 aliexpressにはこのようなオークションがあります-Gaga Dealsにはゴミがありますが、かつては非常に興味深いオファーがありました。 彼らのアイデアは次のとおりです。
aliexpressにはこのようなオークションがあります-Gaga Dealsにはゴミがありますが、かつては非常に興味深いオファーがありました。 彼らのアイデアは次のとおりです。
- 1時間ごとの販売開始
- 製品の数には限りがあります。
- 誰が最初に起きてスリッパ
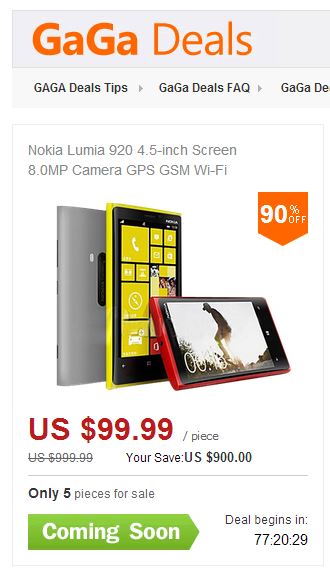
今年は90%の割引価格で最高級のスマートフォンを200〜300ドルで購入でき、昨年は100ドルでした。 各ポジションの5ピースのみがプレイされました。 もちろん、私は手動で勝とうとしましたが、何も起こりませんでした。 さて、ボットを書くことにしました...
私が最初に感じたのは、手動での一般的な動作です。 フィーダーで勝つためのすべての試みを記録してから、彼のレポートを詳しく調べました。 掘りながら、どのボットを書くべきか考えました。 彼は、ソケットを介して要求を送信し、応答を解析するコンソールアプリケーションを作成し始めました。 おいしいロットが最初にプレイされ、それらを手動で獲得しようとする試みはすべて失敗しましたが、私は動揺せず、トラフィックを分析し、分析したステップをプログラムしました。 その後、不必要なロットが誰にでも引き上げられました。 最後に、私は続けてキャプチャを見ました。 コンソールアプリケーションはすぐに削除されました。 クロームの拡張機能を書くことは私に起こりました。 目標は、キャプチャをすばやくクリックし、入力用のカーソルを置いてからクリックすることです。 この拡張機能には、 manifest.jsonとcontent.jsの 2つのファイルしか必要ありません。 マニフェストでは、 content.jsを注入されたスクリプトとして記述します。これですべてのページで実行されます。 そして、 document.querySelectorを使用して必要な要素を選択し、プログラムでそれらをクリックします。 ヘルパーが強打で動作し、問題なく不要な商品を注文し、必要なものがすでに販売されている間に呼び出すボット以上。 遅すぎる。
問題の一部は、サイトの逆レポートが実際のクロックより遅れていることでした。おそらく5分で1時間です。 さらに、2つのページを同時に更新すると、カウンターを2秒ずらして読み込むことができます。
したがって、ページを常に更新し、現在のカウンターを監視する必要があります。 いくつかのタブを開いて、 localstorage拡張機能を介した情報交換でボットを書き始めましたが、非アクティブなタブで絶え間ない問題が発生し、スクリプトが起動せず、 querySelectorが何も検出せず、選択したテキスト要素にテキストがありません-解析するものがありません そして、アクティブなページは常に機能していました。
問題は、目に見えないタブでブラウザを最適化することにあるようです。すべてのページを表示する必要があります。 メインページのすぐ内側に9つのフレームを作成しました。このページでは、カウンターのある製品ページが常に更新されていましたが、現在はフレームに直接アクセスできません。 奇妙な、同じドメイン上のすべてのページ、スクリプトは拡張機能のコンテキストから機能しますが、 フレームにアクセスしようとすると[。] .contentDocument-アメリカ先住民の小屋-「figs」と呼ばれます。 メインページの中国語がdocument.domain = "aliexpress.com"を第2レベルドメインに割り当てていることがわかりました。なぜ必要なのかわかりません。ページに他のフレームはありません。 取り戻そうとしましたが、ありませんでした。 ドメインレベルを下げることはできますが、上げることはできません。 割り当てたいのと同じドメインからページがロードされている場合でも。 私はどこでもドメインを第2レベルに変更する必要がありました-フレームに直接アクセスできました。 時間を解析し、最適な計算を行い、誰かがより良い時間で起動し、他のフレームを更新するまで触れませんでした-それは機能し、最高のカウンターは常にクリックする準備ができていました。 その後、フレーム数が4に削減されました。
不要なロットで拡張機能をデバッグし、「H」の時間になると、入力してEnterキーを押したキャプチャに安全に移動し、注文が自動的に発行されました。 すべてが準備され、私は新しい集会を待ち始めました。
次の抽選では、色や装備を選択するためのダイアログボックスの形で驚きが待っていましたが、これを見たことがなく、ボットがそれらで停止し、対応するステップがすぐに追加されました...
