分析の分野で作業し、さまざまなBIツールを監視すると、遅かれ早かれ、Power Pivot Excelアドインのレビューや言及に出くわします。 私の場合、Microsoft Data Dayカンファレンスで彼に会いました。
プレゼンテーションの後、ツールはあまり印象を残しませんでした:はい、無料です(Officeライセンスの下)、はい-異なるソース(データベース、csv、xlsなど)からデータを受信するという点でいくつかのETL機能があり、これらのソースのソースを結合しますExcelで100万行を超える桁にレコードをフィードします。 要するに、私は見忘れていた。
そして、データ内の特定の現象を識別することが必要になったときを思い出さなければなりませんでした
この記事の執筆は、RuNetの特定の作業方法に関する詳細情報、星に関する詳細情報があまりないという事実に促されたため、このツールを検討してこのレビューを書くことにしました。
実際、問題のステートメント(匿名の例を使用)は次のとおりです。
csvファイルのソースデータ:

請求書行に詳述されたアウトレットがあり、同じ名前のポイントは異なる都市にある場合にのみ異なる住所を持つことができますが、元のデータ配列には同じ都市の異なる住所を持つポイントがありますポイントの名前が同じであるという事実にもかかわらず(アウトレットの名前は一意です。つまり、ネットワークユニットまたは独立したポイントです)。 集約された形式の特別な場合として:
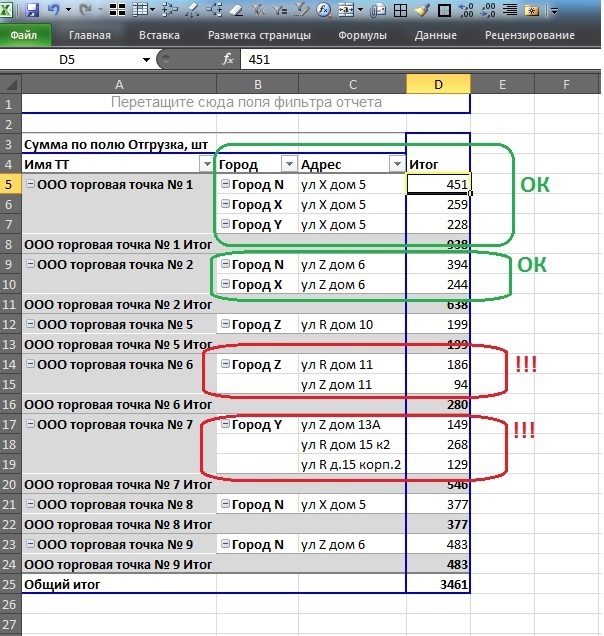
次の状況は、通常のオフィスツールを使用したデータの検索とクリーニングを妨げます。
•データを請求書行にドリルダウンする
•数百万行のエントリ数
•SQLツールキットの欠如(例:アクセス-含まれていません)
もちろん、無料のDBMS(少なくともデスクトップバージョン、少なくともサーバーバージョン)に入力できますが、このためには、まず管理者権限が必要です。次に、Power Pivotに関する記事ではありません。
タスク :原子レコードごとに、アウトレットの名前ごとに同じ都市内の一意の数の住所を計算する追加の計算フィールドが必要です。 このフィールドは、複数の住所がある市内のアウトレットのすべての名前をすばやく見つけるために必要です。
DAXの知識はまだ初期段階にあるという前提で、繰り返し解決して話し合うのが最も便利だと思います。
したがって、私は今のタスクから脱却し、いくつかの基本的な側面を検討することを提案します。
ステップ1.計算列と計算メジャーの違いは何ですか?
