
なんで?
ディスクサブシステムはサーバーの重要なサブシステムの1つであり、コンテンツの配信速度やデータベースの応答速度など、ディスクサブシステムの負荷レベルに依存することが非常に多くあります。 これは主にメールまたはファイルサーバー、データベースサーバーに適用されます。 一般に、ディスクパフォーマンスインジケータを監視する必要があります。 ディスクサブシステムのパフォーマンスグラフに基づいて、コックが突っ込む前に容量を増やす必要があるかどうかを判断できます。 はい。開発者の作業がワークロードのレベルに影響を与えるため、リリースごとに一見するだけで役立ちます。
カットの下で、監視と設定方法について。
依存関係:
監視は、zabbixエージェントと2つのユーティリティ:awkおよびiostat(sysstatパッケージ)を介して実装されます。 デフォルトでawkにディストリビューションが付属している場合は、 sysstatパッケージとともにiostatをインストールする必要があります (ここではSebastien Godardと同僚に感謝します)。
既知の制限:
監視には、バージョン9.1.2以降のsysstatが必要です。 「iostatの拡張統計にr_awaitおよびw_awaitフィールドを追加」という非常に重要な変更があります。 そのため、CentOSなど、一部のディストリビューションでは、sysstatのわずかに「安定した」バージョンであり、機能が少ないバージョンでは注意が必要です。
zabbixのバージョン(2.0または2.2)から開始する場合、質問は基本的なものではなく、両方のバージョンで機能します。 1.8では機能しません。 低レベル検出を使用しました。
機会 (実用性が低下するため、純粋に主観的):
- 監視対象ノード上のブロックデバイスを自動検出するための低レベル検出(以下、単にLLD)。
- ブロックデバイスの使用率(%)-デバイスの合計負荷を追跡するための便利なメトリック。
- レイテンシーまたは応答性-一般的な応答性と読み取り/書き込み操作の応答性の両方が利用可能です。
- キューサイズ(リクエスト)と平均リクエストサイズ(セクター)-負荷の性質とデバイスの負荷の程度を評価できます。
- 人間が読めるキロバイト単位のデバイスへの現在の読み取り/書き込み速度。
- 実行のためのキューイング時に組み合わされた読み取り/書き込み要求の数(1秒あたり)。
- iops-1秒あたりの読み取り/書き込み操作の値。
- 平均リクエストサービス時間(svctm)。 一般的に、これは非推奨であり、開発者は長い間それを削減することを約束しますが、すべての同じ手が届きません。
一般に、ご覧のとおり、iostatにあるすべてのメトリックはここから入手できます(このユーティリティに不慣れな方は、man iostatを調べることを強くお勧めします)。
利用可能なチャート:
グラフはデバイスごとに描画され、LLDは正規表現「(xvd | sd | hd | vd)[az]」に該当するデバイスを検出するため、ドライブの名前が異なる場合は、適切な変更を簡単に加えることができます。 このような規則は、他のパーティション、LVMボリューム、MDRAIDアレイなどの親になるデバイスを検出するために行われます。 一般的に、収集しすぎないようにします。 少し気が散るので、グラフのリスト:
- ディスク待機-デバイスの応答性(r_await、w_await)。
- ディスクマージ-キュー内のマージ操作(rrqm / s、wrqm / s);
- ディスクキュー-キューの状態(avgrq-sz、avgqu-sz);
- ディスクの読み取りと書き込み-デバイスへの現在の読み取り/書き込み値(rkB / s、wkB / s);
- ディスク使用率-ディスク使用率とIOPS値(%util、r / s、w / s)-使用率のジャンプを非常によく追跡し、読み取りまたは書き込みによって呼び出されたことを意味します。
