私はここでいくつかの問題を一度に見ます:手動テスト担当者は、書かれたテストケースに対応する自動テストの量を知りません。 手動テスト担当者は、自動テストの対象を正確に知りません。 Automatorsはレポートの解析に時間を費やします。 奇妙なことですが、3つの問題はすべて1つに起因しています。テストの結果は、これらのテストを書いたオートマトンだけが理解できるものです。 これは私が不透明度と呼ぶものです。
ただし、透過的なプロセスがあります。 これらは、必要なすべての情報がいつでも利用できるように構築されています。 このようなプロセスを作成するには、最初は多少の努力が必要になる場合がありますが、これらのコストはすぐに回収されます。
そのため、機能テストの作成と実行のプロセスを透明にするツールであるAllureを開発しました。 美しく明確なアリュールレポートは、チームが上記の問題を解決し、最終的に同じ言語を話し始めるのに役立ちます。 このツールは、既に使用されているテスト自動化ツールと簡単に統合できるモジュール構造になっています。
待って、別のトゥキュディデスを作った?
要するに、はい。 Thucydidesは透明性の問題を解決するための本当に優れたツールですが、...私たちは1年間積極的に使用しており、Yandexテストでの生活と両立しない問題「出産時の怪我」をいくつか特定しています。 主なものは次のとおりです。
- Thucydides-Javaフレームワーク(テストはJavaでのみ記述できることを意味します);
- ThucydidesはWebDriverを中心に設計されており、Webアプリケーションの受け入れテストのみに焦点を当てています。
- トゥキュディデスは、建築の面ではかなりモノリシックです。 はい、彼は箱から出して多くの機会を持っていますが、これらの機能を超えて何かをする必要がある場合、自分を撃つのは簡単です。
アリュールも同じアイデアを実装していますが、Thucydidesのアーキテクチャ上の欠陥はありません。
これをどうやってやったの?
最初の問題:テスターは、自動テストが記述されたテストケースとどのように一致するかを知りません。
