データマイニングハブを開始しました。データマイニングハブとは何か、なぜ役立つのかを説明したいと思います。
データマイニングハブ(DMH)は、データマイニングと機械学習のためのアルゴリズムの開発に対する反復的なアプローチであり、大量のデータの分析と抽出からのビジネスツールでもあります。このデータは有用で必要な情報です。
DMHとkaggleやalgomostなどの同様のリソースの違い:
- タスクは反復に分割されます。
- アルゴリズムコードは作成者に残り、顧客はレンタルのためだけにそれを受け取ります。
- DMHはお金を管理、計算、評価、操作します。
- 参加には、資格の確認と確認は必要ありません。
DMHには2つの側面があります。 最初は、タスクを説明する顧客であり、2番目はこの問題を解決しようとしている科学者です。
DMHの科学者は、興味深い問題の解決に参加する機会を提供し、他の参加者と競争し、もちろん、アルゴリズムが顧客によって選択された場合に報酬を受け取ります。 この反復で彼が選択されなかった場合、次の時点でいつでも選択できます。 元のデータが変更されていない場合、DMHは最後の反復の結果を新しい反復に自動的に転送します。 ただし、アルゴリズムを改善し、次の反復で改善されたアルゴリズムのために報酬を受け取る機会もあります。
顧客にとって、DMHは多数の科学者との単一の統合ポイントであり、同じデータに対して異なるアルゴリズムを使用する簡単な方法です。
簡単に説明すると、DMHの原理は次のように説明できます。
- 顧客はタスクを作成し、説明を与え、各反復の概算予算、期間、および決定期間を決定します。
- 顧客はデータをアップロードし、科学者はそれを使用して作業します。
- 顧客はタスクを確認した後、科学者がデータを利用できるようになります。
