
良い一日。
テキストの視覚認識に関連するコードの読みやすさを向上させる方法の中で、以下を区別できます。
- 構文の強調表示
- インデントを使用する
- 垂直方向の配置
最初の2つの方法はうまく機能しており、ほとんどすべての最新のIDEおよび高度なテキストエディターで使用されています。 3番目の方法では、このような広範な分布は見つかりませんでした。 この記事では、理論的および実用的な観点の両方から、このギャップを埋めようとします。
このタスクが解決されたことがないと断言するのは間違いです。 簡単な検索の結果、私が使用しているSublime Textエディターなど、多くの実装があることがわかりました。
ただし、よく見ると、これらのプラグインのほとんどすべてが、事前に選択された1つのシンボルのみでアライメントを実装していることが明らかになります。 最も高度なバージョンのビルドの中で、次のツールが強調されています 。 しかし、彼には重大な欠点もあります。彼の仕事では、クローズドソースDLLを使用しているため、Linuxを含め、クロスプラットフォームでの使用は不可能です。
この点で、私は問題を解決するための独自の方法を探すことにしました。
最初はソリューションに数晩しか費やさないと思っていましたが、タスクは一見したところよりもはるかに困難でした。
最初の失敗したオプションは、2つの隣接する行で同様のトークンのペアを単純に見つけて、それらを揃えるというものでした。 さらに、そのようなペアを見つける必要があります。まず、互いに重なり合わず、次に、類似度係数の最大加重和を持ちます。 ただし、次の例は、このアプローチの実行不可能性を示しています。
// from f(a, b + c) g(b + c, a) // to f(a, b + c ) g( b + c, a)
この場合、 fの2番目の引数とgの1番目の引数は非常に類似しているため、コンマの類似性を上回ります。 関数のパラメーターの数を決定するには、完全に異なる場所にあるコンマの数を再カウントする必要があるため、このような配置は許容できません。
明らかに、ペア(カンマ、コンマ)の重みの単純な増加では問題を解決できません。関数自体のパラメーターは任意に大きく、したがって、任意の大きな重みを持つことができるからです。
したがって、トークンの類似度だけでなく、整列された行の構文構造も考慮する必要があります。
この場合、さまざまな言語が独自の、時には一意の構文を持っているという事実に関連する問題が発生し、ツールを可能な限り汎用的にしたいと考えています。
さらに、プログラムのテキストに位置合わせできない場所がある場合があります。 これらには、文字列定数とコメントが含まれます。 言語によってコメントの認識方法が異なります。たとえば、C \ C ++は//を使用し、RubyとPython #を使用します。 したがって、普遍性を高める唯一の方法は、言語の構文をすばやく記述する方法を使用することです。
文法
文法を使用する主なアイデアは、このツリーの各ノードが別のツリーの対応するノードと個別に整列するように式ツリーを構築することです。
前の例から取得した構造:
f ( a , b + c ) g ( b + c , a )
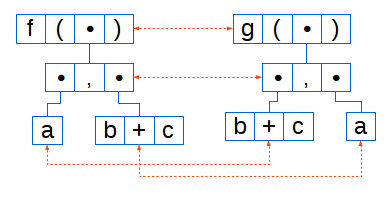
点線は、整列が発生するノードを示しています。
ツールのタスクにはコードの解釈が含まれていないため、プログラム内の各言語の構文の完全な説明を保存する必要はありません。 それどころか、アライメントに使用したいルールのみを記述するだけで十分です。 これらには、上記の関数引数、割り当て操作、ブラケット構造が含まれます。
文法の要件の中で、次の点も強調する必要があります。何らかの方法でトークンのシーケンスを文法で受け入れる必要があります。 この要件により、同様の言語に対して単一の文法を使用できます。
上記の構造を構築するために使用される文法は、Backus-Naurの形式で次のように記述できます。
main ::= expr expr ::= expr p | p | expr ',' expr p ::= '(' expr ')' |'(' ')' | any_token_except(',', ')', '(')
文法がその行を受け入れられない場合(たとえば、閉じ括弧がない場合)、認識出力は線形構造になります。
ツリー内のノードの選択は、各文法折りたたみ規則に対応していないことに気付くかもしれません;さもなければ、各トークンは別々のノードになります。 目的の構造を実現するために、アプリケーションがツリー内の新しいノードを形成するルールを文法で強調する必要があります。 この場合、これらのルールは次のようになります。
expr ::= expr ',' expr p ::= '(' expr ')'
開発中に、文法記述を使用して式ツリーを構築するLR-0パーサーが実装されました。 パーサーを構築するためのアルゴリズムの説明は、この記事の範囲外です;詳細については、本:Aho、Lam、Networks、Ulman-Compilersを参照してください。 原則、技術、ツール。
比較
式ツリーを受け取った後、トークンの類似性を考慮してトークンを調整する必要があります。 同様の問題は、ゲノムの研究における遺伝学でも発生します。 配列アラインメントは、DNA、RNA、またはタンパク質モノマーの2つ以上の配列を互いの下に配置して、これらの配列の類似領域を簡単に確認できるようにする方法です[ wiki ]。
バイオインフォマティクスでこの問題を解決する方法の1つは、動的プログラミングの使用です。これは、トークンを調整するタスクの基礎として採用しました。
すべての動的プログラミング問題と同様に、元の問題はより正確な問題に分割され、その解決策が再帰的に求められます。 この場合、文字列を揃える小さなタスクは、これらの文字列の接尾辞を揃えることです。 再帰的パスの結果として、文字列XおよびYのトークンのインデックスi、jを、これらの文字列の残りのサフィックスの最大の類似性の最大重みにマップするマトリックスが取得されます。
このマトリックス内の類似のペアの回復は難しくありません。
Ruby言語の2つの配列からトークンのペアを取得するための説明
