ワーキンググループの機能の説明
ワークグループの機能には、ワークグループのレベルの3つの古典的なアルゴリズム( 値ブロードキャスト、リデュース、スキャン )と、ワークグループ全体に対して実行された操作の論理結果をチェックする2つの組み込み関数が含まれます。 削減およびスキャンアルゴリズムは、加算、最小、および最大の操作をサポートしています。
ワークグループの組み込み関数の機能は、名前から明らかです。
- work_group_broadcast()は、選択したワークアイテムの値をすべてのワークグループアイテムに拡張します。
- work_group_reduce()は、ワークグループのすべての要素の合計、最小、または最大値を計算し、結果の値をワークグループのすべての要素に拡張します。
- work_group_scan()は、以前のすべての作業項目の合計、最小、または最大値を計算します(現在の作業項目を含めることができます)。
- work_group_all()は、各作業項目に対して計算された同じ論理式の論理ANDを返します。
- work_group_any()はwork_group_all()と同様に機能しますが、論理ORを使用します。
リストされている組み込み関数に関する重要な制限:スカラーデータ型にのみ適用されます(たとえば、一般的な型int4とfloat4はサポートされていません)。 また、charやucharなどの8ビットデータ型はサポートされていません。
ワーキンググループの機能は、その名前が示すとおり、ワーキンググループ全体で常に並行して機能します。 これから暗黙の結果が生じます。ワーキンググループの機能に対するいかなる挑戦も障壁として機能します。
ワーキンググループの機能を使用するには、2つの主なアイデアがあります。 第一に、ワーキンググループの機能は便利です。 OpenCL 1.2で同じ機能を実装するために必要な十分に大きなコードを記述する代わりに、1つの組み込み関数を使用する方がはるかに簡単です。 第二に、ワーキンググループの機能は、機器の最適化を使用するため、生産性の点でより効果的です。
例として、次のタスク(アルゴリズムの一部である可能性があります)を考えてみましょう:より大きな配列と同じサイズの従属配列の接頭辞の合計を計算します。 そのため、各スレーブ配列の各要素のプレフィックスの合計を計算し、同じマークアップでターゲットメモリ領域に保存する必要があります。 次の図に、ソースとターゲットのデータレイアウトを示します。
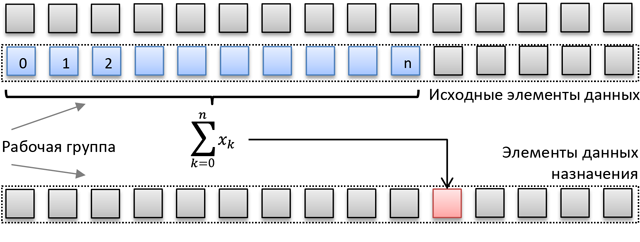
このタスクのシンプルなOpenCLコアは次のようになります。
- 各配列(図の線)は1つのワーキンググループによって処理されます。
- 各作業項目について、前の項目の単純なfor()ループを使用してスキャンが実行され、累積プレフィックス値が追加され、結果が宛先に保存されます。
- ワークグループのサイズが入力配列よりも小さい場合、ソースインデックスとエンドインデックスはワークグループのサイズだけシフトされ、集約プレフィックスが更新され、このプロセスがソース行の最後まで繰り返されます。
対応するコードを以下に示します。
コード
__kernel void Calc_wg_offsets_naive( __global const uint* gHistArray, __global uint* gPrefixsumArray, uint bin_size ) { uint lid = get_local_id(0); uint binId = get_group_id(0); //calculate source/destination offset for workgroup uint group_offset = binId * bin_size; local uint maxval; //initialize cumulative prefix if( lid == 0 ) maxval = 0; barrier(CLK_LOCAL_MEM_FENCE); do { //perform a scan for every workitem uint prefix_sum=0; for(int i=0; i<lid; i++) prefix_sum += gHistArray[group_offset + i]; //store result gPrefixsumArray[group_offset + lid] = prefix_sum + maxval; prefix_sum += gHistArray[group_offset + lid]; //update group offset and cumulative prefix if( lid == get_local_size(0)-1 ) maxval += prefix_sum; barrier(CLK_LOCAL_MEM_FENCE); group_offset += get_local_size(0); } while(group_offset < (binId+1) * bin_size); }
このような原始的なアプローチは、ほとんどの場合非常に効果的ではありません(非常に小さなワークグループを除く)。 明らかに、内部のfor()ループは冗長なロードと追加の操作が多すぎます。 この手順は明らかに最適化できます。 さらに、ワーキンググループのサイズが増加すると、冗長性も増加します。 ハードウェアリソースをより効率的に使用するには、Intel HD GraphicsにはBlellochなどのより効率的なアルゴリズムが必要です。 詳細については検討しません。これは、古典的なGPU Gemsの記事で顕著に説明されています。
並列スキャンを使用したOpenCL 1.2コードは次のようになります。
コード