アナログと違い:
zabbiksには、同様の監視用のボックスオプションがあります。これらはキーvfs.dev.readおよびvfs.dev.writeです。 それらは優れており、うまく機能しますが、iostatよりも情報量が少なくなります。 たとえば、iostatには遅延や使用率などのメトリックがあります。
Michael Nomanからも同様のテンプレートがありますが、私の意見では、違いは1つだけです。古いバージョンのiostatに焦点を合わせています。
入手先:
したがって、監視は、エージェントの構成ファイル、データを収集/受信するための2つのスクリプト、およびWebインターフェースのテンプレートで構成されます。 これらはすべてGithubのリポジトリで利用できるため、利用可能な任意の方法(git clone、wget、curlなど)で監視対象のマシンにダウンロードし、次の項目に進みます。
設定方法:
- iostat.conf-このファイルの内容は、zabbixエージェント設定ファイルに配置するか、メインエージェント設定のIncludeオプションで指定された設定ディレクトリに配置する必要があります。 Vobschemはパーティーポリシーに依存しています。 2番目のオプションを使用します。カスタム設定には別のディレクトリがあります。
- scripts / iostat-collect.shおよびscripts / iostat-parse.sh-これら2つの作業スクリプトは、/ usr / libexec / zabbix-extensions / scripts /にコピーする必要があります。 ここでは、便利な配置を使用することもできますが、この場合、iostat.confで定義されたパラメーターのパスを修正することを忘れないでください。 それらが実行可能であることを確認してください(mode = 755)。
これですべての準備が整ったので、エージェントを起動して監視サーバーに移動し、コマンドを実行します(agent_ipを置き換えることを忘れないでください)。
# zabbix_get -s agent_ip -k iostat.discovery
したがって、監視サーバーからiostat.confが読み込まれて情報を提供することを確認すると同時に、LLDが機能していることを確認します。 応答は、検出されたデバイスの名前を含むJSONを返します。 答えが得られなかった場合、何かが間違っていました。
また、zabbixサーバーがエージェント(iostat.collect)による一部のアイテムの実行を待たないという点もあります。 これを行うには、タイムアウト値を増やします。
Webインターフェースの構成方法:
これで、iostat-disk-utilization-template.xmlテンプレートが残ります。 Webインターフェースを介して、テンプレートセクションにインポートし、ホストに割り当てます。 ここではすべてが簡単です。 約1時間待機するようになりました。この時間はLLDルールで設定されます(構成可能)。 または、Iostatセクションで、監視対象のホストの最新データを確認できます。 値が表示されたら、グラフセクションに移動して最初のデータを見ることができます。
最後に、localhost))))からのグラフの上位3つのスクリーンショット:
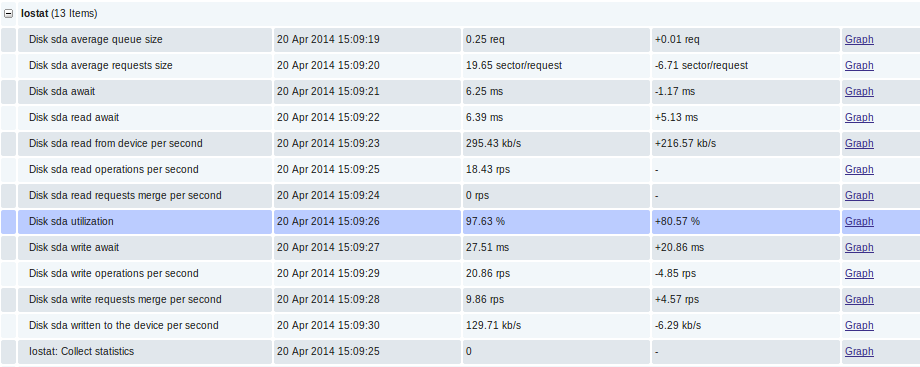
最新データの直接データ:
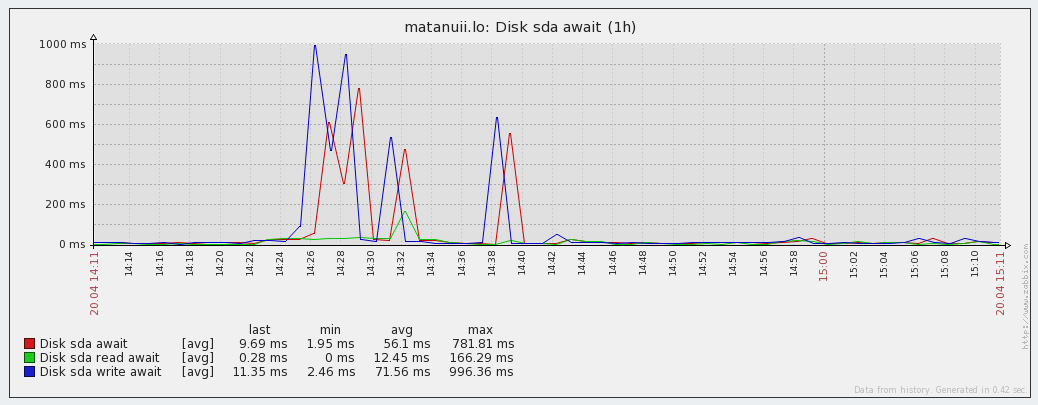
応答性チャート(遅延):
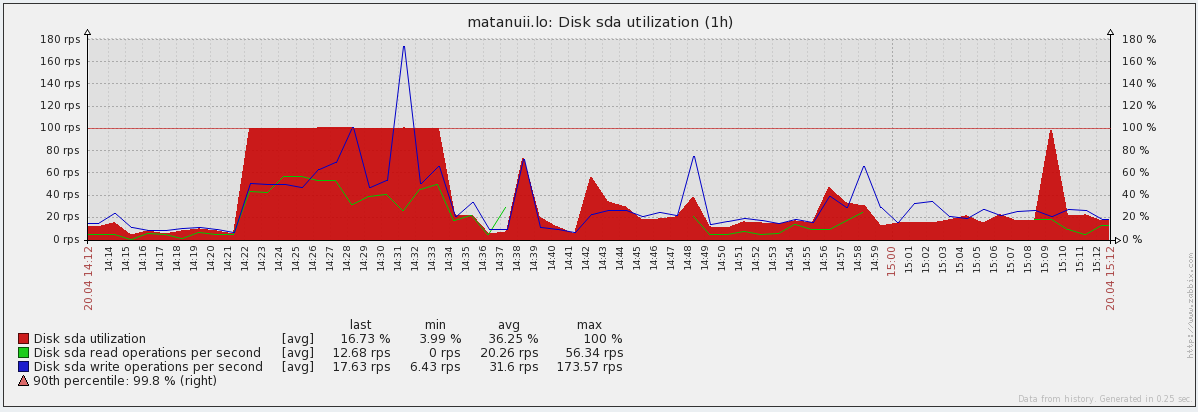
廃棄スケジュールとIOPS:
それだけです、ご清聴ありがとうございました。
まあ、伝統によれば、この機会を利用して、私はセルゲイ・フェドロフ(アレクシーヴィッチ)に敬意を表します:)