内容:
1. 指定されたクラスの画像上に目立つオブジェクトを構築するのに最適な色空間の検索と分析
2. 分類の主要な特徴の定義と、表情の数学的モデルの開発
3. 最適な顔認識アルゴリズムの合成
4. 顔認識アルゴリズムの実装とテスト
5. さまざまな状態のユーザーの唇の画像のテストデータベースを作成して、システムの精度を向上させる
6. オープンソースの音声認識に基づいて最適な音声認識システムを検索する
7. 統合のためのオープンAPIを備えた最適なクローズドソースオーディオ音声認識システムを検索する
8. テストレポートを使用して、ビデオ拡張機能を音声認識システムに統合する実験
目標
顔の表情の認識におけるその後の実装とテストに最適なアルゴリズムを決定します。
タスク
分類の主要な特徴と私たちが定義した数学的モデルを考慮して、人間の顔とその特性の既存のビデオ認識アルゴリズムを分析します。 得られたデータに基づいて、モバイルデバイスまたはコンピューター用の顔認識技術を実装するタスクの後続の実装に最適な視覚認識アルゴリズムのバージョンを選択します。
テーマ
モバイルデバイス向けの生産的な顔認識システムを実装するタスクに直面しているため、この問題を解決するための最適なアルゴリズムを選択する際には、次の手順から進める必要があります。
•低解像度および高ノイズレベル(スマートフォンおよびPCのほとんどの前面VGAカメラで一般的)。
•毎秒25フレームの頻度でデータを計算するためのモバイルデバイスとコンピューターの低い生産要件。
•高速(オンラインビデオ処理用)。
上記の条件に基づいて、顔認識タスクに最適なアルゴリズムを選択する際には、最小限のシステム要件で非常に効率的な信頼性の高いアルゴリズムに焦点を合わせる必要があります。 また、問題を解決するために最適な顔認識アルゴリズムを合成するとき、研究の前の段階で得た経験を考慮する必要があります。
処理とその後の画像分析のスキームを表形式で提示しましょう(図1)。 同時に、調査のこの段階では、簡単にするために青で塗り直した列を決定する必要があります。つまり、最適なマトリックス認識アルゴリズムを選択します。
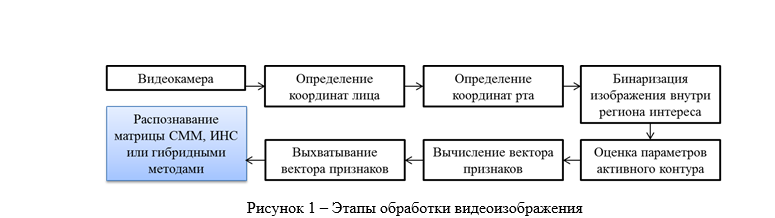
しかし、顔認識タスクに最適なアルゴリズムの選択に進む前に、特徴ベクトルをひったくりのメカニズムを説明する必要があります。
スナッチフィーチャベクトル
前の段階で画像が二値化され、唇の輪郭が選択された後、いわゆるn点オーバーラップ手順が実行され、p1からpnまで時計回りに番号が付けられます。 使用される点の座標は正規化されます。楕円の中間点は原点と見なされ、x軸は楕円の大きな半径の方向に向けられ、楕円の大きな半径は1と見なされます。 点の座標に加えて、唇の輪郭を選択するプロセスでは、元の画像の唇の領域を記述する楕円のパラメータがあります。 楕円のパラメーターを使用すると、口が開いている、または閉じているなど、口の領域の一般的なパラメーターに関する結論を引き出すことができます。 輪郭の番号付けは、唇の輪郭と楕円の左の大きな半径との交点から始まります。
次に、角度を検索します(図2)。 得られたポイントのうち、左右の角度を決定する必要があります。 ポイントの番号付けにもかかわらず、これらは常にポイントp1およびpn / 2ではありません。 直角は、輪郭の右半分(pn / 4とp3n / 4の間)にあるポイントで、角度αが最小になります。 角度αは、平均qnextとqprevの間の角度です。 ここで、qnext =(pi + 1 + ... + pi + k)/ k、qprev =(pi-1 + ... + pi-k)/ k、k = n / 5 同様のルールが左隅にも使用されます[1]。
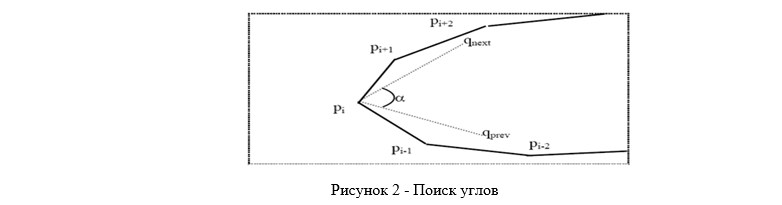
角度を見つけた後の次のステップは、ソースデータのセットを特徴ベクトルのセットに変換することです。 特徴ベクトルの最初の数個の要素として、座標とは別に取得される特徴が使用されます。これは、唇領域の楕円の高さと幅の比です。 特徴ベクトルのその他の要素は、輪郭の左右の角度の座標、輪郭の上下の点の座標、および輪郭の残りの点の座標です。 主成分法によって得られたデータの分析を検討してください。 主成分の方法による基底の選択により、特徴ベクトルが変化する主な方向を見つけることができます。 これにより、特徴ベクトルの次元を大幅に削減できます。 主成分法は、考えられる唇の状態のほとんどを反映するデータセットから取得された特徴ベクトルのセットに適用されます。