- 科学者はデータに基づいて独自のアルゴリズムを作成し、DMHにアップロードして、アルゴリズムの使用コストを示します。
- 顧客が好きなアルゴリズムを選択すると、科学者への支払いが転送されます。
誰でもリンクwww.datamininghub.com/invite/meをクリックして、DMHにメールを入力するだけで招待することができます。
科学者がタスクの解決に参加するために必要なことを考慮してください。 原則として、すべてが非常に簡単です。 彼は、タスクを選択し、そのアルゴリズムを作成し、ソースデータでテストする必要があります。 満足のいく結果が得られたら、アルゴリズムを使用するコストをすでに指定できます。
もっと詳しく考えてみましょう
datamininghub.comでの認証後、解決する必要があるすべてのタスクがリストされたページが開きます。 お気に入りのタスクを選択し、データセットセクションでソースデータをダウンロードする必要があります
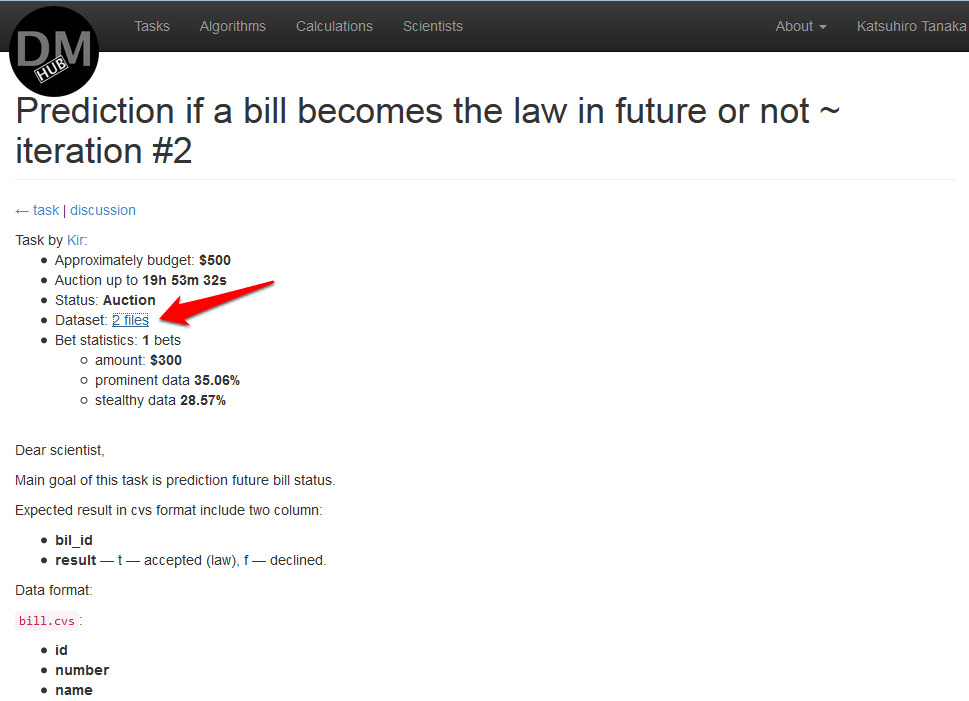
次に、開発ツールを使用してアルゴリズムを開発する必要があります。 主なことは、アルゴリズムがjarファイル(または複数)であり、hadoopでジョブとして実行できることです。
Scalaアルゴリズムの簡単な例は、 github.com / datamininghub / example- algorithmで入手できます。
www.datamininghub.com/task/1または同じScalaにある既存の問題を解決する実際の例は、 github.com / datamininghub / example-bill-status-predictionにあります。
アルゴリズムをロードするには、次のものが必要です。
- DMHに移動します。
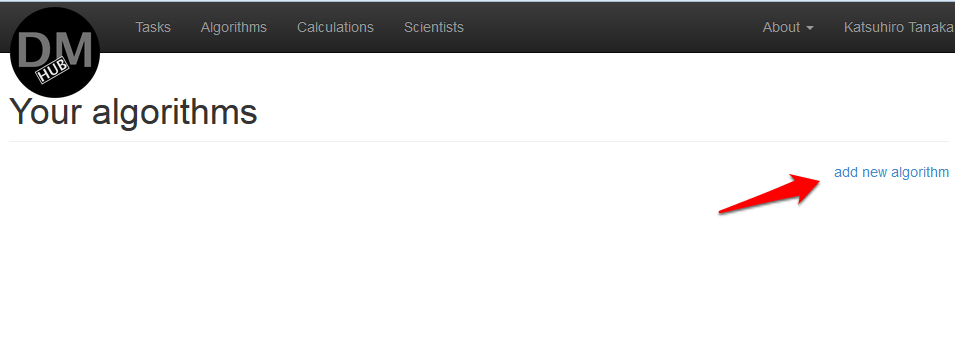