#define WARP_SHIFT 4 #define GRP_SHIFT 8 #define BANK_OFFSET(n) ((n) >> WARP_SHIFT + (n) >> GRP_SHIFT) __kernel void Calc_wg_offsets_Blelloch(__global const uint* gHistArray, __global uint* gPrefixsumArray, uint bin_size ,__local uint* temp ) { int lid = get_local_id(0); uint binId = get_group_id(0); int n = get_local_size(0) * 2; uint group_offset = binId * bin_size; uint maxval = 0; do { // calculate array indices and offsets to avoid SLM bank conflicts int ai = lid; int bi = lid + (n>>1); int bankOffsetA = BANK_OFFSET(ai); int bankOffsetB = BANK_OFFSET(bi); // load input into local memory temp[ai + bankOffsetA] = gHistArray[group_offset + ai]; temp[bi + bankOffsetB] = gHistArray[group_offset + bi]; // parallel prefix sum up sweep phase int offset = 1; for (int d = n>>1; d > 0; d >>= 1) { barrier(CLK_LOCAL_MEM_FENCE); if (lid < d) { int ai = offset * (2*lid + 1)-1; int bi = offset * (2*lid + 2)-1; ai += BANK_OFFSET(ai); bi += BANK_OFFSET(bi); temp[bi] += temp[ai]; } offset <<= 1; } // clear the last element if (lid == 0) { temp[n - 1 + BANK_OFFSET(n - 1)] = 0; } // down sweep phase for (int d = 1; d < n; d <<= 1) { offset >>= 1; barrier(CLK_LOCAL_MEM_FENCE); if (lid < d) { int ai = offset * (2*lid + 1)-1; int bi = offset * (2*lid + 2)-1; ai += BANK_OFFSET(ai); bi += BANK_OFFSET(bi); uint t = temp[ai]; temp[ai] = temp[bi]; temp[bi] += t; } } barrier(CLK_LOCAL_MEM_FENCE); //output scan result to global memory gPrefixsumArray[group_offset + ai] = temp[ai + bankOffsetA] + maxval; gPrefixsumArray[group_offset + bi] = temp[bi + bankOffsetB] + maxval; //update cumulative prefix sum and shift offset for next iteration maxval += temp[n - 1 + BANK_OFFSET(n - 1)] + gHistArray[group_offset + n - 1]; group_offset += n; } while(group_offset < (binId+1) * bin_size); }
原則として、このようなコードはより効率的に機能し、ハードウェアリソースにそれほど高い負荷をかけませんが、いくつかの注意事項があります。
このコードには、ローカルメモリとグローバルメモリ間でデータを移動するためのオーバーヘッドと、いくつかの禁止事項があります。 本当に高い効率を達成するには、アルゴリズムに十分に大きなワークグループサイズが必要です。 小さなワークグループ(<16)では、生産性が単純なサイクルの生産性よりも高くなる可能性は低いです。
さらに、コードの複雑さと、共有ローカルメモリ( BANK_OFFSETマクロなど)の競合を排除するように設計された追加のロジックに注意してください。
ワーキンググループの使用は、言及されたすべての問題を回避します。 最適化されたOpenCLコードの対応するバージョンを以下に示します。
コード
__kernel void Calc_wg_offsets_wgf( __global const uint* gHistArray, __global uint* gPrefixsumArray, uint bin_size ) { uint lid = get_local_id(0); uint binId = get_group_id(0); uint group_offset = binId * bin_size; uint maxval = 0; do { uint binValue = gHistArray[group_offset + lid]; uint prefix_sum = work_group_scan_exclusive_add( binValue ); gPrefixsumArray[group_offset + lid] = prefix_sum + maxval; maxval += work_group_broadcast( prefix_sum + binValue, get_local_size(0)-1 ); group_offset += get_local_size(0); } while(group_offset < (binId+1) * bin_size); }
両方の最適化されたアルゴリズムのパフォーマンス結果は、十分な量の入力データで測定されました(各ワーキンググループは、ローカルサイズに応じて、外部サイクルの8192 ... 2048回の繰り返しに対応する65 536要素をスキャンします)。