次に、人間の顔とその特徴を認識するための最も一般的なアルゴリズムを考えてみましょう。
隠れマルコフモデル(隠れマルコフモデル)の方法に基づくアルゴリズム
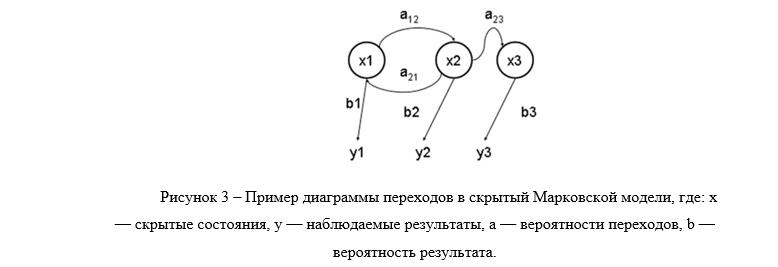
隠れマルコフモデル(SMM)は、マルコフプロセスに類似したプロセスの動作を未知のパラメーターでシミュレートする統計モデルであり、タスクは観測可能値に基づいて未知のパラメーターを解決することです。
各特徴ベクトルは、隠れマルコフモデルのシンボルに関連付けられている必要があります(図3)。 これを行うには、ベクトル量子化法を使用します。 この方法を使用すると、特徴ベクトルの空間は、クラスターの中心への近接の原理により、コードワードによってクラスターに分割されます。 コードワードのセットは、コードブックと呼ばれます。 このメソッドの主な難点は、ベクトルのコードブックを作成することです。 コードブックのサイズは、ソースデータの唇の状態の数によって決まります。 既知のサイズkのコードブックは、K平均アルゴリズムによって構築されます[2]。
アルゴリズムの最初のステップで、コードワード(クラスター中心)と見なされるk個のベクトルがランダムに選択されます。 次のステップで、各入力ベクトルは、コードワードがクラスターから最小距離にあるクラスターに割り当てられます。 3番目のステップでは、各クラスターのコードワードが再カウントされます。 各コードワードは、クラスターのすべてのベクトル間の算術平均に等しくなります。 コードワードの変更が十分に小さくなるまで、2番目と3番目のステップが繰り返されます。
このアルゴリズムは低速ですが、量子化の前に主要なコンポーネントの分析を適用することで、次元を小さくすることができ、コードブックの構築プロセスを大幅に加速できます[3]。 新しい初期データは、認識プロセスで使用される前に量子化されます。各ベクトルはコードブックから最も近いベクトルに関連付けられ、ベクトルの代わりに、コードブックのインデックスが隠れマルコフモデルのシンボルとして使用されます。
さまざまな音素の口形がかなり近いため、画像認識は口形素レベルでは機能しません。 さらに、バイソンのシーケンスに基づいた認識-ダイフォン、トリフォン-ははるかに信頼性が高いです[4]。 認識には、エルゴードの隠れマルコフモデルのシステムが使用されます[5]。 各ディフォンには独自のSMMがあります。 SMMは、シンボルと状態遷移の等しい確率で初期化されます。 ただし、このようなモデルは、自由度が高いため、トレーニングデータに適切に調整されておらず、認識の品質に悪影響を及ぼします[6]。
SMMシステムは、一連の量子化された特徴ベクトルを使用してトレーニングされます。 初期データは手動で訓練されたディフォンに分割され、その後、対応するSMMがBaum – Welshアルゴリズムを使用して更新されます[7]。 結果のSMMは、ダイフォンをトレーニングするためのセットに近いシーケンスの最大確率値を提供します。
作業の結果として、音声認識問題の唇の特徴ベクトルを構築するための効率的なアルゴリズムが構築されます。 このアルゴリズムにより、唇の輪郭データを認識に適した特徴セットに変換できます。 このアルゴリズムには信頼性と安定性の特性があり、隠れマルコフモデルに基づく音声認識システムと簡単に統合できます。 ただし、このアルゴリズムの弱点に注意する必要があります。特に、識別能力が弱く、訓練が不十分です。
ニューラルネットワーク(人工ニューラルネットワーク)の方法に基づくアルゴリズム
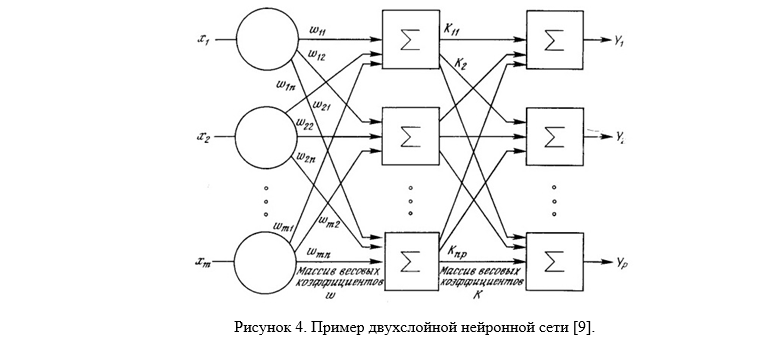
