映画、「借り、待望の、今週リリース模倣ゲーム 」(模倣ゲーム)アラン・チューリングその誕生Mathematicaの誕生日の22日目と一致する(100周年の物語告げる-詳細については、スティーブン・ウルフラムによってポストを参照。 お誕生日おめでとう、アランチューリング )。 映画の中心テーマはチューリング機械です。 興味深いことに、2007年にWolfram Researchは2.3チューリングマシンの汎用性を証明する賞を発表しました。
もちろん、 プロモーションビデオ 、彼は声を模倣したベネディクト・カンバーバッチの、および他の有名な俳優の動作が非常に好きでした。 しかし、 機械学習分野のMathematica機能が彼の声を認識できるかどうか、または彼もコンピュータを「だます」ことができるかどうかを知りたかった。
個人的には、このビデオを見て笑うのは仕方ありませんが、これらのパロディを心を開いて見たいです。
だから、私は自分に尋ねた:彼は本当に他の俳優の声をよくまねているのか、それとも自分自身を含む私たち全員が彼のペルソナに単に魅了されているのか?
たぶん私の心は私を欺いているのでしょうか? 元の声のサンプル全体を取得した場合、パロディは実際に見分けがつかないでしょうか?
この質問の答えを得るには、10年前に通りを歩いて、ジェームズボンド、ラディアンス、バットマン、カンバーバッチのエミュレートし、300人にインタビューしてから意見を分析する必要がありました。
今日の世界では、 Mathematicaのようなシステムを使用してこれらの質問に答えることができます!
Wolfram言語には、オーディオフラグメントのトレーニングサンプルに基づいて分類子を作成できるビルトイン機能があります。これにより、最終的にCumberbatchがコンピューターを「だます」ことができるかどうかを確認できます。 そのため、音声フラグメントのかなり「まともな」データベースを作成するタスクを自分で設定し、これに加えて、カンバーバッチの各パロディーに対応するフラグメントを選択し、最後に残りをMathematicaで処理できるようにしました。
Mathematicaが分析に使用する音声フラグメントの各データベースへのパスを構築します。

次に、すべての元のボイスをインポートします。
分類子は、トレーニングサンプルと共に提供されたClassify関数を使用して作成されました。 生産性を向上させるために、分類子( ClassifierFunction )を作成したら、cfActorWDX.wdxファイルから即座にシステムにロードできます(コードのコメント部分には、実際には分類子を作成する構造があります)。

私のデータベースには、ベネディクトの元の声のサンプル、ベネディクトが模倣する俳優の声、そして最後にベネディクトのパロディの断片が含まれています。 トレーニングサンプルの作成元は、 Alan Rickman 、 Christopher Walken 、 Jack Nicholson 、 John Malkovich 、 Michael Kane 、 Owen Wilson 、 Sean Connery 、 Tom Hiddleston 、およびBenedict Cumberbatchです。 合計560個のフラグメントを使用しましたが、もちろん、使用するデータが多いほど、結果の信頼性は高くなります。 同時に、サンプルは可能な限り「クリーン」である必要があります(笑い声、音楽、他の人の会話などはなし)
また、それらは正確に同じ長さ(3.00秒)でなければなりません。 全員が同じ長さを持っていることを確認するために、Wolfram言語でこの構造を使用できます:

一部のファイルはシングルチャネルではなかったため、サンプルの生成およびエクスポートの段階でも結果を最適化するために、この機能を削除する必要がありました。

このコードの作成に協力してくれたMartin HadleyとJon McLoonに感謝します。
ドラムロール...結果について話す時間!
私は機械学習は、その声の音特定のフラグメントで、したがって、あなたが声の模倣を認識することを可能にするかを決定するために実際にあるように、私はMathematicaのすべてに「いじり」されたので...今私はすべての私の心を破るだろう、と私は間違いなくこれを行うにはしたくないだろうと思います実際に誰が話したかを判断します。
以下の結果は、ベネディクトの「模倣」の各断片において、他のアクターの声にどのアクターがどのような確率で「オーサーシップ」を与えたかを示しています:

ほとんどの場合、俳優の一人がベネディクト・カンバーバッチまたはアラン・リックマン以外を言った可能性は無視できます。
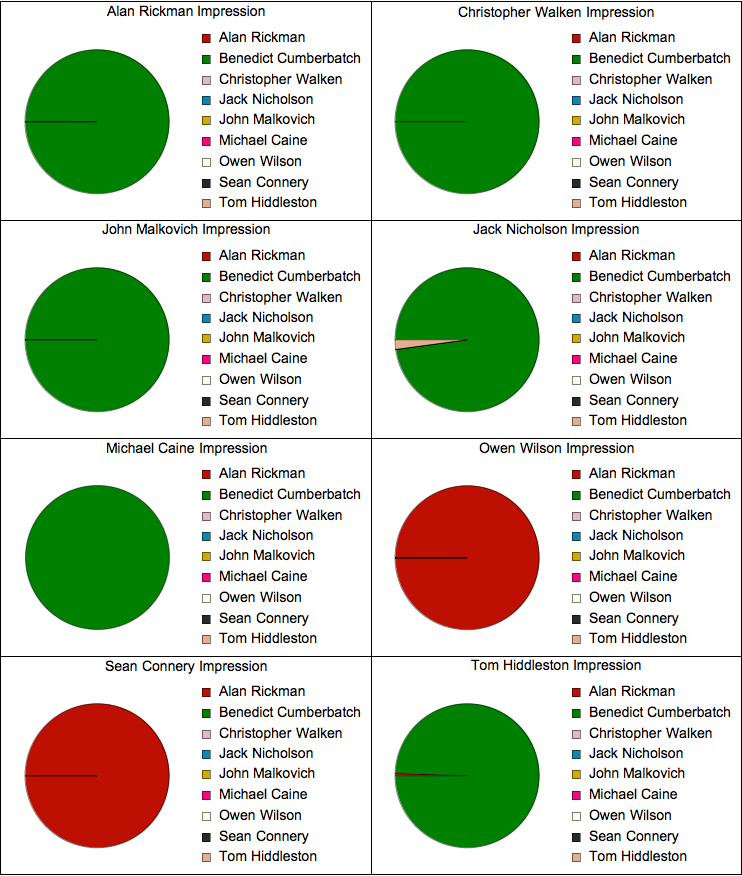
リックマン、コネリー、およびウィルソンは、多くのポーズで話すのがかなり遅い方法であることに注意する価値があるかもしれません(これは使用したフラグメントで非常に顕著です)。

今こそ、ベネディクトに対する「grみ」を抱くことなく、この小さなショックを克服する時です。 彼はまだ非常に魅力的です。
全体として、私は彼の才能に満足しており、映画で彼の試合を見るのを楽しみにしています。これについては、私の短い投稿の冒頭で話しました。
ロシア語でWolfram言語(Mathematica)を学習するためのリソース: http : //habrahabr.ru/post/244451