もちろん、自然言語によるコンピューターとの本格的なコミュニケーションの夢は、まだ人工知能の夢と同じくらい本格的な実装にはほど遠いです。 ただし、現在いくつかの結果があります。自然言語のテキストで必要なオブジェクトを見つけ、それらの間のリンクを見つけ、さらに処理するために形式化された形式で必要なデータを提示するようにマシンに教えることができます。 Yandexはこの技術をかなり長い間使用しています。 たとえば、特定の場所で特定の時間に会うという提案が書かれた手紙を受け取った場合、特別なアルゴリズムが独立して必要なデータを抽出し、カレンダーに入力するよう提案します。
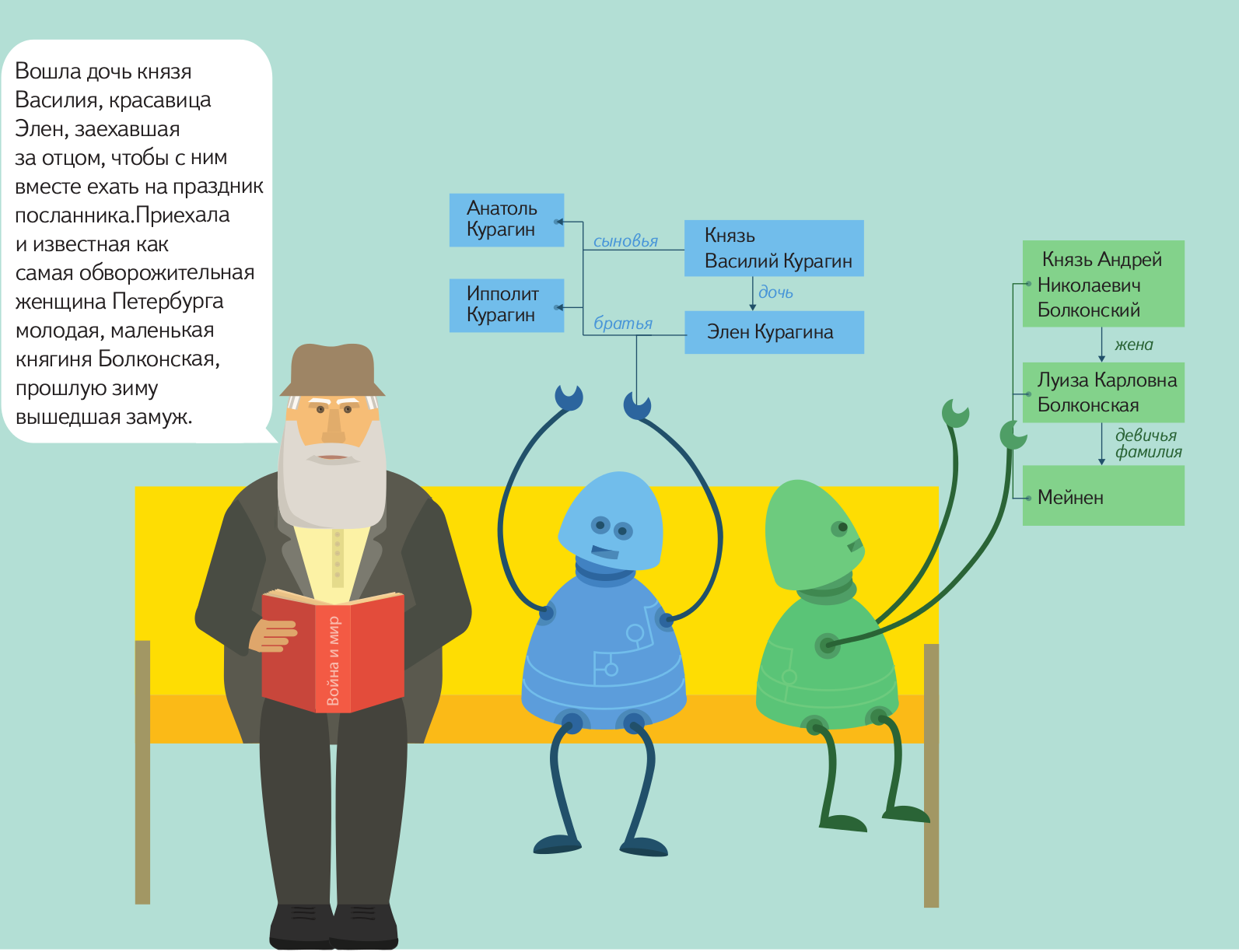
すぐにこのテクノロジーをオープンソースに提供して、誰でもそれを使用して開発できるようにすることで、人とコンピューター間の自由なコミュニケーションの明るい未来を近づけることを計画しています。 ソースコードの公開の準備はすでに始まっていますが、このプロセスは私たちが望むほど速くなく、おそらく今年の終わりまで続くでしょう。 この間、私たちは製品について可能な限り多くのことを伝えようとします。製品については、一連の投稿を開始します。その中で、デバイス構造とその動作原理について説明します。
この技術はTomita-parserと呼ばれ、一般的に誰でも使用できます。バイナリファイルはダウンロード可能です。 ただし、この技術を使用する前に、正しく調理する方法を学ぶ必要があります。
GLRアルゴリズム
このツールは、 GLT解析アルゴリズム(一般化された左から右へのアルゴリズム)の作者である日本の科学者である富田勝にちなんで名付けられました。 1984年に、彼はこのアルゴリズムの実装について説明し、自然言語のテキストを効果的かつ正確に分析するタスクを設定しました。 いくつかの点で、GLRアルゴリズムはLR解析アルゴリズムの拡張バージョンです。 ただし、LRアルゴリズムは、かなり厳密に決定論的なプログラミング言語で記述されたテキストの分析を目的としており、自然言語では機能しません。 富田は、スタックを並列化することでこの問題を解決しました。これにより、テキストの特定のセクションのさまざまな解釈を検討できました。異なる解釈の可能性が生じるとすぐに、スタックが分岐します。 そのような順次分岐は複数存在する可能性がありますが、分析中にエラーのある分岐は破棄され、結果は最長のチェーンになります。 同時に、このアルゴリズムは作業の結果をリアルタイムで提供します。テキストの奥深くに移動するため、他の自然言語処理アルゴリズムにはこの機能がありません。