- メニューで[ アルゴリズム ]を選択すると 、このユーザー用に作成されたすべてのアルゴリズムが一覧表示されるページが開きます。
- [ 新しいアルゴリズムを追加]をクリックします
- AWSアカウントが以前にユーザープロファイルにリンクされていない場合、この段階でこれを行うように求められます。
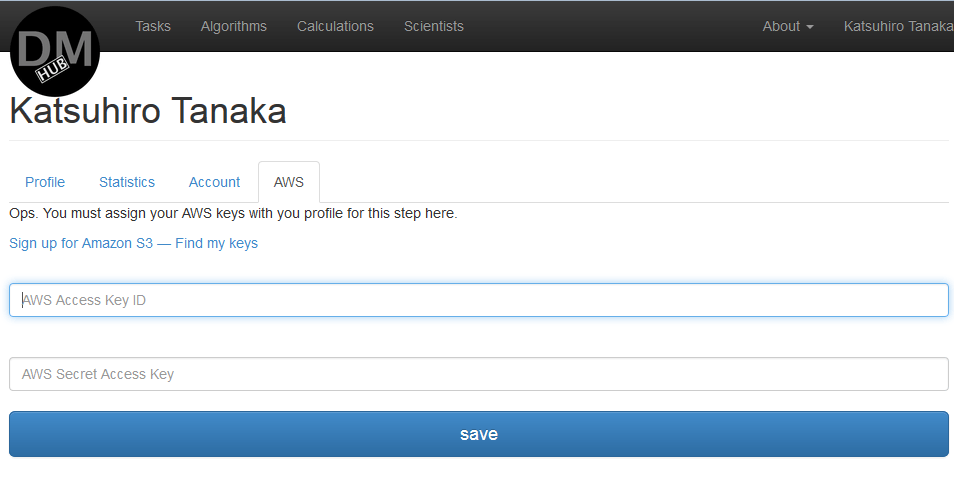
AWSアカウントがない場合は、登録する必要があります。
リンクhttp://aws.amazon.com/free/に従うことにより、新しいアカウントを登録し、1年間無料の制限を使用することができます。
その後、リンクAmazon S3にサインアップする-私のキーを見つけて 、DMHでさらに入力する必要があるキーを作成する必要があります。
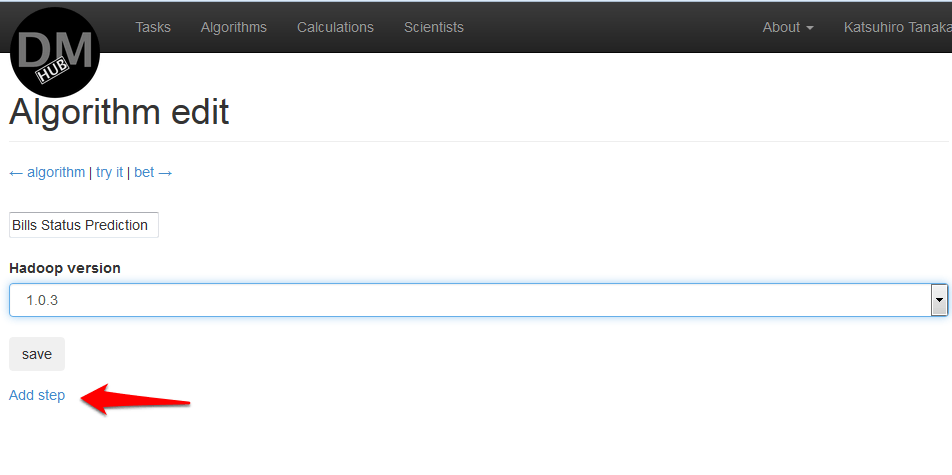
- AWSアカウントがリンクされると、 アルゴリズムの詳細ページが表示され、 Hadoop 1.0.3のDataMiningHubアルゴリズムNのデフォルト名と[ 編集 ]をクリックする必要がある場所が表示されます。

- 表示されるアルゴリズム編集ページで、アルゴリズムの名前を別の名前に変更したり、使用するHadoopのバージョンを変更したりできます。 次に、 Add stepをクリックして、アルゴリズムコードを含むjarファイルを追加するステップを追加し、このファイルを起動する引数を決定する必要があります。
- 表示される[ ファイルの追加]ページで、ダウンロードするjarファイルを選択して[ アップロード ]ボタンをクリックするか、このファイルへのS3リンクを指定します。

たとえば、bill-status-prediction.jarというファイル
注:ファイルのダウンロードには時間がかかる場合があります!
