多くの場合、初心者に自動テストについて話すと、同じ質問がポップアップ表示されます。「テスト自体をテストするのは誰ですか? テスト用のテストを作成し、次にテスト用のテストを作成する必要があります...」誰もが再帰を愛し、仲間にもっと伝えるのが大好きです。
奇妙なことに、「テスターをテストしているのは誰ですか?」という質問に出くわすことはありません。実際、同じ問題は側面図です。
しかし、実際には、なぜテストをテストする必要がないのですか? (およびテスター)
仮想の再帰を停止するには、プロジェクトの外部のエンティティとしてではなく、プロジェクトの一部としてテストを実行する必要があります。
テストは複製の良い例であり、システムの重要な部分のいくつかのコピーを実装することにより信頼性を高める方法です。 ニュアンスは、私たちの場合、複製は結果のシステムの動作ではなく、その正式なモデルの精度によって制御されるということです。
次の図は、アイデアを明確にする必要があります。
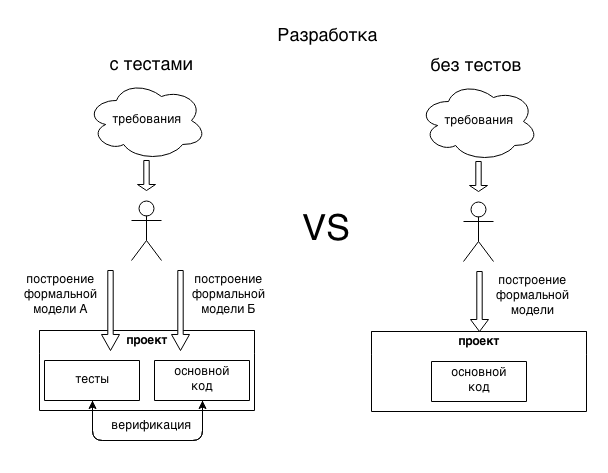
コードを書くとき(テスト、機能、どちらでも構いません)、現実世界の一部の正式なモデルを構築します。 もちろん、このモデルは、宇宙の物事の実際の状態(単純化による)と、私たちが取得したい理想的な結果(エラーと最終的な目標を理解していないため)の両方とも異なります。
同時に、テストと機能を作成するとき、対象領域を異なる角度から見ると、同じ対象領域の2つの異なるモデルが表示され、誇張されます。
- 機能コードは、内部メカニズムの観点からデバイスモデルを記述します。
- テストコードは、外部観測者の観点から、デバイスのモデルを記述します。
したがって、解決すべき問題の2つのモデルがプロジェクトに表示され、異なる原則に従って作成されます。 (テストの実行を通じて)それらの動作を比較すると、モデル内の不一致を特定し、それらを排除できます。
したがって、テストはコードをチェックし、コードはテストをチェックします。 一緒に、問題のより信頼できるモデルが取得されます。
庭の石TDD
この機会を利用して、古典的なTDDの庭に石を投げます。彼の信奉者は、モデルの切り替えの高速サイクルを説きます。テストを書き、機能を書き、繰り返しました。
頻繁にコンテキストが変更されるため、各モデルの不可欠な構造を頭の中に保持することは困難です(さらに、よく考え直してください)。
したがって、私は長期の開発を好む:
順序(最初に書くもの:テストまたは機能)は重要ではありません-主なことは、最終的に2つのモデルが実装されることです。 私は通常、よりシンプルなものから始めます。
頻繁にコンテキストが変更されるため、各モデルの不可欠な構造を頭の中に保持することは困難です(さらに、よく考え直してください)。
したがって、私は長期の開発を好む:
- 1つのモデル(任意)のパーツの設計。
- 設計の実装;
- 2番目のモデルの同様の部分を設計します。
- 設計の実装;
順序(最初に書くもの:テストまたは機能)は重要ではありません-主なことは、最終的に2つのモデルが実装されることです。 私は通常、よりシンプルなものから始めます。
実際、サブジェクトエリアの2つのモデルではなく、3つのモデルを区別できます。
- 機能コードのモデル。
- テストコードのモデル。
- 開発者の頭の中のモデル。
3つのモデルはすべて異なる原則に基づいて構築されています。つまり、特定のモデルがエラーに属しているかどうかを判断するためにこれを使用できます:2つのモデルがAと3番目のBを言う場合、3番目のモデルが間違っていてエラーが含まれていると仮定するのは論理的です。
記事の作業中に、単一のテストが損なわれたわけではありません。 ご清聴ありがとうございました。