あるプロジェクトの入り口で、私は超高速のロシアの形態を作成しなければなりませんでした。 かなり弱いラップトップでは1秒あたり約50,000ワードで、スタンミング(ルールに従ってエンディングをトリミングする)よりも2〜3倍遅いだけですが、はるかに正確です。 このデータは通常のディスク、SSD、または仮想ディスク上にあるため、検索ははるかに高速です。
最初のバージョンはMySQLでしたが、それをファイルに変換することで生産性を100倍に高めることができました。 ファイルがMySQLよりも高速である理由と理由については、記事で説明します。
しかし、初心者にとっては、私の実装に興味のある人を苦しめないように。 GitHubのリンクをご覧ください 。 PHPのソースがあります。 他の言語では、アナログを書くのは非常に簡単で、100行を超えるコードはありません。 主な問題は、データベースを既に完成した検索可能な形式に変換することです。 あなたの言語に検索を移植するだけです。
挑戦する
コンテキスト広告のテーマに少しでも関わっている人は誰でもYandex.WordStatを使用しています 。 これは、キーワードを選択するためのサービスです。 ただし、多くのノイズが含まれています。
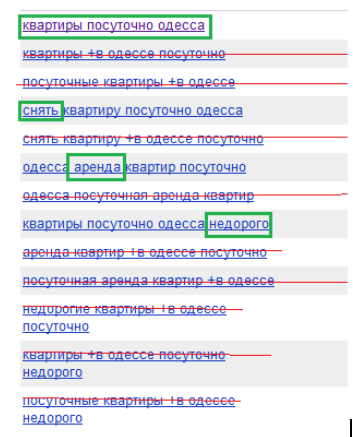
過去のものを複製するすべてのリクエストは、スクリーンショットで取り消されます。 メインリクエストと絞り込みの違いは緑色で強調表示されます。 つまり スクリーンショットにあるこれらの60の単語はすべて6分の1で記述できます。
オデッサのアパートメント 離陸する 借りる 安く
つまり WordStatの情報の90%はノイズです。 しかし、主な問題は、データをコピーし、ノートブックに貼り付けて編集する必要があることです。 ユーザーがチェックマークを使用する方が便利でした。 ここでは、たとえば、WordStatと結果として得られたものを比較します。
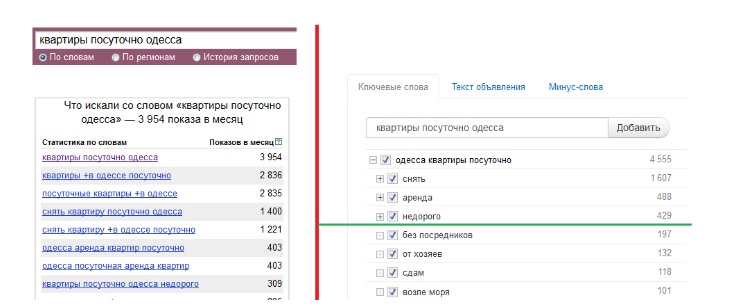
スクリーンショットではYandex.WordstatとHTrafficを使用しています。 データのみ、異なる視覚化。
一般に、これにより、キーワードの選択を10〜20倍高速化できます。 ただし、これにはすべて形態が必要です。 同時に、Wordstat APIは最大200のリクエストを発行でき、各リクエストには平均5ワードが含まれます。 これはすでに1000ワードです。 さらに、リクエストとともに、同義語を打ち破り、最大10個まで指定できます。 つまり 10,000語は非常に現実的な状況です。
もちろん、キャッシュを使用して、以前に見つかった単語形式を記憶することができます。 その後、検索の数は10に1回減少します。しかし、これは速度の問題を完全に排除するわけではありません。
同音異義語と正規化
速度だけが問題ではありません。 ロシア語は大きすぎて強力です。 膨大な数の単語形式(別のケースではスペル、性別など)があります。 また、異なる単語の異なる単語形式が同じ方法で記述される場合があります。 これは同音異義語と呼ばれます。 たとえば、システムでテキスト内にワードライン「デリー」が検出された場合、どの単語に帰属する必要があるかはわかりません。
- デリー 「デリーはインドの首都です。」
- 共有する。 「大胆に2で割った。」
- 子。 「靴下はどこで共有しましたか?」
このようなあいまいさが私たちを大いに妨げます。 各単語文字列の解釈が1つだけであれば、はるかに便利でした。 この場合、コードがはるかに少なくなり、速度が向上します。
しかし、機械の同名性を解決することを教えることは難しい作業です。 実装には多くの時間がかかり、パフォーマンスに悪影響を及ぼす可能性もあります。
Yandex.Directからこの問題の解決策をコピーしました。 同音異義語を持つ単語を1つに結合します。 つまり 1つのIDを取得します。 リクエストに検索された単語が含まれていないが、それに貼り付けられている場合、これはグリッチにつながることがありますが、これはめったに起こりません。 それ以外の場合、Directはそのようなソリューションを使用しません。