ニューラルネットワークメソッドは、さまざまなタイプのニューラルネットワーク(NS)の使用に基づくメソッドです。 NSは、フォーマルニューロンと呼ばれる要素で構成されます。これらの要素自体は非常に単純で、他のニューロンと接続されています。 各ニューロンは、出力信号の入り口で到着する一連の信号を変換します。 重要な役割を果たすのは、重みによってエンコードされたニューロン間の接続です。 NSの利点(および一貫性のあるアーキテクチャで実装することの欠点)の1つは、すべての要素が並列に機能できることです(図M.4)。これにより、特に画像処理における問題解決の効率が大幅に向上します。 NSが多くの問題を効果的に解決できるという事実に加えて、NSは強力で柔軟かつ普遍的な学習メカニズムを提供します。これは、他の方法に対する主な利点です。 また、ニューラルネットワークのその他の利点の中でも、顔画像の複雑な分布関数をうまくモデル化する分類器を取得できる可能性を認識する必要があります。 欠点は、満足のいく分類結果を得るために、ニューラルネットワークを慎重かつ骨の折れるチューニングが必要なことです[8]。
複合法アルゴリズム
隠れマルコフモデルとニューラルネットワークに基づくアルゴリズムの長所と短所を考慮すると、最近、特定のクラスの画像の認識という科学の世界では、ハイブリッドアルゴリズムが人気を集めています。 研究データによると、ハイブリッドANN / SMM認識機能は、同時信号パラメーター間および現在と次のパラメーター間の相関をモデル化することにより、従来のSMMの精度を向上させます[10]。 つまり、SMMは長期的な依存関係をモデル化する機能を提供し、ANNはノンパラメトリックな普遍近似、確率推定、判別学習アルゴリズム、および標準SMMに通常必要な評価用パラメーター数の削減を提供します[11]。 ただし、複合アルゴリズムを選択する場合、ハイブリッドアルゴリズムのアーキテクチャが大きく複雑すぎると、システムプロセッサによるデータの処理時間が長くなることに留意する必要があります。
おわりに
顔認識問題の最適なアルゴリズムを決定するために、最初にマトリックスアルゴリズムによる後続の分析のために特徴ベクトルを取得するための最も単純で最も信頼性の高いメカニズムを詳細に調べました。 次の段階では、アルゴリズムを構築するための最も有名なモデルである隠れマルコフモデル、人工ニューラルネットワーク、ハイブリッドアルゴリズムの利点と欠点を調べて分析しました。 特徴ベクトルの処理の分野における既存のアプローチとソリューションを研究した後、私たちの意見では、モバイルデバイスとコンピューターに信頼性が高く高速な顔認識システムを実装する、データ処理方法の組み合わせを決定しました。
使用されたソースのリスト
1. Soldatov S. Lip reading:特徴ベクトルの準備。 グラフィックス&メディアラボラトリーMSU、2003
2. A.リンデ、R。グレイ。 ベクトル量子化設計のアルゴリズム。//CommunicatinosCOM-28でのIEEEトランザクション、1980年
3. Soldatov S. Lip reading:特徴ベクトルの準備。 グラフィックス&メディアラボラトリーMSU、2003
4.同じ場所。
5. Gultyaeva T.A.、Popov A.A. 顔認識のための1次元の隠れマルコフモデルの修正//コンピュータグラフィックスとコンピュータビジョンに関する第16回国際会議-GRAPHICON、2006
6. K. SobottkaおよびI. Pitas、自動顔セグメンテーション、顔特徴抽出および追跡のための新しい方法、信号処理:画像通信、Vol。 12、No. 3、pp。 1998年6月263-281
7. Gultyaeva T.A.、Popov A.A. 顔認識のための1次元の隠れマルコフモデルの修正//コンピュータグラフィックスとコンピュータビジョンに関する第16回国際会議-GRAPHICON、2006
8.マカレンコA.A. 非常に正確なニューラルネットワークによる画像の分類。 科学的 セッション-TUSUR-2006。 母校。 Vseros。 科学的および技術的 conf。 学生、大学院生、若い専門家。 パート1。 トムスク、2005年。
9. F.ワッサーメン。 ニューロコンピューター技術:理論と実践(Transl。Into Russian。Zuev Yu.A.、Tochenov V.A.)、1992。
10.チョウザメV.P. 視聴覚音声認識プログラム。//ロシアでの革新的な活動の開発のための人材。 Ershovo、M.、2010。
11. Makovkin K.A. ハイブリッドモデル:隠れマルコフモデルとニューラルネットワーク、音声認識システムへの適用//音声認識システムのモデル、方法、アルゴリズム、アーキテクチャ。 計算します。 それらを中央に置きます。 A.A. Dorodnitsyna、M.、2006。
継続する。