組み込みDAX数式を使用して、VAT配送フィールドからVATを強調表示する計算列の例を次に示します。
=ROUND([ ]*POWER(1,18;-1)*0,18;2)
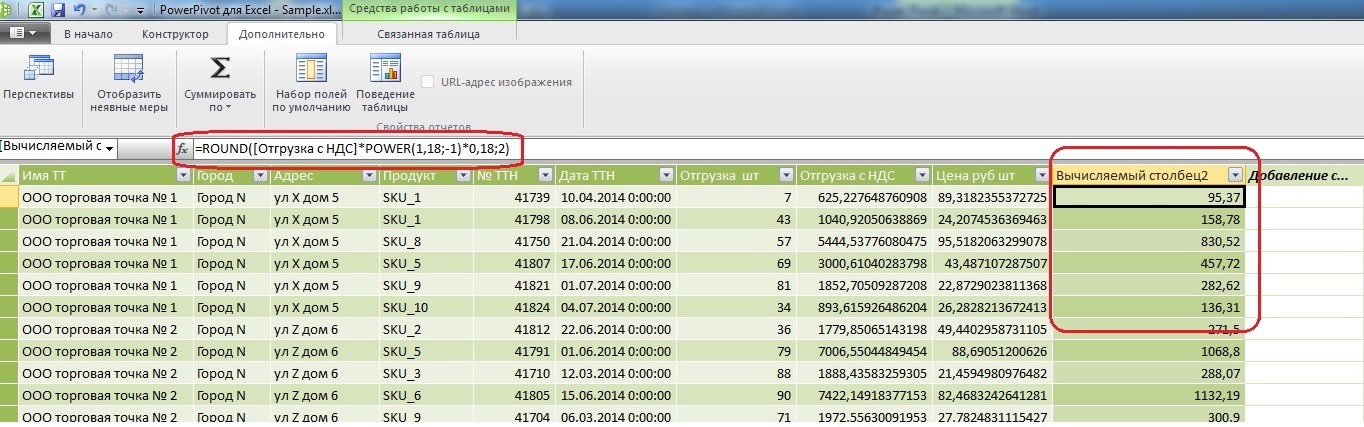
例からわかるように、計算列(VATと呼びましょう)は、各アトミックレコードを水平に処理します。
次に、VATなしで単価の計算フィールドを追加します。
=ROUND([ ]*POWER(1,18;-1)/[ ];2)

比較のために、平均単価の計算を適度に追加します。
: =ROUND(AVERAGE([_ ]);2)
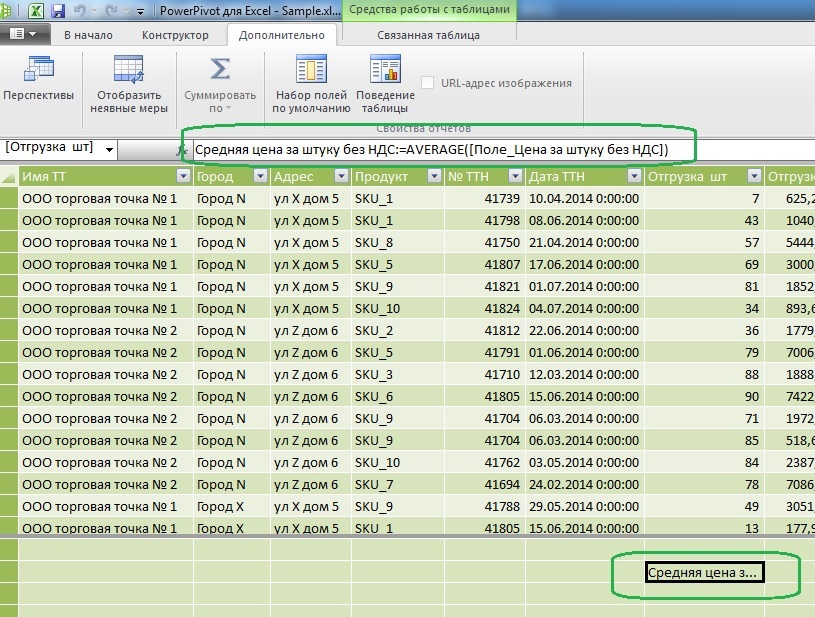
式からわかるように、メジャーはソース列で垂直に機能するため、セットで機能する何らかの種類の関数(合計、平均、分散など)が常に含まれている必要があります
Excelピボットテーブルに戻ると、次のようになります。
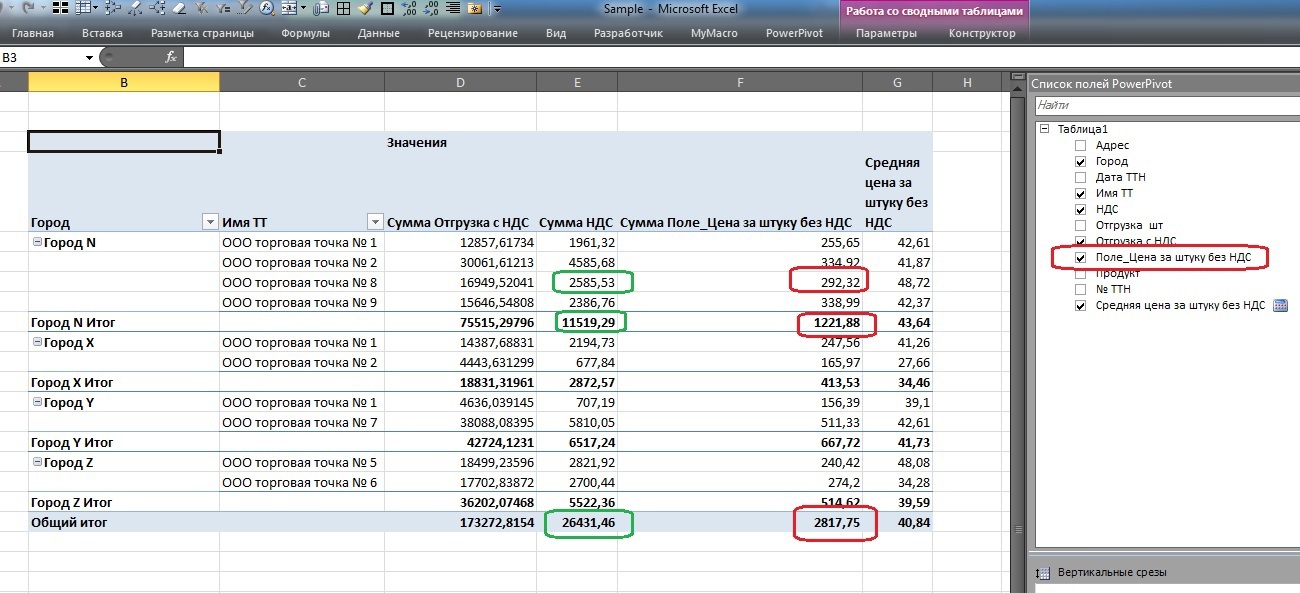
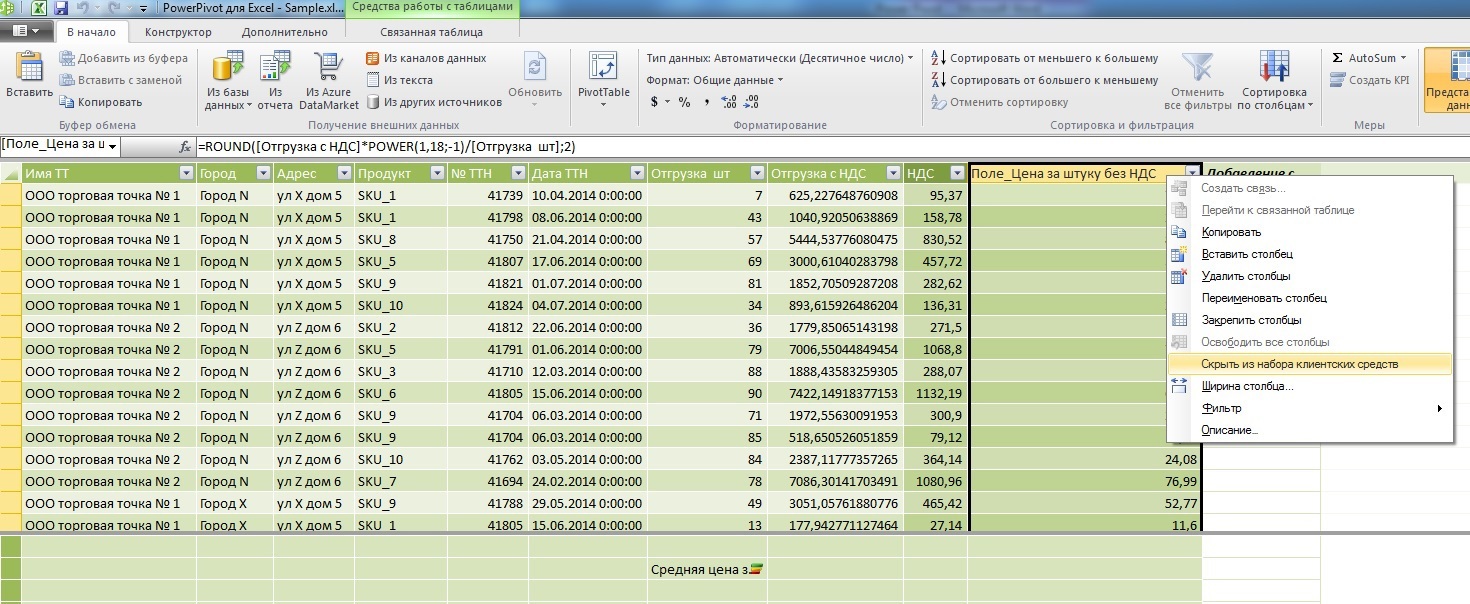