- 次に、指定されたjarファイルを起動するステップアルゴリズム編集ページで引数を設定し、[ 保存 ]ボタンをクリックする必要があります。

たとえば、次の引数が使用されます。--o {output} --events {events} --bill_deputy {bill_deputy} -f
- 引数を設定すると、 アルゴリズム編集ページが再び表示されますが、すでに入力されたステップに関する情報が表示されます。 必要に応じて、「 ステップの追加」をクリックしてステップ6から8を繰り返すことにより、他のjarファイルをダウンロードできます。
- 次に、[ アルゴリズムの詳細]ページで、ナビゲーションパネルの[ 賭け ]をクリックして、アルゴリズムの使用コストを決定し、計算を実行する必要があります。
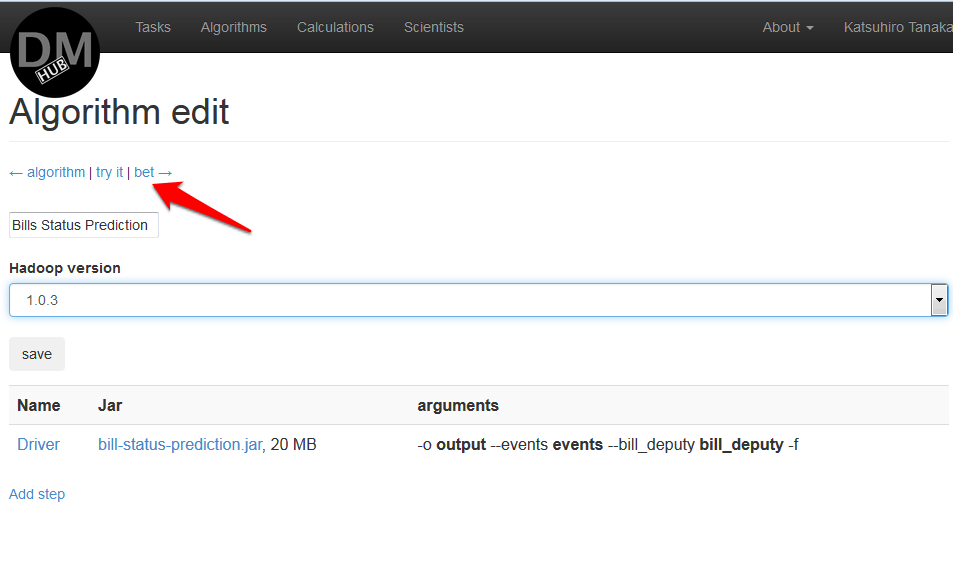
- [ アルゴリズムのベット]ページで、アルゴリズムを使用するタスクを選択する必要があります。