この問題の解決策は長い間存在し、それ自体が十分に証明されています。 テストを記述するためにDSLを使用し、続いて自然言語に変換します。 このアプローチは、 Cucumber 、 FitNesse、または前述のThucydidesなどの有名なツールで使用されています。 単体テストでも、テスト対象が正確に明確になるようにテストメソッドを呼び出すのが一般的です。 では、機能テストに同じアプローチを使用しないのはなぜですか?
これを行うために、テストステップまたはステップの概念をフレームワークに導入しました。これは単純なユーザーアクションです。 したがって、テストはこのような一連のステップになります。

自動テストコードのサポートを簡素化するために、ネスト手順を実装しました。 異なるテストで同じ手順のシーケンスを使用する場合、1つの手順で説明してから再利用できます。 手順の観点から提示されたテストの例を見てみましょう。
/** * , .<br> * . */ @Test public void cancelWidgetAdditionFromCatalog() { userCatalog.addWidgetFromCatalog(widgetRubric, widget.getName()); userWidget.declineWidgetAddition(); user.opensPage(CONFIG.getBaseURL()); userWidget.shouldNotSeeWidgetWithId(widget.getWidgetId()); userWidget.shouldSeeWidgetsInAmount(DEFAULT_NUMBER_OF_WIDGETS); }
このようなコード構造を使用すると、チームの誰でも理解できるレポートを簡単に生成できます。 メソッドの名前は、テストケースの名前に解析され、内部の呼び出しのシーケンスは、ネストされたステップのシーケンスに解析されます。
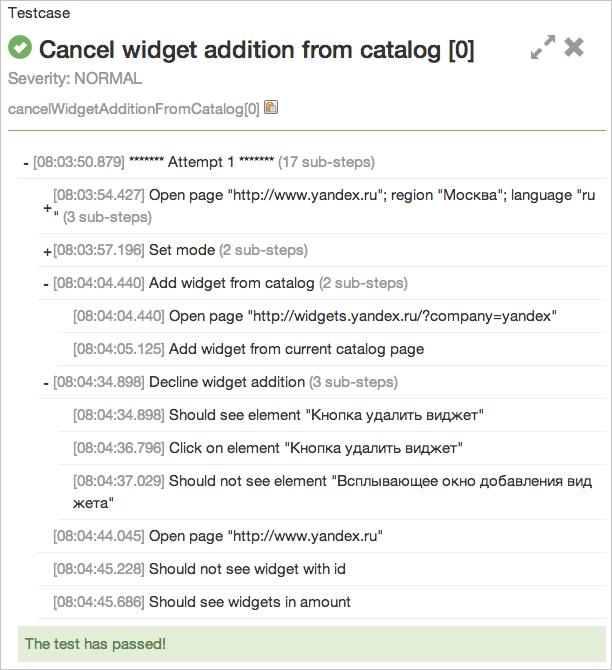
さらに、任意の数の任意の添付ファイルを任意のステップに添付できます。 誰もが既に知っているスクリーンショット、ページのCookieまたはHTMLコード、またはよりエキゾチックなもの:リクエストヘッダー、レスポンスダンプまたはサーバーログのいずれかです。
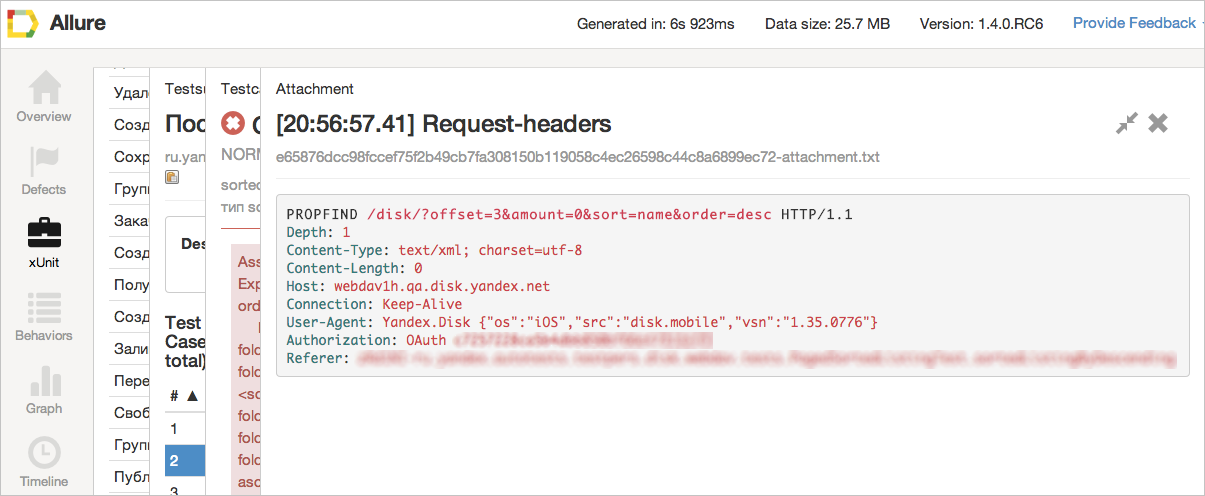
2番目の問題:テスターは、自動テストの対象が正確にわからない。