各データレベルで計算されたVATフィールド(販売地点、都市、または表による合計)で計算されたVATフィールドが金額を示している場合、これは基本的に正しい場合、計算フィールド「VATなしの単価」の価格の合計(赤いストローク)質問を提起します。
しかし、計算された測定「VATなしのユニットあたりの平均価格」には、この分析キューブのフレームワーク内での生存権があります。
このことから、計算フィールド「VATなしの単価」はメジャー「VATなしの平均単価」を計算するための補助ツールであり、ユーザーをこのフィールドと混同しないように、クライアントの資金のリストから非表示にして平均価格メジャーを残します。
メジャーと列のもう1つの違いは、視覚化を追加できることです。
たとえば、分散のルートを算術平均で除算することにより、35%のターゲット境界線を持つ価格分散度のKPIを構築します。
_:=STDEV.P([_ ])/AVERAGE([_ ])

その結果、Excelにそのようなテーブルが表示されます(ところで、計算された補助価格フィールドは、右側の使用可能なフィールドのリストに含まれなくなりました)。
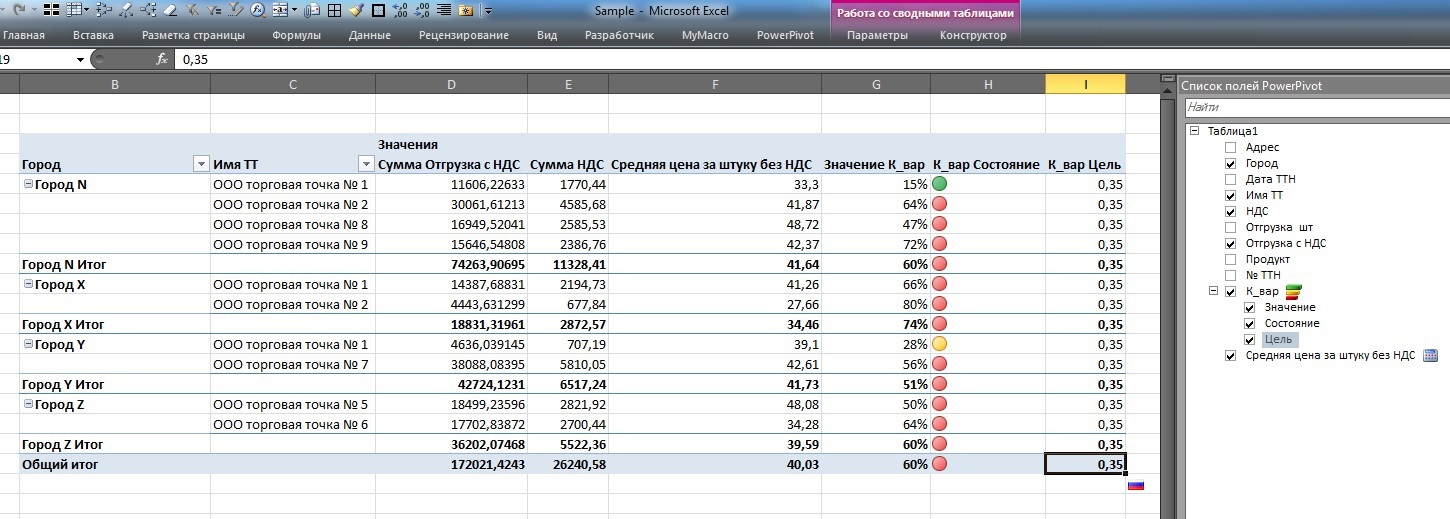