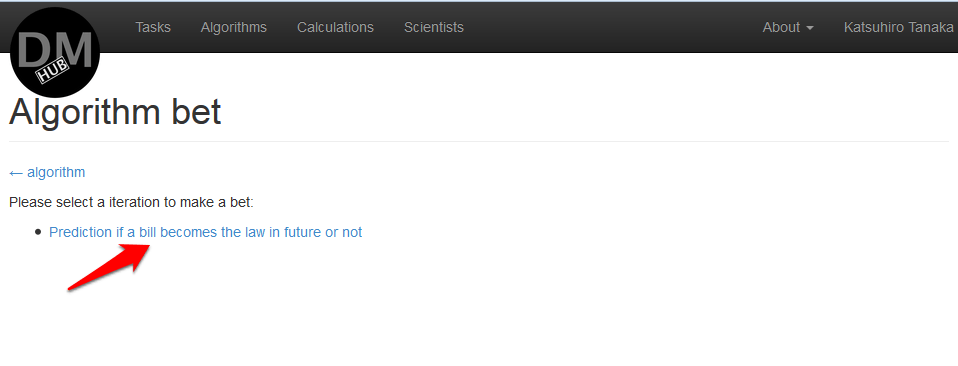
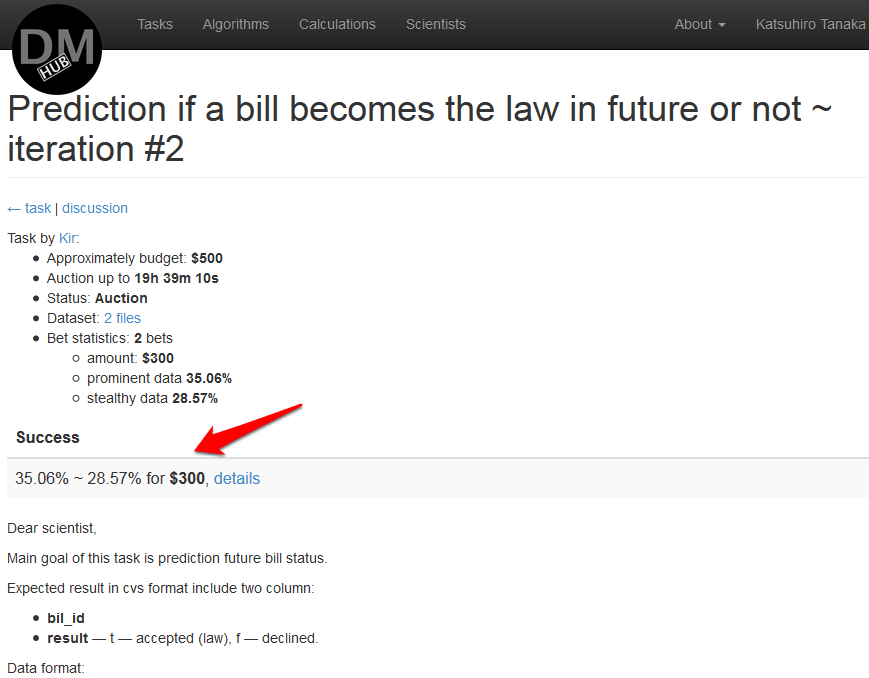
この例では、利用可能な反復は1つだけで、法案が将来法になるかどうかの予測です。
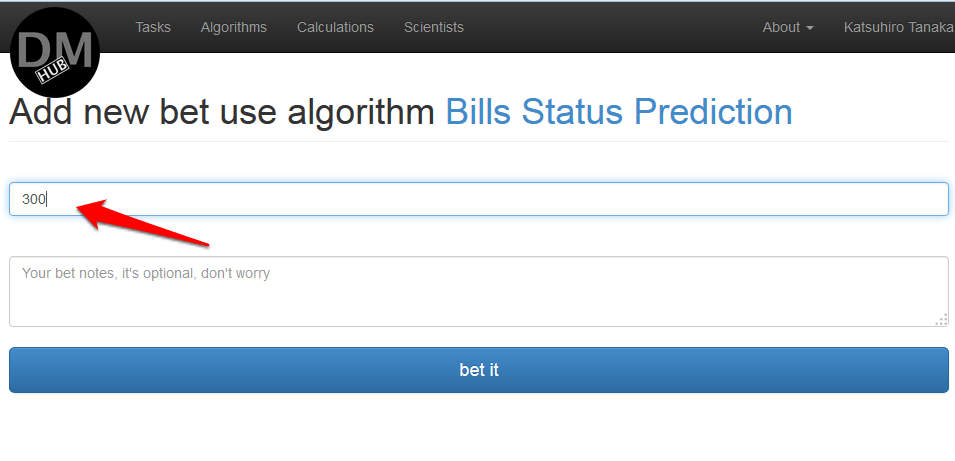
- 表示される[ 新しいベットを使用するアルゴリズムを追加]%algorithm_name%ページで、アルゴリズムを使用するコストを決定し、[ ベットする ]ボタンをクリックする必要があります。
- 表示される[ 計算の編集]ページの[ マッピング]セクションで、各引数名の前の[割り当て]をクリックし、必要なデータソースを選択して[ 計算 ]をクリックすることにより、すべてのステップのすべての引数の名前とソースデータのマッピングを作成する必要があります :
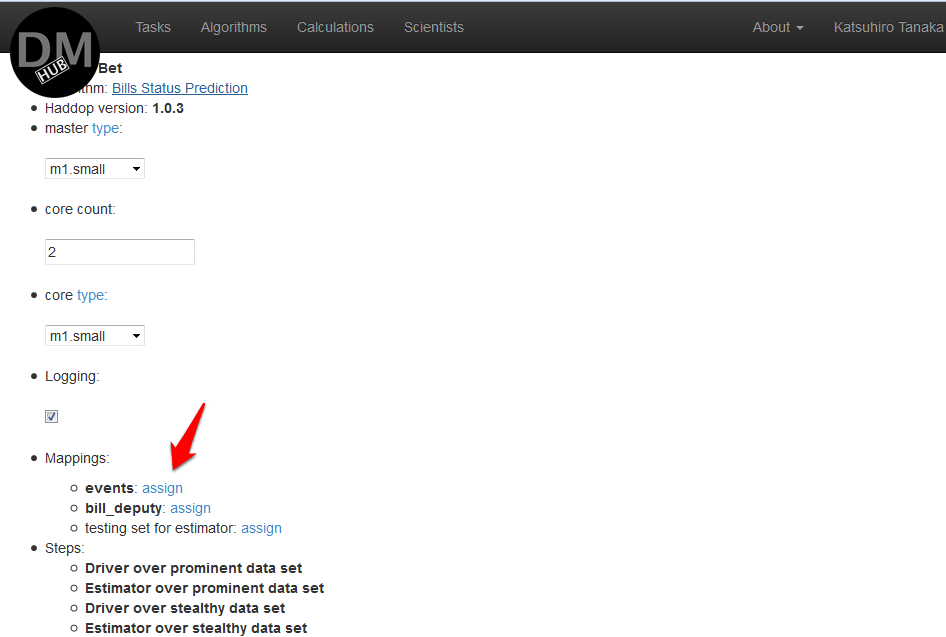