予想どおり、ローカルサイズが大きくなると単純なループの動作が非常に遅くなり、最適化された両方のオプションのパフォーマンスが向上します。
特定のアルゴリズムに対してワーキンググループの最適なサイズを設定した場合、コアの比較は次のようになります。

work_group_scan_exclusive_add()を使用すると、あらゆるサイズのワークグループのパフォーマンスが大幅に向上すると同時に、コードが簡素化されることに注意してください。
異種OpenCL 2.0ワークグループ
OpenCL実行モデルには、NDRangeの個々のワークアイテムのグループであるワークグループの概念が含まれています。 アプリケーションがOpenCL 1.xを使用する場合、NDRangeのサイズは完全に(トレースなしで)ワークグループのサイズで除算する必要があります。 clEnqueueNDRangeKernel呼び出しに、完全に分割されていないglobal_sizeパラメーターとlocal_sizeパラメーターが含まれている場合、呼び出しはエラーコードCL_INVALID_WORK_GROUP_SIZEを返します。 clEnqueueNDRangeKernel呼び出しがlocal_sizeパラメーターにNULL値を指定し、実行可能モジュールがワークグループのサイズを選択できる場合、実行可能モジュールは、グローバルNDRangeサイズを完全に分割できるサイズを選択する必要があります。
NDRangeのサイズが完全に分割されるように、ワーキンググループのこのようなサイズを選択する必要性は、開発者にとって困難を引き起こす可能性があります。 単純な3x3画像ぼかしアルゴリズムを検討してください。 このアルゴリズムでは、各出力ピクセルは、隣接する3x3領域の入力ピクセルの値の平均値として計算されます。 画像フレームにある出力ピクセルを処理する場合、これらのピクセルは入力画像の境界の外側のピクセルに依存するため、問題が発生します。

一部のアプリケーションでは、フレームの入力値は重要ではなく、スキップすることができます。 この場合、NDRangeのサイズは、出力イメージのサイズからフレームの領域を引いたサイズと同じです。 多くの場合、完全に分離するのが難しいNDRangeサイズになります。 たとえば、3x3フィルターを1920x1080画像に適用するには、両側に1ピクセルの厚さのフレームが必要です。 これを行う最も簡単な方法は、1918x1078コアを使用することです。 しかし、1918年も1078年も、最適なサイズのワーキンググループを提供する値に完全に分割されていません。
OpenCL 2.0には、前のセクションで説明した問題を修正する新しい機能があります。 いわゆる異種ワークグループについて説明しています。OpenCL2.0実行可能モジュールは、NDRangeを任意の次元の異種サイズのワークグループに分割できます。 開発者がNDRangeサイズを完全に分割しないワークグループのサイズを指定すると、実行可能モジュールはNDRangeを分割して、指定されたサイズのワークグループをできるだけ多く作成し、残りのワークグループは異なるサイズになります。
これにより、開発者がlocal_sizeパラメーターのNULL値をclEnqueueNDRangeKernelに渡すと、OpenCLは任意のNDRangeサイズに対して任意のサイズのワークグループを使用できます。 一般に、アプリケーションロジックが特定のワークグループサイズを必要としない場合、 local_sizeパラメーターでNULL値を使用することは、カーネルを実行するための優先される方法のままです。
カーネルコード内で、組み込みのget_local_size()関数は、呼び出し元のワークグループの実際のサイズを返します。 カーネルがclEnqueueNDRangeKernelのlocal_sizeパラメーターに指定された正確なサイズを必要とする場合、 get_get_enqueued_local_size()組み込み関数はこれらの値を返します。
異種ワークグループの使用を有効にするには、OpenCL 2.0のこの機能と他の機能を含む-cl-std = CL2.0フラグを使用してカーネルをコンパイルする必要があります。 このフラグがないと、デバイスがOpenCL 2.0をサポートしている場合でも、コンパイラはOpenCL 1.2を使用します。 さらに、 -cl-uniform-work-group-sizeフラグを使用して、 -cl-std = CL2.0フラグ用にコンパイルされたカーネルの異種ワークグループを無効にすることができます。 これは、OpenCL 2.0に完全に移行するまで、レガシーカーネルコードに役立つことがあります。
OpenCL 2.0の異種ワークグループ機能により、OpenCLの使いやすさが向上し、一部のコアのパフォーマンスが向上します。 開発者は、完全に共有されていないNDRangeサイズを操作するためのシステムおよびカーネルコードを追加しなくなりました。 この機能を利用するために作成されたコードは、SIMDとメモリアクセスの均等化を活用できます。これらの利点は、ワークグループに適切なサイズを選択することによって提供されます。
カリキュラムコードは、上記の3x3ぼかしアルゴリズムを実装しています。 コードの最も興味深い部分は、main.cppファイルにあります。