80%係数をダブルクリックすると、価格が実際に平均を上回るソーセージであることがわかります。

15%よりも強い:

そのため、このステップでは、PowerPivot内のメジャーとフィールドの主な違いを調べました。
ステップ2.複雑化:総売上高の各レコードのシェアを計算します。
MS SQL ServerとDAXのウィンドウ関数のアプローチを比較する最初の例を次に示します。
ピボットテーブルのフレームワークでは、キーボードに触れずにマウスで2回クリックするだけで文字通りこれが実行されることは明らかですが、理解のために、式を使用してPowerPivotでこれを直接試します。
sqlでは、次のように記述します(WordはSQL Serverの構文をチェックしないので、欠陥を見つけないでください)。
Begin Select 't1. ', 't1.', 't1.', 't1.', 't1.№ ', 't1. ', 't1., ', 't1. ', 't1., '/sum('t1., ') over () as share from Table as t1 order by 't1., '/sum('t1., ') desc
ご覧のとおり、データセットのすべてのレコードを介してウィンドウが開きます。PowerPivotで同様のことを試してみましょう。
=[ ]/CALCULATE(SUM([ ]);ALL('1'))
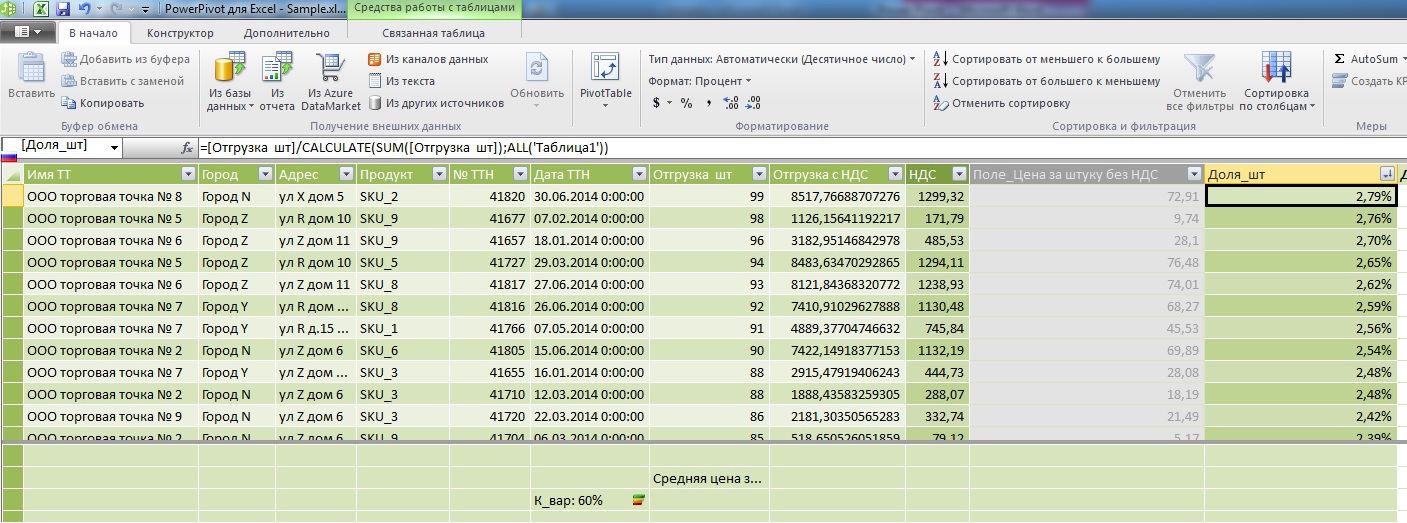
分母に焦点を当てます:計算フィールドとメジャーの主な違いは、フィールド内の数式が水平方向(単一のレコード内)でカウントされ、メジャーが垂直方向(単一の属性内)でカウントされることです。 ここでは、CALCULATEメソッドを使用して、フィールドプロパティを横断し、プロパティを測定することができました。 また、SQLのウィンドウの幅をOver()で調整した場合、ここではAll()で調整しました。
次に、このスキルを使用して、データで有用なことを行います。たとえば、平均の周りの価格分散のインジケーターが広範囲に変化したことを思い出して、3シグマルールを通じて価格の統計的外れ値を分離しようとします。
SQLのウィンドウ関数は次のようになります。
Select 't1. ', 't1.', 't1.', 't1.', 't1.