必要に応じて、[保存]ボタンをクリックして、この計算を保存できます。
- すべての操作が完了すると、 計算の詳細ページが表示され、この計算のステータスが表示されます。 計算が完了すると、その結果はこのプロファイルに関連付けられた郵送先住所に送信されます。
処理中の計算例:

完了した計算の例:
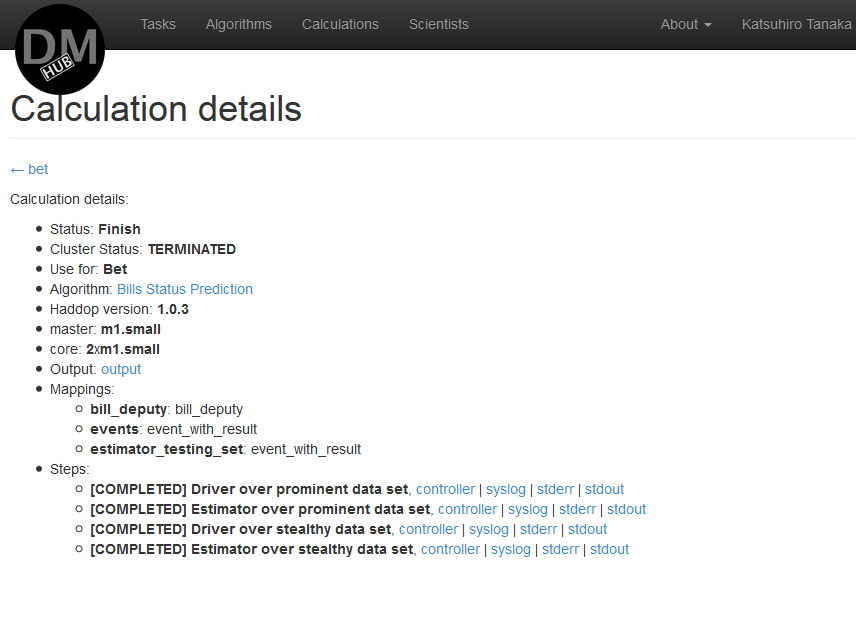
- 計算が完了すると、その結果がタスクの説明とアルゴリズムの使用コストに表示され、顧客はこのアルゴリズムをタスクの解決策として選択できます。
[ アルゴリズムの詳細]ページのナビゲーションパネルで[ 試用 ]をクリックして、このアルゴリズムを使用するコストを設定する前に、データのアルゴリズムを確認することができます。 [ 計算の編集]ページが表示されます。[ マッピング]セクションには、計算用のデータをロードし、ナビゲーションパネルの[ 計算 ]をクリックする必要があります。
ps-このテキストに貴重な貢献をしてくれたユージニアに感謝します!