この記事では、「そして何が優れているか:dense_rank()またはmax()」という質問で私の研究について説明します。もちろん、少なくとも私にとっては、この研究が予期せぬ結果で終わった理由です。
背景:
だから、今仕事を探す必要がある星がありました。 各インタビューの前に、私は会社が何をしているか、彼らが私に申し出をした場合に何を学ぶかなどを理解するために、招待された会社を勉強します そして、ある素晴らしい瞬間に、ある素晴らしい会社から、PL / SQL開発者の地位へのインタビューへの招待状を受け取りました。 彼女について読んだ後、私は恋をしていてそこで働きたいと思った。 インタビューそのものに来て、インタビューの準備がすべて整ったその瞬間に、人々が会った、コーヒーを提供したなどの理由で始まっていなかったとき、私はすでにここで欲しいもの、本当に欲しいものを理解していました動作するように。
チームリーダーとのすべてのインタビューでは、簡単なリクエストを書くように依頼されました。それ以外の場合は、すべてが質問-回答モードになりました。
タスクは次のとおりです。
「オペレーションのテーブルがあります。オペレーションID、クライアントID、オペレーション日付、トランザクション量の4つの列があります。 「特定の期間の最大金額で各クライアントの最新のトランザクションを撤回する必要があります。」
そして、もちろん、私はそれが美しく効果的であるように書く方法を熱心に考え始めました。 そして、Oracleのほかに、テラデータも使用しました。その瞬間、私の脳はこのリクエストを発行しました。
非表示のテキスト
そして、テラデータの場合、これは機能しますが、神託はありません。 そして、Oracleには「資格」がないことをはっきりと覚えて、次のようなものを紙に書きました。
/*id - oper_id, id - client_id, - input_date, - amount*/ select t.* , max(t.amount) over (partition by t.client_id) as m_a from some_table t qualify oper_id = max(t.oper_id) over (partition by t.client_id) where m_a = amount
非表示のテキスト
select t.* from some_table t where amount = max(t.oper_id) over (partition by t.client_id)
「なぜmax()が使用され、dense_rank()ではなかったのか?」という質問がありましたが、正確に答えたものを覚えていませんが、「max()をより頻繁に使用でき、多かれ少なかれdense_rank()とは異なり、彼が私に返すものを想像してください。 インタビューについてはこれ以上説明しません。もちろん、彼らは私を拒否しました。 その後、自宅で、すべてを分析し、間違いを理解しようとして、そこで働きすぎて心配していたという結論に達しました。そうでなければ、インタビュー中に私の頭で起こっていた混乱を説明できません。 生徒が幼稚園からこっそり愛している女の子と話をしようとするのは感覚に似ていましたが、これらの試みはますます厄介な立場に置かれました。 同じように、落ち着いて適切に見えることを試みて、私は自分が価値のない専門家であることを証明しました。 一般に、このような問題を解決する場合は、dense_rank()またはmax()を使用する方が良いと判断することにしました。
リサーチ
私が書くことすべてを自分の目で見て、自分の手で触りたいなら、テスト用のデータを作成するための一連のスクリプトを用意しました。
非表示のテキスト
/* */ create table habr_test_table_220414 ( oper_id number, client_id number, input_date date, amount number, constraint habr_test_table_220414_pk primary key (oper_id) ); grant all on habr_test_table_220414 to public; /* , oper_id - */ create sequence habr_test_sequence_220414 increment by 1; grant all on habr_test_sequence_220414 to public; /* , , oper_id */ create trigger habr_test_trigger_220414 before insert on habr_test_table_220414 for each row begin :new.oper_id := habr_test_sequence_220414.nextval; end; /* */ /* , 10- */ /* , cost = 3, 20000 , */ /* - counter */ declare counter number := 10000; i number := 0; begin loop insert into habr_test_table_220414 ( client_id , input_date , amount ) values ( trunc (dbms_random.value (1, 11)) , to_date(trunc(dbms_random.value(to_char(date '2013-01-01','j'),to_char(date '2013-12-31','j'))),'j') , trunc (dbms_random.value (1, 100000)) ); exit when (i = counter); i := i + 1; end loop; commit; /* , */ /* :*/ insert into habr_test_table_220414 select * from habr_test_table_220414; commit; /* id */ end;