№ ', 't1. ', 't1., ', 't1. ', 't1. ', CASE WHEN ABS('t1. ' - AVG('t1. ') OVER() ) > 3 * STDEV('t1. ') OVER() THEN 1 ELSE 0 END as Outlier from Table as t1 Go
DAXでも同じことが言えます。
=if(ABS([_ ]-CALCULATE(AVERAGE([_ ]);ALL('1')))>(3*CALCULATE(STDEV.P([_ ]);all('1')));1;0)
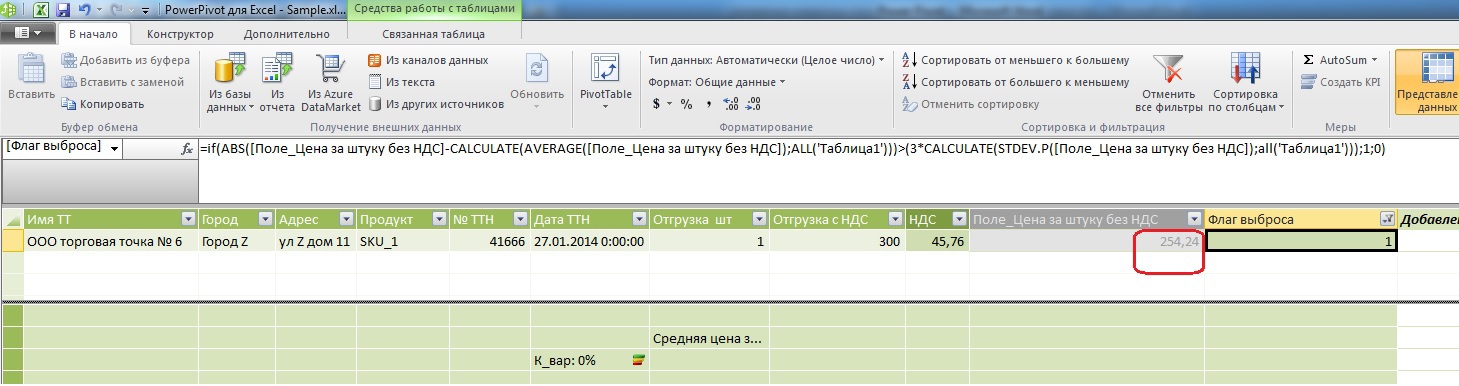
ご覧のとおり、価格はやや高く、算術平均は40.03ルーブルです。
ステップ3.ウィンドウを狭くします。
ここで、このレコードが属する都市内の各レコードの計算フィールドでレコードの総数を計算してみましょう。
MS SQL Serverでは、ウィンドウ関数は次のようになります。
Select 't1. ', 't1.', 't1.', 't1.', 't1.№ ', 't1. ', 't1., ', 't1. ', 't1. ', count('t1.*) OVER( partition by 't1.' ) as cnt from Table as t1 Go