ベースAOT.ru
RuNetには、ロシアの形態の無料のベースが1つだけあります-Aot.ru。 約20万の単語があり、それぞれに平均で約15の単語形式があります。 そのドキュメントは非常に紛らわしく、不正確です。 したがって、それを説明するためにいくつかの段落を費やします。
ベースは次のようになります。末尾、接頭辞、および単語のセットがあります。 単語には、疑似基底(大まかに言って単語のルート)、接頭辞の番号(ある場合)、末尾の番号があります。 単語のすべてのバリエーションを生成するには、ループ内の末尾をループし、接頭辞と擬似ベースをそれぞれの前に追加する必要があります。
いくつかのポイントがあります:
- 擬似的な基盤はないかもしれません。 例:行く、歩く。 この場合、「#」が擬似ベースではなくベースに書き込まれます。
- 終了テーブルに接頭辞がある場合があります。 これは最上級の形容詞で起こります(最高->最高)。 末尾からのプレフィックスは、メインプレフィックスの前に配置する必要があります。
語尾が語から分離されている場合のベースのタイプは、圧縮と呼ばれます。 この場合、ベースの重量はわずかですが、検索は非常に遅くなります。 したがって、辞書は「未開封」である必要があります-各単語形式を個別に書き留めます。 ただし、データベース内の単語形式は数百万であるため、これには数十メガバイトが必要です。 データベースに目を向けた最初のこと。
MySQL
すべての単語形式を、テキストと単語のIDの2つの列を持つ1つのテーブルに記述しました。 単語形式のテキストにインデックスを追加しましたが、速度は非常に低かったです。 テーブル最適化手順の実行は役に立ちませんでした。
同じ理由を理解するために、私はすぐにINを介して10個の単語を検索し始めました。 したがって、速度はわずかに増加しました。 SQLの解析に関するものではなく、NO-SQLは役に立ちません。
インデックスタイプとストレージを備えたゲームもほとんど何も生成しませんでした。
また、MySQLを他のエンジン(Mongoなど)と比較するいくつかのパフォーマンステストも調査しました。 ただし、単一のエンジンが、それらのMySQLに対する読み取り速度の顕著な優位性を示しているわけではありません。
CRC32
インデックスの長さを短くすることにしました。 単語形式のテキストは、チェックサム(crc32)に置き換えられました。
単語の形式は約200万、2 ^ 32 = 40億なので、衝突の確率は0.05%になります。 よく知られた言葉によると、合計で約1,000回の衝突があり、連想配列内のすべてを実際のIDで指定するだけで、それらを除外できます。
if(isset($Collisions[$wordStr])) return $Collisions[$wordStr];
しかし、これは誤検知操作を除外するものではありません。単語形式がデータベースにない場合、2000分の1の場合、左側のIDが返されます。 しかし、これは巨大な膨大なデータ配列(Wikipediaなど)を検索する場合にのみ重要です。
人の語彙は10,000語を超えると非常にまれです。 たとえば、レオトルストイには20,000人がいます。 データベースには200,000個の単語があります。トルストイの全作品で検索を整理すると、衝突のために彼が余分なものを見つける可能性は10 * 2000に1になります。つまり、 1から20,000。
つまり、crc32の使用に起因するグリッチの可能性は非常に小さいです。 そして、これは生産性の向上とデータ量の減少によって相殺されます。
しかし、これはあまり役に立ちませんでした。 速度は毎秒約500ワードでした。 私はファイルに目を向け始めました。
ファイル
MySQLを最適化するすべての方法を試したとき、形態辞書をファイルに書き込み、バイナリ検索で検索することにしました。 結果は私の期待を上回りました。 速度はどこかで3倍になりました。
