームグループの数を示します。各ディメンションの最大数は65536に制限されています。 そして、そのようなコードを実行すると、GPU上のシェーダーコードが1回実行されます。 スレッドのグループは1つあり、各グループには1つのスレッドがあります。 たとえば、 Dispatch( 5、1、1)と入力すると、 GPUのシェーダーコードは5回、5つのスレッドグループで実行され、各グループには1つのスレッドがあります。 numthreads->(5、1、1)も変更すると、コードは25回、5つのスレッドのグループで、5つのスレッドの各グループで実行されます。 より詳細には、写真を見るかどうかを検討できます。
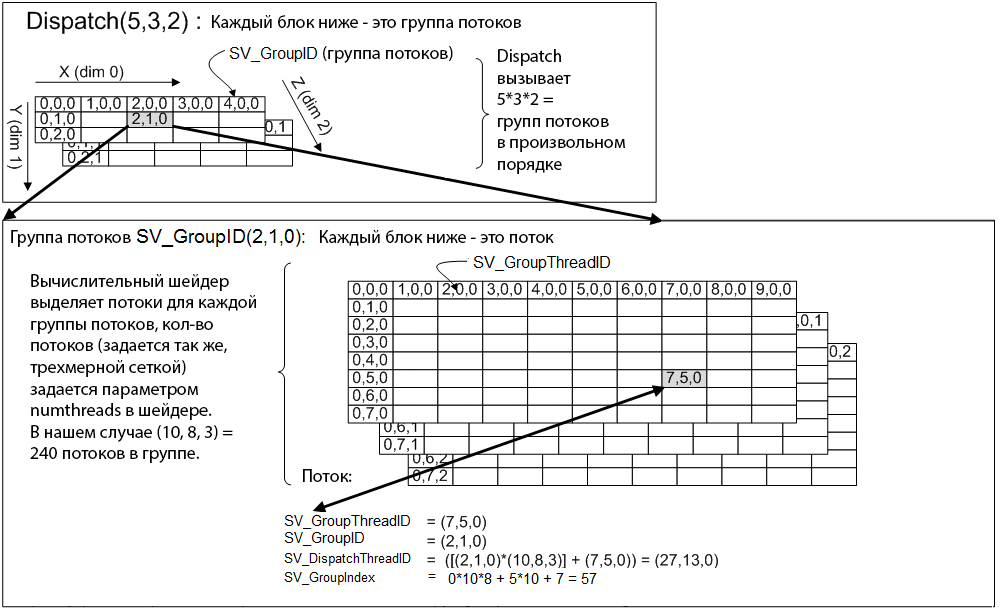
さて、パーティクルシステムに戻りましょう。 1,000,000の要素の1次元配列があり、タスクは粒子の位置を処理することです。 なぜなら 粒子は互いに独立して移動するため、この問題は非常によく並列化されます。
DX10 ( DX10カードをサポートするために使用するこのCSの特定バージョン)では、ストリームのグループごとのストリームの最大数は768であり、3次元すべてで使用されます。 各スレッドグループに対して合計で32 * 24 * 1 = 768スレッドを作成します。 1つのグループは、 768個のパーティクル(1ストリーム-1パーティクル)を処理できます。 次に、 N番目のパーティクルカウントを処理するために、必要なフローのグループ数を計算する必要があります(1つのグループが768個のパーティクルを処理するという事実を考慮して)。
これは次の式で計算できます。
int numGroups = (PARTICLES_COUNT % 768 != 0) ? ((PARTICLES_COUNT / 768) + 1) : (PARTICLES_COUNT / 768); double secondRoot= System.Math.Pow((double)numGroups, (double)(1.0 / 2.0)); secondRoot= System.Math.Ceiling(secondRoot); _groupSizeX = _groupSizeY = (int)secondRoot;
その後-Dispatch(_groupSizeX、_groupSizeY、1)を呼び出すことができ、シェーダーはN番目の要素を並行して処理できます。
特定の要素にアクセスするには、次の式を使用します。
uint index = groupID.x * THREAD_IN_GROUP_TOTAL + groupID.y * GROUP_COUNT_Y * THREAD_IN_GROUP_TOTAL + groupIndex;
更新されたシェーダーコードは次のとおりです。
struct Particle { float3 Position; float3 Velocity; }; cbuffer Handler : register(c0) { int GroupDim; uint MaxParticles; float DeltaTime; }; RWStructuredBuffer<Particle> Particles : register(u0); #define THREAD_GROUP_X 32 #define THREAD_GROUP_Y 24 #define THREAD_GROUP_TOTAL 768 [numthreads(THREAD_GROUP_X, THREAD_GROUP_Y, 1)] void DefaultCS( uint3 groupID : SV_GroupID, uint groupIndex : SV_GroupIndex ) { uint index = groupID.x * THREAD_GROUP_TOTAL + groupID.y * GroupDim * THREAD_GROUP_TOTAL + groupIndex; [flatten] if(index >= MaxParticles) return; Particle particle = Particles[index]; float3 position = particle.Position; float3 velocity = particle.Velocity; // payload particle.Position = position + velocity * DeltaTime; particle.Velocity = velocity; Particles[index] = particle; } technique ParticleSolver { pass DefaultPass { Profile = 10.0; ComputeShader = DefaultCS; } }