DAXの場合:
=CALCULATE(COUNTROWS('1');ALLEXCEPT('1';'1'[]))
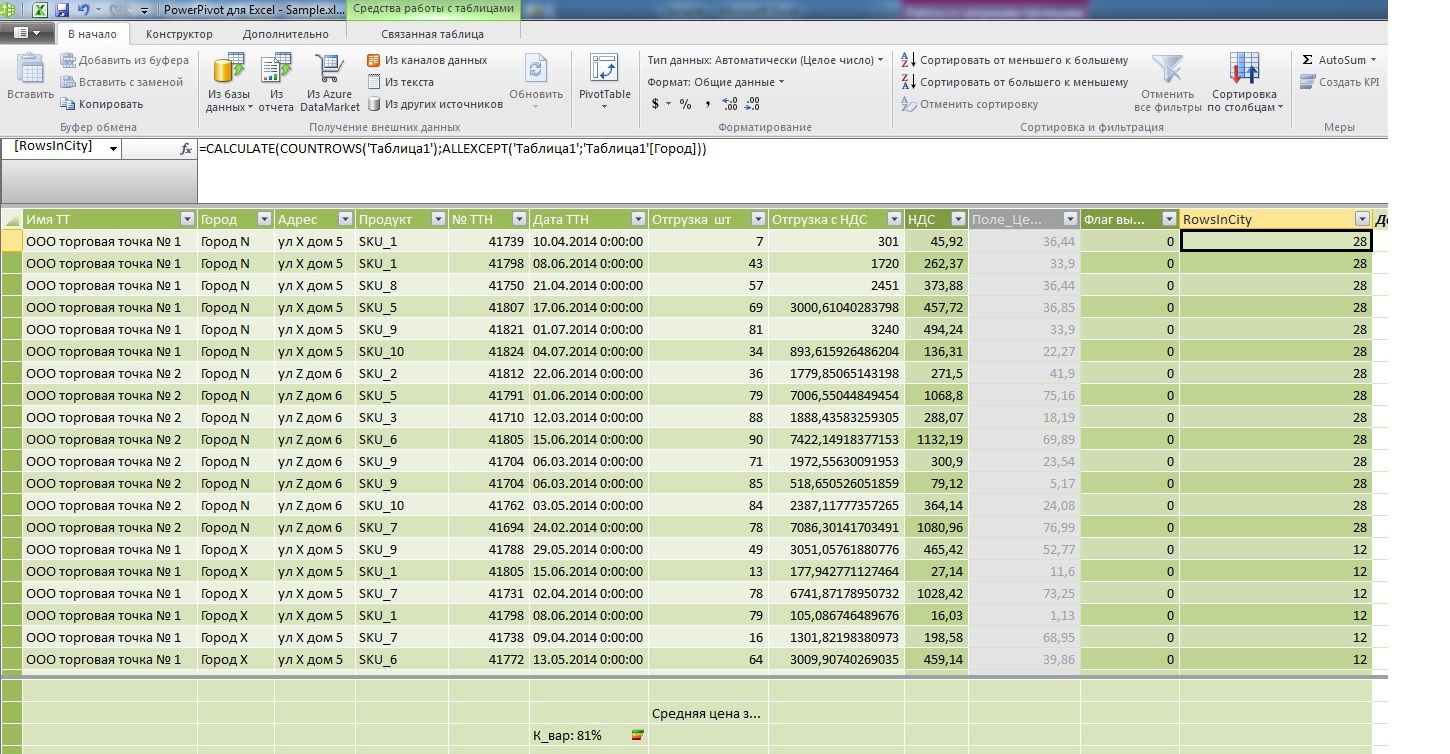
テーブル内のデータの表示の違いに注意して、メジャー領域のアドレスを意図的に投げてその数を計算し、アウトレットの名前の後に行ヘッダーに表示された新しいフィールドと比較します。
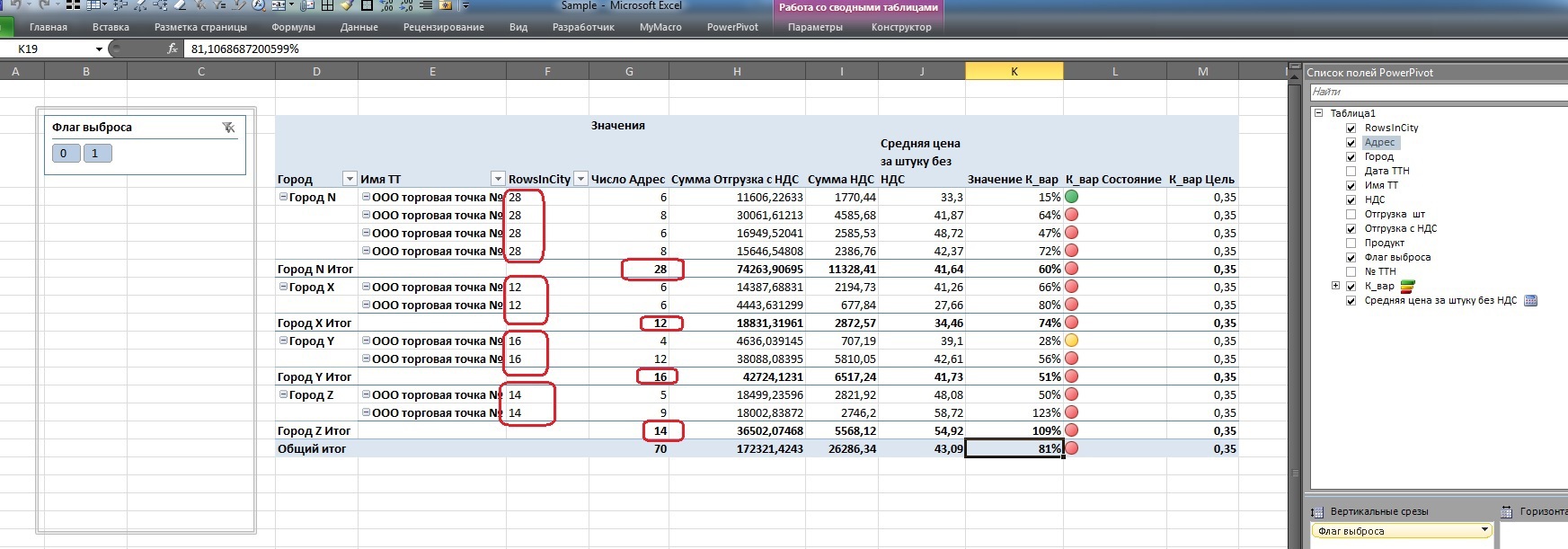
違いは明らかです:住所の通常の計算が都市の各ポイントに対して行われ、「City」集計の中間結果のみを表示する場合、ウィンドウ関数を使用すると、各アトミックレコードに集計の値を割り当てたり、計算フィールドの中間計算でそれを使用したりできます(上記のように)。
元のタスクに戻る
したがって、問題の初期定式化を思い出させてください。各アトミックレコードに対して、アウトレットの名前ごとに同じ都市内の一意の数の住所をカウントする追加の計算フィールドが必要です。 データセットが請求書の行に詳細であることを忘れないでください。したがって、ウィンドウ内の住所をカウントする前にそれらをグループ化する必要があります。