テストコードに基づいて実装に関するレポートを生成する場合、テスト済みの機能に関する概要情報でそのようなレポートを補足してみませんか? このために、機能とストーリーの概念を紹介しました。 注釈を使用してテストクラスをマークアウトするだけで十分であり、このデータは自動的にレポートに入ります。
@Features("") @Stories(" ") @RunWith(Parameterized.class) public class IndexTest { … }
ご覧のとおり、自動化のコストは最小限であり、出力はテスターだけでなくマネージャー(またはチームの他の人)にとっても有益な情報です。
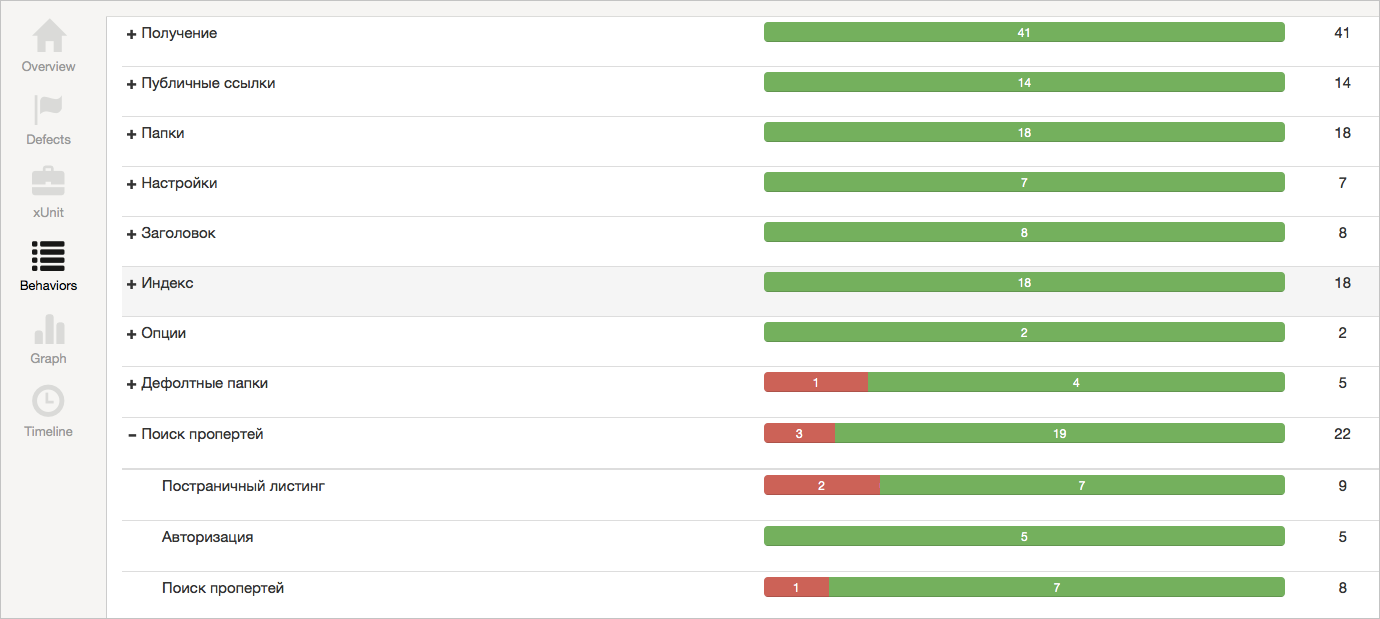
問題3:オートメーターはレポートの解析に時間を費やします。
テストの結果はすべての人に明確になったので、テストがクラッシュしたときに問題が何であるか(アプリケーションまたはテストコード)が完全に明確になるようにする必要があります。 この問題は、テストフレームワーク(JUnit、NUnit、pytestなど)のフレームワーク内で既に解決されています。 チェック後の立ち下がり(アサート、ステータス失敗)と、例外による立ち下がり(壊れたステータス)には、別々のステータスがあります。 この分類は、レポートの作成でのみサポートできます。
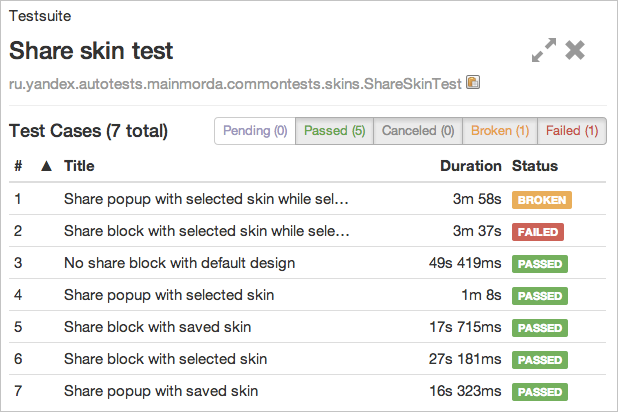
また、上のスクリーンショットでは、保留中およびキャンセル済みのステータスもあることがわかります。 1つ目は起動から除外されたテスト(JUnitの@Ignoreアノテーション)を示し、2つ目は前提条件の低下(失敗と見なす)により実行時に失敗したテストを示します。 これで、レポートを読むテスターは、テストでバグが検出されたとき、および自動化エンジニアにテストを修正する必要があるときをすぐに理解します。 これにより、リリース前のテスト中だけでなく、以前の段階でもテストを実行でき、その後の統合が簡素化されます。
私も欲しい!
また、テストの自動化プロセスを透明にし、テスト結果をすべての人が理解できるようにする場合は、Allureを自宅に簡単に接続できます。 すでに、さまざまなプログラミング言語用の最も一般的なフレームワークとの統合があり、ドキュメントもあります=)。 アリュールの実装とそのモジュールアーキテクチャの技術的な詳細については、次の投稿とプロジェクトページを参照してください 。