これで、テストデータが作成されました。実際には、クエリ自体を開始します。 20,000行を削減しないために、特定の期間に選択を制限しません。どの方法がより効果的で効率的かを理解することが重要であるためです。
後で追加できます。where input_date between to_date('01.01.2013','dd.mm.yyyy') and to_date('01.05.2013','dd.mm.yyyy')
max()を使用したクエリ
select * from ( select c.* , max(c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/ from ( select t.* , max(t.amount) over (partition by t.client_id) as m_a/*max_amount*/ from habr_test_table_220414 t ) c where c.m_a = c.amount ) where m_o = oper_id;
dense_rank()を使用したクエリ
select * from ( select c.* , dense_rank() over (partition by c.client_id order by c.oper_id desc) as m_o/*max_operation*/ from ( select t.* , dense_rank() over (partition by t.client_id order by t.amount desc) as m_a/*max_amount*/ from habr_test_table_220414 t ) c where c.m_a = 1 ) where m_o = 1;
これらのクエリの予備計画(pl / sql開発者から取得):
最大:
非表示のテキスト 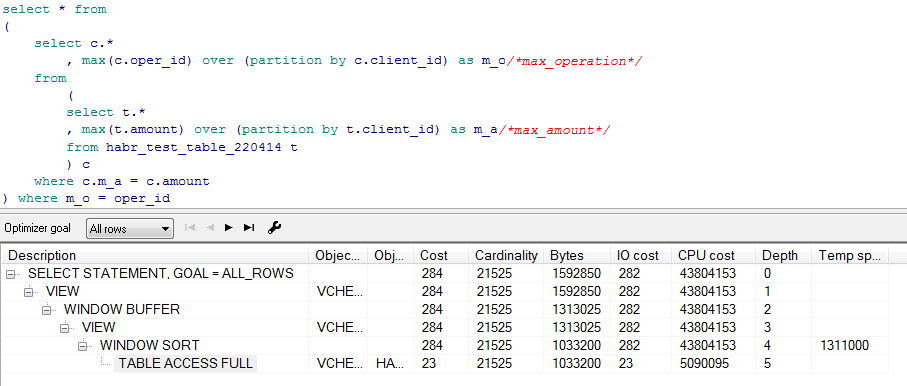
Dense_rank:
非表示のテキスト 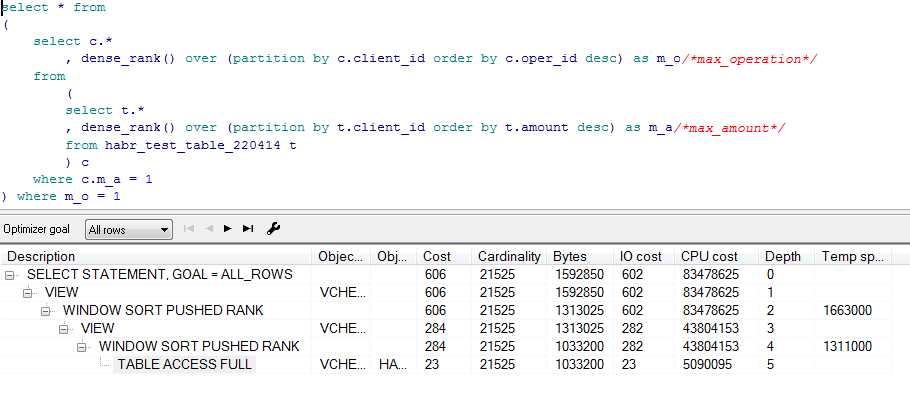
しかし、これらは予備的な計画であり、実際の計画はSQLTUNEユーティリティを使用して取得されます。
準備:
これらの実際の計画は次のようになります。
/* max()*/ DECLARE my_task_name varchar2(30);my_sqltext clob;rep_tuning clob; BEGIN Begin DBMS_SQLTUNE.DROP_TUNING_TASK('my_sql_tuning_task_max'); exception when others then NULL; end; MY_SQLTEXT:= 'select * from ( select c.* , max(c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/ from ( select t.* , max(t.amount) over (partition by t.client_id) as m_a/*max_amount*/ from habr_test_table_220414 t ) c where c.m_a = c.amount ) where m_o = oper_id'; MY_TASK_NAME:=DBMS_SQLTUNE.CREATE_TUNING_TASK(SQL_TEXT => my_sqltext, TIME_LIMIT => 60, -- TASK_NAME =>'my_sql_tuning_task_max', DESCRIPTION=> my_task_name , SCOPE => DBMS_SQLTUNE.scope_comprehensive); begin DBMS_SQLTUNE.EXECUTE_TUNING_TASK('my_sql_tuning_task_max'); exception when others then null; end; END; /* dense_rank()*/ DECLARE my_task_name varchar2(30);my_sqltext clob;rep_tuning clob; BEGIN Begin DBMS_SQLTUNE.DROP_TUNING_TASK('my_sql_tuning_task_dense'); exception when others then NULL; end; MY_SQLTEXT:= 'select * from ( select c.* , dense_rank() over (partition by c.client_id order by c.oper_id desc) as m_o/*max_operation*/ from ( select t.* , dense_rank() over (partition by t.client_id order by t.amount desc) as m_a/*max_amount*/ from habr_test_table_220414 t ) c where c.m_a = 1 ) where m_o = 1'; MY_TASK_NAME:=DBMS_SQLTUNE.CREATE_TUNING_TASK(SQL_TEXT => my_sqltext, TIME_LIMIT => 60, -- TASK_NAME =>'my_sql_tuning_task_dense', DESCRIPTION=> my_task_name , SCOPE => DBMS_SQLTUNE.scope_comprehensive); begin DBMS_SQLTUNE.EXECUTE_TUNING_TASK('my_sql_tuning_task_dense'); exception when others then null; end; END; /* , */ /* , */
非表示のテキスト
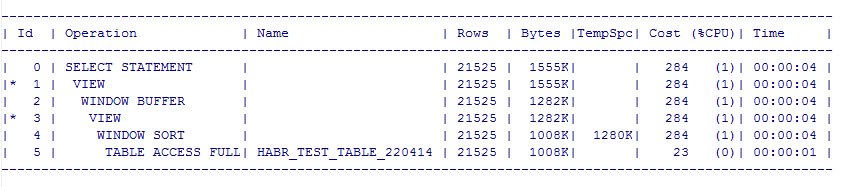
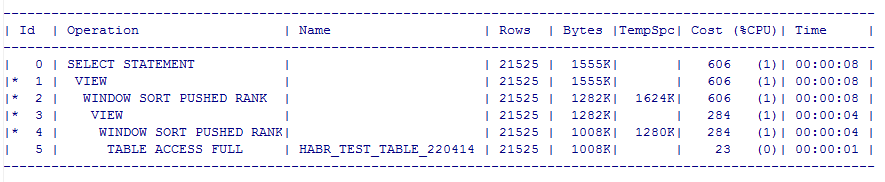
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK('my_sql_tuning_task_max') FROM DUAL;
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK('my_sql_tuning_task_dense') FROM DUAL;
SQLTUNEは、実際の計画に加えて、スクリプトの最適化に関する推奨事項も提供します。この場合、統計の収集を推奨しますが、1つのプレートがあるため、クエリは同じ条件になります。
予備結果
これらのすべての操作の後、この問題を解決するとき、max()がdense_rank()の2倍速く動作し、プロセッサ時間の半分を消費することは、私にとって明らかです。 まあ、それはプランや他のものなしで理解できるので、max()は最大のものを検索するだけであり、dense_rank()はまずソートしてから番号付けするだけです。しかし、それが記事を書くきっかけになったわけではありません。
突然の
最初にテスト用のテーブルに記入するプロセスで、記事のスクリプトを見つけ出し、初めてすべてがほぼ手動で行われ、実験テーブルのステータスを確認するorder by
、
order by
リクエストを使用し
order by
。
非表示のテキスト
その後、 /* 10 */ insert into habr_test_table_220414...; .... .... insert into habr_test_table_220414...; commit; select * from habr_test_table_220414 t order by t.client_id; /* :*/ insert into habr_test_table_220414 select * from habr_test_table_220414; commit; select * from habr_test_table_220414 t order by t.client_id; /* */
order by
を削除せずに、このリクエストを「max()でリクエスト」という最終状態に変更
order by
。
起こったことは次のとおりです。
select * from ( select c.* , max(c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/ from ( select t.* , max(t.amount) over (partition by t.client_id) as m_a/*max_amount*/ from habr_test_table_220414 t order by t.client_id ) c where c.m_a = c.amount ) where m_o = oper_id
後で「dense_rank()を使用したクエリ」を作成し、プランの比較を開始しましたが、max()を使用したクエリでこの不運な
order by
気付き、
order by
を削除し
order by
、すでにコストを確認し、覚えていました。 そして、
order by
でmax()を使用したリクエストでコストを見たとき
order by
非常に驚きました:
予備計画 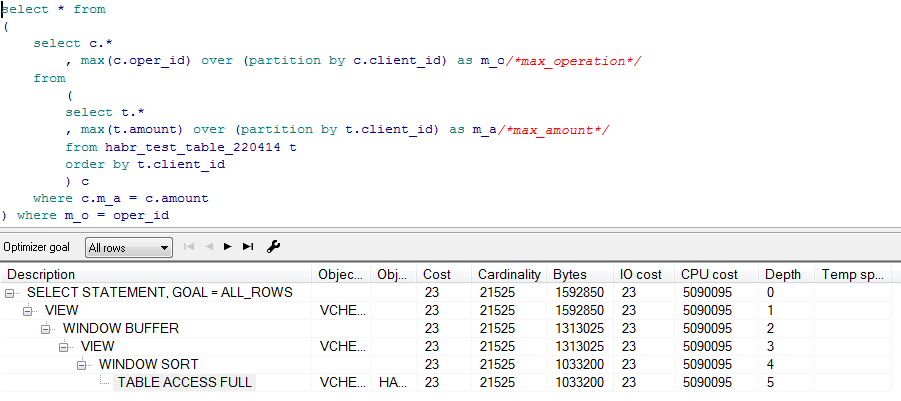
SQLTUNEからの実際の計画 
とにかく、私は非常に驚いたと言うために-何も言わないために...どのようにそれが起こりましたか? リクエストを10倍高速化して
order by
はなぜですか? トレースで答えを見つけることにしました。 これは別の記事のトピックであり、このプロセスの説明を含む記事はWorld Wide Webで簡単に見つけることができるため、Oracleでトラックを撮影する方法を正確には書きません。 トレースに使用した一連のスクリプトとそのような記事へのリンクのみを提供しますが、それは長い間見つけました。
非表示のテキスト
トラックでは、リクエストを実行するときのOracleのアクションを説明する部分に興味があります。 トレースの有効化に関する記事へのリンク
alter system set timed_statistics=true; alter session set tracefile_identifier='test_for_habr_220414'; alter session set events '10046 trace name context forever, level 12'; select * from ( select c.* , max(c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/ from ( select t.* , max(t.amount) over (partition by t.client_id) as m_a/*max_amount*/ from habr_test_table_220414 t order by client_id ) c where c.m_a = c.amount ) where m_o = oper_id; alter session set events '10046 trace name context off'; select value from v$parameter p where name='user_dump_dest'; /* tkprof*/ /* 'test_for_habr_220414'*/
非表示のテキスト
select * from ( select c.* , max(c.oper_id) over (partition by c.client_id) as m_o/*max_operation*/ from ( select t.* , max(t.amount) over (partition by t.client_id) as m_a/*max_amount*/ from habr_test_table_220414 t order by client_id ) c where c.m_a = c.amount ) where m_o = oper_id call count cpu elapsed disk query current rows ------- ------ -------- ---------- ---------- ---------- ---------- ---------- Parse 1 0.01 0.00 0 1 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 1 0.03 0.02 0 84 0 10 ------- ------ -------- ---------- ---------- ---------- ---------- ---------- total 3 0.04 0.03 0 85 0 10 Misses in library cache during parse: 1 Optimizer mode: ALL_ROWS Parsing user id: SYS Rows Row Source Operation ----- --------------------------------------------------- 10 VIEW (cr=84 pr=0 pw=0 time=28155 us cost=23 size=1592850 card=21525) 20 WINDOW BUFFER (cr=84 pr=0 pw=0 time=28145 us cost=23 size=1313025 card=21525) 20 VIEW (cr=84 pr=0 pw=0 time=21628 us cost=23 size=1313025 card=21525) 22010 WINDOW SORT(cr=84 pr=0 pw=0 time=24393 us cost=23 size=1033200 card=21525) 22010 TABLE ACCESS FULL HABR_TEST_TABLE_220414(cr=84 pr=0 pw=0 time=5172 us cost=23 size=1033200 card=21525)
まとめ
このことから、予備計画と実際の計画の両方が間違っていないことがわかります。キャッチはないようで、10倍の加速を楽しむことができます。 そうですか?
PS私はまだこの質問に答えることができませんでしたし、まだ注文の助けを借りてリクエストを本当に加速できるとは信じていません。 私はこの瞬間を見つけようとし続けます。 そして、神託の隠された秘密が私たちに明らかにされるように!
PPSご清聴ありがとうございました! あなたが私と一緒にテストを実行した場合-特にそれがいくつかの銀行の製品である場合、自分のためにベースをきれいにすることを忘れないでください。
非表示のテキスト
drop trigger habr_test_trigger_220414; drop sequence habr_test_sequence_220414; drop table habr_test_table_220414;