すべてが販売され、すべてが常に販売されています。 遅すぎる、何をすべきか? 中国とインドのキャプチャ認識サービスは、私より速く動作しません。 通常の認識プログラムを拡張機能にねじ込むことはできません。 私はすでにコンソールアプリケーションに戻ることを考えていたので、キャプチャ認識用のモジュールやライブラリを知っている職場で質問を投げました。 私はキャプチャをダウンロードする方法、URLを取得する場所を見始めました。 この機能で説明されているように、 キャプチャ画像は別のドメイン「checktoken1.alibaba.com」からロードされ、セッション識別子がURLで置換されます。つまり 、画像を更新するときは毎回番号が異なります。
そして、それは私を夜明けさせた
キャプチャは事前に認識できます。
どうやらこれは次のように機能します。リクエストがcaptchaサーバーに届くと、テキストと画像が生成されます。 テキストとセッションIDの最後の対応をデータベースに保存します。このようなセッションが存在し、captchaのあるページが開かれたことを確認することはありません。 そして、フォームを送信した後、ユーザーが入力したテキストとデータベースのテキストの対応がチェックされます。
どうやらこれは次のように機能します。リクエストがcaptchaサーバーに届くと、テキストと画像が生成されます。 テキストとセッションIDの最後の対応をデータベースに保存します。このようなセッションが存在し、captchaのあるページが開かれたことを確認することはありません。 そして、フォームを送信した後、ユーザーが入力したテキストとデータベースのテキストの対応がチェックされます。
次のように推測しました。 ホストで 、 checktoken1.alibabaのドメインchecktoken1.alibaba.comがブロックされました。 希望のIPを共同登録し、別のタブに画像をアップロードしました(これについては、画像が読み込まれていない可能性があり、2台目のコンピューターを使用する必要があるため、私は最も恐れていました)。 キャプチャフォームを更新しました。 古い値を入力し、フォームが機能し、キャプチャが有効であり、実験的にセッションのリセット値を15分に設定しました。
フレームでページを完成させ、別のドメインからテキストボックスと画像を作成し、ドローの約5分前にキャプチャを導入しました。もちろん、偽物がなく、他の邪悪なロボットがいなかった場合を除き、拡張機能は時計のように機能しました。
実際には、今ではブラウザなしでコンソールアプリケーションに戻ることができますが、ブラウザははるかに高速に動作しますが、母は怠けすぎて、そのように動作するときにもう一度書く理由を教えてくれませんでした。
2013年の秋に、aliexpress開発者はcaptchaで何かをしましたが、事前に満足が止まり、ボットが動作しなくなったことを認識していました。 手動でキャプチャを認識するヘルパーモードでは、注文が非常に遅くなります。
合計
大規模なものから、Nikon d5100 fotikは2013年5月に246ドル、Nokia lumia 800電話は2013年3月に136ドル、Blackberryボールド9900は136ドルで勝ちました。 偽物であるか、ボットが私のものよりもさらに悪いことで、トップオファーのいずれも勝つことができませんでした。 2〜4か月後、私はこれらのトップポジションを誰が購入したかを確認しました。バイヤーはロシア、ベラルーシ、ウクライナからのみでした。
GitHub拡張ソース