def match(x,y,i,j) if(@cache[[i,j]] != nil) then return @cache[[i,j]][0]; end if x.size == i then @cache[[i,j]] = [0, 3]; return 0; end if y.size == j then @cache[[i,j]] = [0, 3]; return 0; end value = []; value[0] = x[i].cmp(y[j]) + match(x,y,i+1,j+1) value[1] = match(x, y, i ,j+1) value[2] = match(x, y, i+1,j ) max_value = 0; max_index = 0; index = 0; value.each{ |x| if x > max_value then max_value = x; max_index = index; end index += 1; } @cache[[i,j]] = [max_value, max_index]; return max_value; end def get_pairs(x,y, start = 0) @cache = {}; match(x, y, start, start); pairs = []; i = j = start; curr = @cache[[i,j]][1] while curr != 3 case curr when 0 then pairs += [[i,j]] if x[i].cmp(y[j]) > Float::EPSILON i+=1; j+=1; when 1 then j+=1; when 2 then i+=1; end curr = @cache[[i,j]][1] end return [@cache[[start, start]][0], pairs]; end
3行以上の整列の可能性を確保するために、整列が発生する配列の多くのペア間でチェーンが区別されます。

図は、整列が発生するコンマのチェーンを示しています。
トークンの割り当て
トークンは、対応するタイプのトークンに正規表現を適用しようとする一連の試行を使用して、文字列から抽出されます。 このシーケンスは、より具体的な正規表現が最初に適用され、次により一般的な表現が適用され、個々の文字が強調表示されるように配置する必要があります。 認識に成功すると、トークンには正規表現に一致するタイプが割り当てられます。 このプロジェクトは、文法の構築を簡素化し、アライメントの精度を向上させるために設計された型階層も実装します。
これまでのところ、2つの別々に取得されたトークンの類似性をどのように考慮するかという問題は提起されていません。 残念ながら、このタスクの厳密な正式な解決策を見つけることができなかったため、現在の実装におけるトークンの類似性は、主にヒューリスティックな方法によって決定されます。
特に、識別子の類似性は、識別子間のレーベンシュタイン距離とそれらの最大の長さの比として定義されます。
この場合のデフォルト値は次のとおりです。
1 max(Levenshtein_dist / max_length, 0.1) 0
トークン間の最小インデントを決定する
優れたプログラミングスタイルは、一部の言語構成要素のインデントです。
そのような場合には、関数の引数の小数点の後にスペースを入れたり、比較演算子の周りにスペースを入れたりすることが含まれます。
ただし、スペースを設定するオプションは言語によって異なるだけでなく、プログラマーによってスタイルも異なります。
f (a, b) //VS f(a, b)
この場合の自動インデントの設定を簡素化するために、トレーニングの可能性を追加することが決定されました。
多くの正しくフォーマットされた文字列が入力データとして使用されます。 トークンの連続するペアごとに、そのタイプとスペースの数が記憶されます。 次に、取得したデータを型階層に従って一般化します。
現在の実装
このドキュメントの執筆時点では、プログラムはSublime Text 3エディターのプラグインとして実装されています。
- ホットキーを使用した選択行の整列。
- 異なるインデントを持つ行の整列に対する保護。 (行揃えの前にインデントが正しいと想定されます。);
- 使用する言語に応じて、さまざまな文法オプション、トークン割り当て、およびタイプ階層のサポート。
- 執筆時点では、これまでに実装されているのは、99番目の標準のC言語とjavaの専門化だけです。
- ソースコードはRubyで記述され、オープンでGitHubで利用可能
将来の計画の中で、私は次のことに注意したいと思います。
- 特殊な文法のリストの拡張。
- 機械学習に基づいたアライメント中のスペースの最大数の決定。
- ホットキーを使用してトレーニングセットに行を追加する機能。
結果の例
例
最後の例では、文法レベルで型の説明の分離を使用しているため、同様の
と
は互いに整列していません。
switch (state) { case State.QLD: city = "Brisbane"; break; case State.WA: city = "Perth"; break; case State.NSW: city = "Sydney"; break; default: city = "???"; break; } // To switch (state) { case State.QLD:city = "Brisbane"; break; case State.WA :city = "Perth" ; break; case State.NSW:city = "Sydney" ; break; default :city = "???" ; break; }
// From types[:space] = nil; types[:quote] = nil; types[:regexp] = nil; types[:id] = nil; types[:spchar] = nil; // To types[:space ] = nil; types[:quote ] = nil; types[:regexp] = nil; types[:id ] = nil; types[:spchar] = nil;
// From long int a = 2; long long double b = 1; const int doubl = 4; // To long int a = 2; long long double b = 1; const int doubl = 4;
最後の例では、文法レベルで型の説明の分離を使用しているため、同様の
double
doubl
と
doubl
は互いに整列していません。
ご清聴ありがとうございました。