コード
//1. . //2. OpenCL C OpenCL 1.2. // Get the box blur kernel compiled using OpenCL 1.2 (which is the // default compilation, even on an OpenCL 2.0 device). This allows // the code to show the pre-OpenCL 2.0 behavior. cl::Kernel kernel_1_2 = GetKernel(device, context); //3. OpenCL C OpenCL 2.0 ( OpenCL 2.0). // Get the box blur kernel compiled using OpenCL 2.0. OpenCL 2.0 // is required in order to use the non-uniform work-groups feature. kernel_2_0 = GetKernel(device, context, "-cl-std=CL2.0"); //4. , . // Set the size of the global NDRange, to be used in all NDRange cases. // Since this is a box blur, we use a global size that is two elements // smaller in each dimension. This creates a range which often doesn't // divide nicely by local work sizes we might commonly pick for running // kernels. cl::NDRange global_size = cl::NDRange(input.get_width() - 2, input.get_height() - 2); //5. , OpenCL 1.2, local_size NULL. // Blur the image with a NULL local range using the OpenCL 1.2 compiled // kernel. cout << "Compiled with OpenCL 1.2 and using a NULL local size:" << end1 << end1; output = RunBlurKernel(context, queue, kernel_1_2, global_size, cl::NullRange, input, true); //6. , OpenCL 1.2, local_size 16x16. // Blur the image with an even local range using the OpenCL 1.2 // compiled kernel. This won't work, even if we are running on an // OpenCL 2.0 implementation. The kernel has to be explicitly compiled // with OpenCL 2.0 compilation enabled in the compiler switches. try { cout << "Compiled with OpenCL 1.2 and using an even local size:" << end1 << end1; output = RunBlurKernel(context, queue, kernel_1_2, global_size, cl::NDRange(16, 16), input, true); cout << end1; output.Write(output_files[1]); } catch (...) { cout << "Trying to launch a non-uniform workgroup with a kernel " "compiled using" << end1 << "OpenCL 1.2 failed (as expected.)" << end1 << end1; } //7. , OpenCL 2.0, local_size NULL. // Blur the image with a NULL local range using the OpenCL 2.0 // compiled kernel. cout << "Compiled with OpenCL 2.0 and using a NULL local size:" << end1 << end1; output = RunBlurKernel(context, queue, kernel_2_0, global_size, cl::NullRange, input, true); //8. , OpenCL 2.0, local_size 16x16. // Blur the image with an even local range using the OpenCL 2.0 // compiled kernel. This will only work on an OpenCL 2.0 device // and compiler. cout << "Compiled with OpenCL 2.0 and using an even local size:" << end1 << end1; output = RunBlurKernel(context, queue, kernel_2_0, global_size, cl::NDRange(16, 16), input, true); //9. , . 2—5.