私にとって、この数字はPHPで書いたので予想外でした。スクリプト言語にはオーバーヘッドがあります(マーシャリングなど)。 同時に、MySQLと私の実装では、バイナリツリーとクイック検索という類似のアルゴリズムを使用しています。
どちらの場合も、複雑さはlog(n)です。 つまり log2(2.000.000)〜21、ファイルからの読み取り操作が発生します。 PHPは、文字列を現在のビューから21回、独自のビューに変換する必要があります。 MySQLでは、これは起こりません。 理論的には、PHPの速度は著しく低下するはずです。
問題を理解するために、読み取り用のファイルブロックを追加しました。 ロック自体はここでは必要ありません。これは、読み取りと読み取りが競合しないため、1つのスレッドでテストしたためです。 オーバーヘッドは面白かった。 速度が1.5倍低下しました。 主な理由の1つは、MySQLが複数のスレッドでの書き込みの競合を防ぐことである可能性が高く、これはタスクでは必要ありません。
しかし、これは速度の差の半分でも説明しません。 残りのブレーキがどこから来たのかは私には明らかではありません。 木とドライバーは頭上を運ぶことができますが、それほど大きくありません。 あなたの意見はコメントで興味深いものです。
ハッシング
ツリーは、データを見つけるための最適な構造ではありません。 ハッシュははるかに高速です。 ハッシュには一定の時間があります。 私たちの場合、21の運用ではなく、1-2を費やします。 この場合、読み取りは連続して行われます。 ディスクキャッシュの動作が改善され、読み取りヘッドを前後にジャンプする必要がなくなります。
ハッシュは、たとえばPHPで連想配列を実装するために使用されます。 バイナリツリーを使用すると、ソートや多かれ少なかれ演算子を整理できるため、データベースで使用されます。 ただし、ある値に等しい要素を選択する必要がある場合、ここではツリーが大きなテーブルで数十回ハッシュを失います。
したがって、ライブラリを10〜15倍高速化することができました。 しかし、私はそこで止まらず、CRCとIDワードを異なるファイルに保存し始めました。 したがって、読み取り値は完全に一貫したものになりました。 また、いくつかの検索を実行する間、ファイルポインターを開いたままにしました。
MySQLの前の合計パフォーマンスの向上は80〜100倍でした。 評価の広がりは、私が異なる比率のエラーと正しい単語形式でテストしたという事実によるものです。
結論
私は、いつでもどこでもデータベースをファイルで置き換えることを求めません。 データベースにはさらに多くの機能があります。 しかし、この置換が正当化される場合がいくつかあります。 たとえば、これらは静的なベースです(IPによる都市、形態)。 この場合、ファイルへの切り替えなどにより、作業が楽になります。別のサーバーにインストールする場合は、ファイルをコピーするだけで十分です。
データベースの主な機能は、スレッド間の競合を取り除くことです。 これは、ファイルを操作するときに整理するのが非常に困難です。 記録の進行中、DBは読み取りをブロックします。 しかし、高負荷では、これが問題を引き起こします。
所有していないサーバーとフローの数。いずれかがデータベースにデータを書き込むと、それらはすべてブロックされます。 それはすべてストレージのタイプに依存し、行レベルでロックをかけるものもありますが、これは常に役立つとは限りません。
したがって、多くの場合、ベースは共有されます。 1つは読み取りに使用され、2つ目は書き込みに使用されます。 それらは、たとえば夜間など、時々同期されます。 ほとんどの読み取り要求で「=」演算子を使用して選択した場合、ファイル内にテーブルのコピーを作成し、ハッシュを使用することで、速度を何度も上げることができます。
記録データベースの速度が低下した場合、場合によっては、変更のあるログのようなものを書き込む方が速くなり、同期するときにこのログを通常のデータベースに変換します。 しかし、このオプションは常に役立つとは限りません。