私はすでに、プロジェクトのすべての変更をA / Bテストで確認し、ユーザビリティラボで監査を命じ、変換が悪名高い2回になるまで待つウェブマスターとマネージャーの数十、または数百を想像しています。 本当に何が起こる-それを把握しましょう...
実際、A / B検定は一般的な統計実験であり、統計のすべての規則に完全に準拠しています。 これらの規則によれば、「コンバージョンの17%の変化」という概念は存在しません。
理論的根拠に興味がある人のために
10%の信頼区間で17%の変換の変化がある可能性があります(この場合、変化は重要です)。
そして、これは次のようになります。20%の信頼区間で17%の変換の変化(この場合、変化はわずかです)。
変更が信頼区間で分散するために知っておく必要がある変数は何ですか?
1)対照群のサイズ(導入:95%信頼区間、統計的検出力80%);
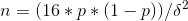 どこで
どこで
ここで、δは最小検出可能効果(%)です。
p-ベース変換
nは、各グループの参加者の数です。
次に、2%の基本的な変換と17%(0.34%)の変更のために必要です。
n =(16 * 0.02 *(1-0.0034))/0.0034²=有意な変化を記録する各グループの27731人の参加者。
2)信頼区間:
 どこで
どこで
p-ベース変換
nは、各グループの参加者の数です。
z-95%の精度の場合は2、99.8%の精度の場合は3
2%変換、95%精度、10,000サンプルサイズの信頼区間の例:
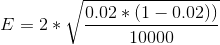 = 0.0028(0.28%。これは、実験中に得られたすべての値を意味しますが、2.28から1.72の間は重要ではありません)。
= 0.0028(0.28%。これは、実験中に得られたすべての値を意味しますが、2.28から1.72の間は重要ではありません)。
このことから、ほとんどのRunetサイトでは、A / Bテストを実施しても重要な結果を得ることができず、トラフィックがほとんどないという仮定を立てることができます。
現在、ほとんどのSaaSソリューションは、統計的に重要ではないサンプルでのA / Bテストの結果を示していますが、これから多くの誤った結論を出すことができます。
そして、これは次のようになります。20%の信頼区間で17%の変換の変化(この場合、変化はわずかです)。
変更が信頼区間で分散するために知っておく必要がある変数は何ですか?
1)対照群のサイズ(導入:95%信頼区間、統計的検出力80%);
どこで
ここで、δは最小検出可能効果(%)です。
p-ベース変換
nは、各グループの参加者の数です。
次に、2%の基本的な変換と17%(0.34%)の変更のために必要です。
n =(16 * 0.02 *(1-0.0034))/0.0034²=有意な変化を記録する各グループの27731人の参加者。
2)信頼区間:
どこで
p-ベース変換
nは、各グループの参加者の数です。
z-95%の精度の場合は2、99.8%の精度の場合は3
2%変換、95%精度、10,000サンプルサイズの信頼区間の例:
= 0.0028(0.28%。これは、実験中に得られたすべての値を意味しますが、2.28から1.72の間は重要ではありません)。
このことから、ほとんどのRunetサイトでは、A / Bテストを実施しても重要な結果を得ることができず、トラフィックがほとんどないという仮定を立てることができます。
現在、ほとんどのSaaSソリューションは、統計的に重要ではないサンプルでのA / Bテストの結果を示していますが、これから多くの誤った結論を出すことができます。
私たちは上からタスクを与えられました-A / Bテストを実施し、それを常に使用する方法を学ぶために。
「もっと簡単にできること」ユーザーCookieのすべてのトラフィックを偶数/奇数に分割し、URLとYaに何かを掛けます。メトリックスまたはGA自体が、テストについての真実を伝えます。 今、私は自分がいかに間違っていたかを理解しています。
とても幸運でした。 システムアーキテクトはすぐにハードウェアに慣れ、すべてを理解し、必要なすべてのパラメーターを再カウントするためのシンプルなインターフェイスを作成しました。 測定を開始しました(参照用-サイトへの1日のトラフィックが30,000ユニークユーザーを下回ることはめったにありません):
A / BテストNo. 1 (ユーザーへの一連の推奨事項の存在をテストします(プロジェクトを開始し、プロジェクトに命を吹き込み、リードを獲得したかった)。
私が言うように、私は「ビーコンによって」見ます、アーキテクトはすべてを書きます。
初日+ブロックでコントロールグループのリードの10%、手をこすります(ボーナスのようなにおいがします)。
秒+ 9%-何でも点火
...