段落の各オプション。 5-8では、NDRangeの四隅のそれぞれでget_local_size ()およびget_get_enqueued_local_size()を呼び出した結果が画面に表示されます。 したがって、NDRangeがワーキンググループに分割される様子がわかります。 ぼかしアルゴリズムを実装するカーネルは、BoxBlur.clに保存されます。 非常に単純な実装が含まれていますが、ぼかしを適用する最も効果的な方法ではありません。
このチュートリアルをビルドして実行するには、次の要件を満たすPCが必要です。
- BroadwellというコードネームのIntel®Core™プロセッサシリーズ。
- Microsoft Windows * 8または8.1。
- Intel®SDK for OpenCL™アプリケーションバージョン2014 R2以降。
- Microsoft Visual Studio * 2012以降。
カリキュラムは、上記のセクションで説明した各NDRangeバリアントの入力ビットマップを読み取り、出力ビットマップを書き込むコンソールアプリケーションです。 このチュートリアルでは、いくつかのコマンドラインオプションをサポートしています。-h、-? (ヘルプテキストを表示して終了)、-i <入力プレフィックス>(入力ビットマップのプレフィックス)、-o <出力プレフィックス>(出力ビットマップのプレフィックス)。
提供された図面のトレーニングプログラムを開始すると、結果は次のようになります。
非表示のテキスト
Input file: input.bmp Output files: output_0.bmp, output_1.bmp, output_2.bmp, output_3.bmp Device: Intel(R) HD Graphics 5500 Vendor: Intel(R) Corporation Compiled with OpenCL 1.2 and using a NULL local size: Work Item get_global_id() get_local_size() get_enqueued_local_size() ------------------------------------------------------------------------- Top left (0,0) (1,239) undefined Top right (637,0) (1,239) undefined Bottom left (0,477) (1,239) undefined Bottom right (637,477) (1,239) undefined Compiled with OpenCL 1.2 and using an even local size: Trying to launch a non-uniform workgroup with a kernel compiled using OpenCL 1.2 failed (as expected.) Compiled with OpenCL 2.0 and using a NULL local size: Work Item get_global_id() get_local_size() get_enqueued_local_size() Top left (0,0) (1,239) (1,239) Top right (637, 0) (1,239) (1,239) Bottom left (0,477) (1,239) (1,239) Bottom right (637,477) (1,239) (1,239) Compiled with OpenCL 2.0 and using an even local size: Work Item get_global_id() get_local_size() get_enqueued_local_size() Top left (0,0) (16,16) (16,16) Top right (637,0) (14,16) (16,16) Bottom left (0,477) (16,14) (16,16) Bottom right (637,477) (14,14) (16,16) Done!
入力画像のサイズは640x480であるため、それぞれの場合のNDRangeのサイズは638x478です。 上記の結果は、 local_sizeパラメーターのNULL値を使用してOpenCL 1.2カーネルを起動すると、各ワークグループ( 1、239)に奇数サイズの使用が強制されることを示しています。 2のべき乗ではないワークグループサイズは、一部のコアで非常に遅く動作する場合があります。 SIMDパイプラインはアイドル状態である可能性があり、同期メモリアクセスが損なわれる可能性があります。
指定されたワークグループサイズ(16x16)でOpenCL 1.2カーネルを実行すると、648も478も16で割り切れないため、エラーがスローされます。
NULL値のlocal_sizeパラメーターでOpenCL 2.0カーネルを起動すると、OpenCL実行可能ファイルがNDRangeを任意のサイズのワークグループに分割できます。 結果を上に示します。実行可能モジュールは、OpenCL 1.2カーネルの場合と同じ方法で、ワークグループの均一なサイズを引き続き使用していることがわかります。
特定のワークグループサイズ(16x16)でOpenCL 2.0カーネルを実行すると、NDRangeサイズが異種のワークグループに分割されます。 左上のワーキンググループは16x16、右上は14x16、左下は16x14、右下は14x14です。 ほとんどの場合、ワークグループのサイズは16x16であるため、このコアはSIMDパイプラインを非常に効率的に使用し、メモリアクセスは非常に高速になります。
IDZ Webサイトの記事のフルバージョン:
英語のオリジナル記事: