
今日は、レコメンダーシステムについて、または最も単純な形式の協調フィルタリングについて説明します。 プログラムガイドでは、レコメンダーシステムとは何か、それは何に基づいているのか、数学的装置とは何か、どのようにコードに組み込むことができるのか。 ボーナスとして、シンプルなサービスの形で結果を提供します。
推奨システムとは
実際、私たちは、時々気付かなくても、レコメンダーシステムに毎日遭遇します。 最も明確な形式では、彼らの作品はAmazonオンラインストアなどで見ることができます。

システムの主な目的は、購入した視聴に基づいて新しい製品を提供することです。 一度にいくつかの目標が追求されますが、主な目的は、販売につながり、自分のニーズを満たす可能性が最も高いバイヤーに製品を提供することです。 そのため、非公式に、リコメンダーシステムは、購入者の履歴に基づいて製品のソートされたリストを提供します。
直観
この記事では、ユーザーベースの協調フィルタリングについて説明しています。 この名前は恐ろしいように見えるかもしれませんが、非常に単純なアイデアが背後にあります。 「共同」とは、特定のグループの好みに基づくことを意味します。 たとえば、Vasya、Petya、およびSashaが本屋のバイヤーであり、それらの好みが似ている場合、VasyaとPetyaのショッピング履歴に基づいてSashaショッピングを推奨できます。

( ここから撮影した写真)。
この写真は、複数のユーザーがビデオを視聴し、一部のユーザーだけがそれを気に入ったという単純な状況を説明しています。 ユーザーに動画を推奨するかどうかを判断すると、同様のユーザーがこの動画を嫌っていることがわかります。 その結果、推奨する価値はありません。 つまり、 類似のグループに基づいてコンテンツをフィルタリングするため、 共同フィルタリングという名前になります 。
理論
この記事では、バイナリ評価の場合、「いいね」または「評価なし」のみを検討します。 このモデルは、Habréのお気に入りに適用できます。 ユーザーが自分で記事を保存した場合、ユーザーはその記事を興味深いまたは有用であると見なし、評価がない場合、これは何の意味も持たず、この記事を見なかっただけかもしれません。
コンテンツをフィルタリング(またはランク付け)するにはいくつかの方法があります。いわゆるユーザーベース ( ユーザーベース )の方法を検討します 。
データ
2つのエンティティユーザーとお気に入りの記事があります。 各ユーザーiに、多くの記事u iを関連付けます。
類似ユーザー
2人のユーザーiとjの「類似性」を次のように定義します。
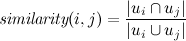
これは、いわゆるジャカード係数であり、2つのセットの類似度を決定します。
アイデアは単純です-2人のユーザーの記事の合計部分が合計数にどの程度関連しているかを判断する。
おすすめの記事
一部の記事p (投稿から)がお気に入りに含まれないようにします。 はセットu iに属さないため、次のように、ユーザーと記事の間で「いいね!」の類似度(「どれだけ気に入ったらいいか」)を決定します。
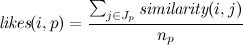
ここで、 n pとJ pは、ユーザーの数と、投稿pのお気に入りを追加したユーザー自身です。
式の背後にある考え方は単純で、1人のユーザーの貢献度は類似度に等しく、ユーザー自身の数による正規化です。
推奨事項
推奨事項とは、最大の「 いいね!」数がある投稿です 。
実装:コードとデータ
実装するには、いくつかの手順を実行する必要があります。
- ユーザーリストを収集する
- 推奨事項を収集する
- カウントn p
- likes関数を作成し、最大k個の結果を取得します
ユーザーリストを収集する
アルゴリズムは単純です。2013年の最初の投稿の1つが選択され、コメントを残した各投稿ユーザーが収集され、投稿の著者自身が収集されました。 合計で、25,000人のユーザーのリストが作成されました。 関数コードget_all_user_namesは、ファイル内のgitから見ることができます。recommender.pyおよびHabraDataリポジトリー(これはHabrからあらゆる種類の興味深いデータを収集するリポジトリー)内のユーザーのアセンブルリストですuser_list.txt
推奨事項を収集する
たとえば、各ユーザーにはお気に入りタブがあり、リストからデータを解析および取得できます。 収集されたデータはuser_favorites.csvファイルにあり、収集コード自体は上記と同じソースコードにあります。
カウントn p
収集された投稿ごとに、すべてのユーザーを調べて、投稿が表示された回数をカウントします。 post_counts.csvファイルのデータ。
いいね機能
主な機能コードは以下のネタバレに記載されています。 簡単な説明:各ユーザーについて、他のすべてのユーザーとの類似性を考慮し、他のユーザーの類似性がゼロでない場合、入力ユーザーと対応する投稿の類似性を更新します。 最後に、正規化して降順に並べ替えます。
def give_recommendations(ユーザー名、設定、重み)
def give_recommendations(username, preferences, weights): preference = preferences[username] rank = {} for user_other, preference_other in preferences.iteritems(): if username != user_other: similarity = jaccard_index(preference, preference_other) if not similarity: continue for post in preference_other: if post not in preference: rank.setdefault(post, 0) rank[post] += similarity #normalize and convert to post_list = [(similarity/weights[post], post) for post, similarity in rank.items()] post_list.sort(reverse=True)
読むには:実用的な書籍Programming Collective Intelligenceとこの投稿 。
Habra-recommendationsサービス
アルゴリズムに基づいて、ユーザー向けのシンプルな推奨サービスを作成します。
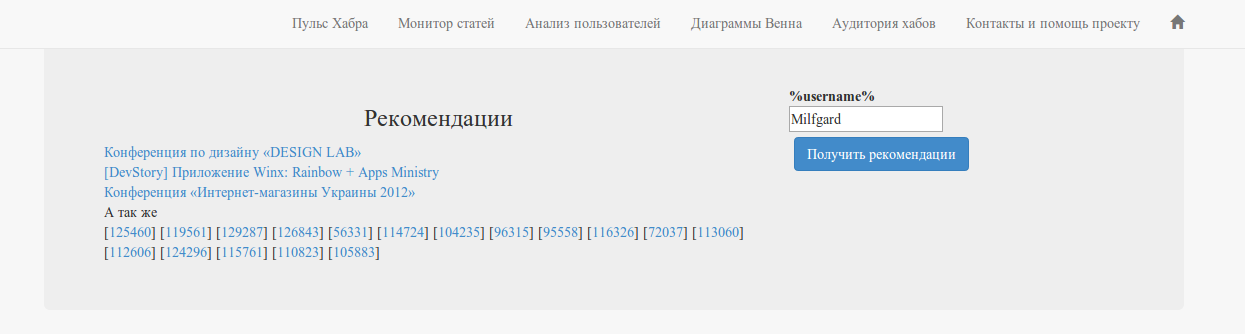
で利用可能:
www.habr-analytics.com/recommender
(慎重に、著者は午前4時に推奨システムをテストしました。)
この記事で検討するアルゴリズムは、最も単純で最も素朴なものの1つであるため(モデルの仮定による)、その作業の結果を過大評価しないでください。 一方、高度なアルゴリズムは、主に同じアイデアに基づいており、同様の手法を使用して推奨事項をモデル化するため、少なくともユーザーベースのフィルタリングの一般的な理解が必要です。
Habra Analytics
Habrの例の分析に興味があれば、推奨事項に加えて、プロジェクトwww.habr-analytics.comの現在のバージョンは、記事モニター、ユーザー分析、および他の多くのオプションをサポートしています。 このシステムの興味深いアプリケーションの詳細については、「 ステップシンドロームとHabr Attendanceスライス 」の記事をご覧ください 。
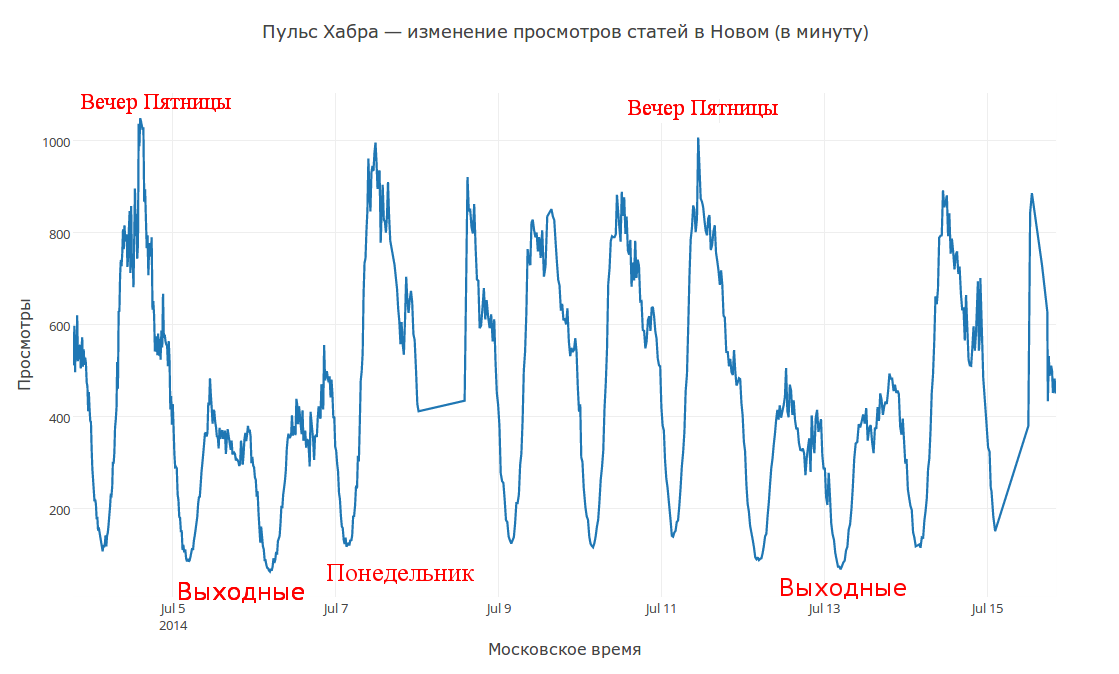
また、 この記事では、各機能について個別に説明しています。