ビーコンで平均して1週間が経過しました-良い+ 7%、A / Bテストを終了し、すべてのユーザーに対してブロックをオンにします。 (アーキテクトは、「間隔は分岐していません」と言います。私はこれを重要視しませんでした)。
A / BテストNo. 2 (テストブロックサイズの推奨事項)
彼らはテストを1ヶ月以上運転しました-有意な結果はありませんでした。
私たちは音声でリーダーシップに報告します-A / Bテストの実施方法を学びます-すべてを数えることができます。 新しいタスクの機能:Apple.comのような1つの大きな画像と最小限のメニューを備えたサイトを作成しましょう。
A / Bテスト3 (Aggregator vs Monobrand)
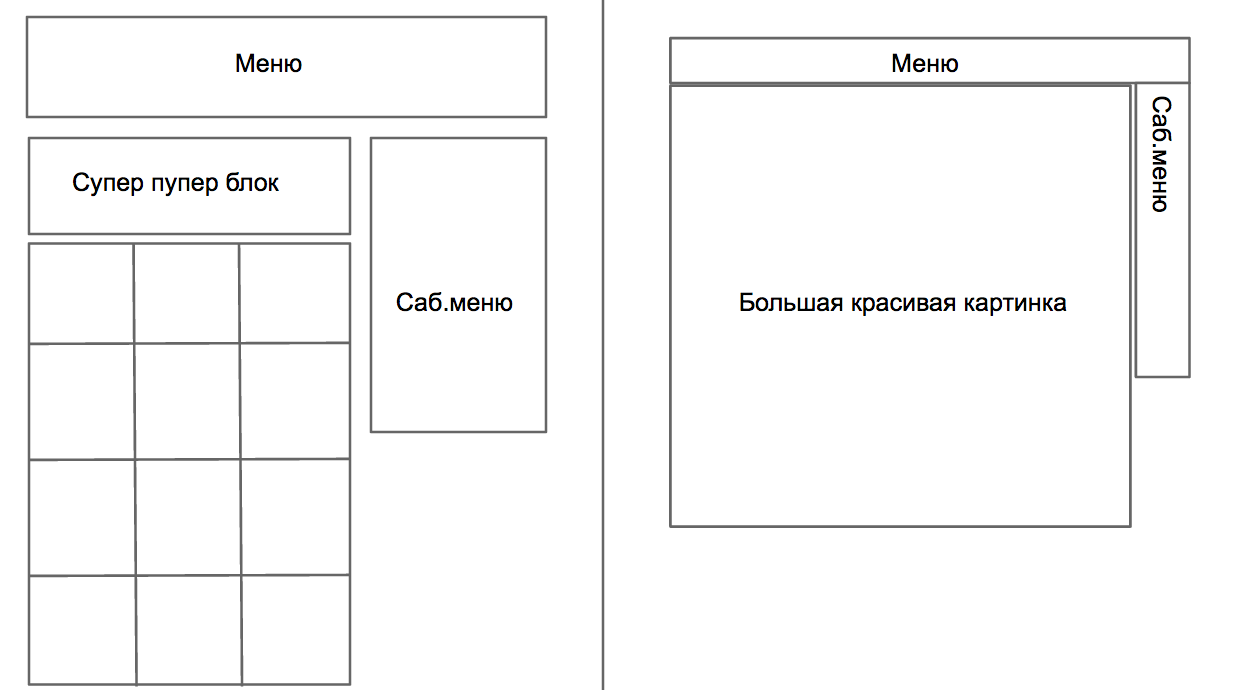
「はい、できません。動的な推奨事項に一生懸命取り組みました。ここでは、Apple.comのようにこんにちは」-多くの感情がありましたが、何もすることはありませんでした-彼らは何とかして、テストを開始しました。
初日とテストページでは、さらに多くの情報が得られます-13%。 私は恐怖を持っていますが、私の専門知識はどうですか...材料は働き始めました。
二日目-指標のバランスが取れたので、待つ必要があることに気付きました。
10日が経過し、信頼区間が最終的に分散し、古いページは本当に良くなったことが判明しましたが、時々ではなく、少しだけ改善されました。 冷蔵庫の全体的なコンバージョン率+ 12%、信頼区間10%、つまり 確実であるか、テストをさらに進めることができるのはわずか2%です。
A / Bテストを実施する際には、間違いを犯さないようにしてください。結果の統計的有意性を確認し、それに基づいて特定の結論がどのようになされたかを尋ねてください。
P.Y. 2番目のロシアのアレクサンドルを超えるプロジェクトのA / Bテストは神話です。 トラフィックが十分ではありません。