ここで別の魔法が発生します。パーティクルバッファを特別なリソースとして使用します: RWStructuredBuffer 。これは、このバッファの読み取りと書き込みができることを意味します。
(!)書き込みの前提条件-作成中にこのバッファーにUnorderedAccessフラグを付ける必要があります。
最後の段階では、シェーダーのリソースをUnorderedAccessViewバッファーとして設定し、 Dispatchを呼び出します。
/* SOLVE PARTICLES */ _particlesSolver.Parameters["GroupDim"].SetValue(_threadGroupSize); _particlesSolver.Parameters["MaxParticles"].SetValue(PARTICLES_COUNT); _particlesSolver.Parameters["DeltaTime"].SetValue(deltaTime); _particlesSolver.Parameters["Particles"].SetResource<SharpDX.Direct3D11.UnorderedAccessView>(0, _particlesBuffer); _particlesSolver.CurrentTechnique.Passes[0].Apply(); graphics.Dispatch( _threadSize, _threadSize, 1); _particlesSolver.CurrentTechnique.Passes[0].UnApply(false);
コードの実行が完了したら、シェーダーからUnorderedAccessViewを削除する必要があります。削除しないと、使用できません。
粒子で何かをしてみましょう、簡単なソルバーを書きます:
float3 _calculate(float3 anchor, float3 position) { float3 direction = anchor - position; float distance = length(direction); direction /= distance; return direction * max(0.01, (1 / (distance*distance))); } // main { ... velocity += _calculate(Attractor, position); velocity += _calculate(-Attractor, position); ... }
定数バッファーにアトラクターを設定します。
コンパイル、実行、お楽しみください:
結論1
パーティクルについて言えば、完全で強力なパーティクルシステムの作成を妨げるものはありません。ポイントは簡単にソートでき(透明性を確保)、描画時にソフトパーティクルテクニックを適用し、「非発光」パーティクルのライティングも考慮します。 計算シェーダーは、主にボケぼかし効果(ここではより幾何学的なものが必要です)の作成、 タイル化された遅延レンダラーの作成などに使用されます。 たとえば、ジオメトリシェーダーは、多くのジオメトリを生成する必要がある場合に使用できます。 最も顕著な例は、草と粒子です。 ところで、 GSとCSの使用は無限であり、開発者の想像力によってのみ制限されます。
結論2
伝統的に、私は完全なソースコードとデモを投稿に添付します。
PSデモを実行するには-DX10およびCompute Shaderをサポートするビデオカードが必要です。
結論3
私が書いたものに人々が興味を示したとき、私はとても喜んでいます。 そして、私にとっては、記事に対する反応は非常に重要です。建設的なコメントを伴うプラスまたはマイナスの形であれ。 だから、どのトピックがhabrasocietyにとってより興味深いもので、どのトピックがそうでないかを判断できます。