SQL Serverクエリ:
With a1 as (Select 't1. ', 't1.', 't1.', 't1.', 't1.№ ', 't1. ', 't1., ', 't1. ', 't1. ', count(Distinct 't1.') OVER( partition by 't1.', 't1. ' ) as adrcnt from Table as t1) Select * from a1 where adrcnt>1
現在、DAXでこれを行うことを妨げるものはありません。
=CALCULATE(DISTINCTCOUNT('1'[]);ALLEXCEPT('1';'1'[];'1'[ ]))
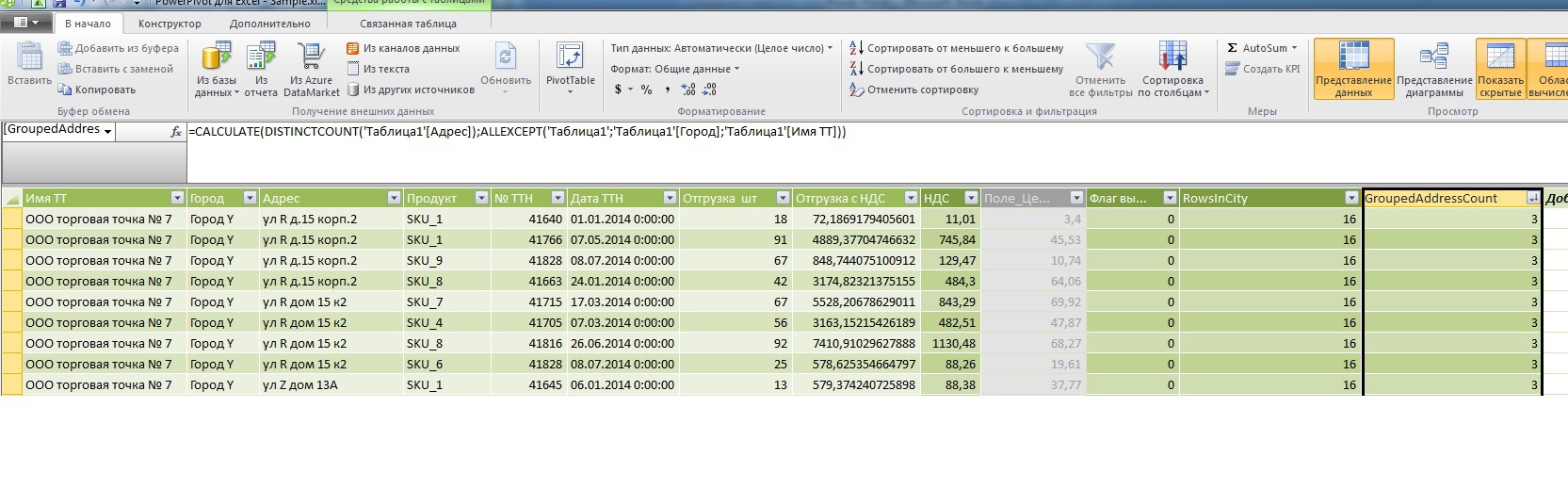
その結果、複数の住所が同じ都市の同じ地点にある疑わしいエントリを選択できるようになりました。

もちろん、(他の式をひと目見た)学習の過程で、PowerPivotのDAXがこのトピックで示されているよりもはるかに強力であることが明らかになりますが、確かに広大さを把握することはできません。
面白かったと思います。
記事の続きはこちら。