ただし、テキストだけを完全に分析して構造化された情報を抽出するには、アルゴリズムだけでは十分ではありません。 パーサーが理解できる必要な辞書を接続するには、処理されたテキストの言語の形態と構文を考慮する必要があります。 これらはすべて、プログラミング経験のある言語学者のみが利用できました。 Tomita-parserは、アルゴリズムを使用して作業を単純化することを目的として開発されました。 辞書と文法を作成するための簡単な構文がコンパイルされ、ロシア語とウクライナ語の形態を扱うことが考え出されました。 さて、ロシア語のデバイスの十分な永続性と理解により、ほとんどすべての人が構文を理解し、独自の目的のためにパーサーを準備することができます。 もちろん、言語学の深い知識と正規表現を扱う能力は、無条件のプラスになりますが、必須条件ではありません。
富田はどこで使用されていますか?
現在まで、トミタは4つのYandexサービスで使用されています。
- メール。 すでに上記で述べたように、何らかの形で会合に招待された手紙を受け取った場合、富田はこの会合がいつどこで開催されるかを決定し、それをカレンダーに追加することを提案します。 航空券の場合も同様です。
- ニュース。 このサービスでは、富田はニュース記事を自動的にマッピングおよびグループ化するのに役立ちます。 メモに国名、都市名、または記載されたイベントが発生した場所の完全な住所が記載されている場合、富田はこの情報を強調表示し、地図上のポイントにメモを添付します。
- オート
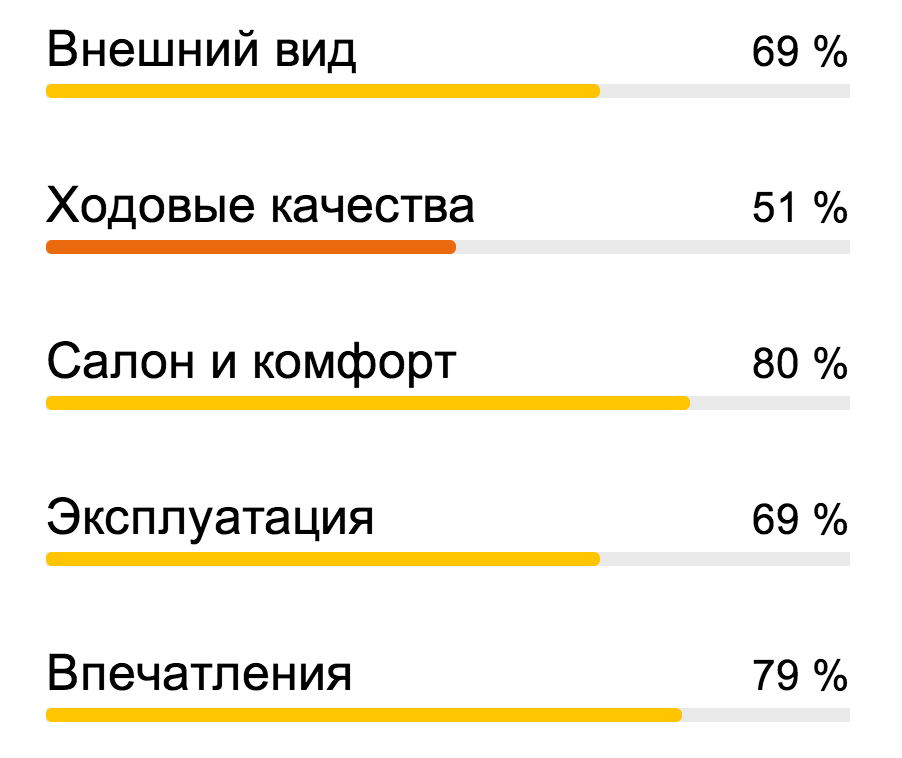 Yandex.Autoサービスは、さまざまなサイトの車に関するレビューを集約します。独自のレビューをそこに残すことができます。 富田はこれらのレビューを分析し、自動車のさまざまな特性に関するステートメントの感情的な色付けを評価します。 これらのデータに基づいて、外観、運転性能、インテリアと快適性、操作性、経験などの特性の評価がまとめられます。
Yandex.Autoサービスは、さまざまなサイトの車に関するレビューを集約します。独自のレビューをそこに残すことができます。 富田はこれらのレビューを分析し、自動車のさまざまな特性に関するステートメントの感情的な色付けを評価します。 これらのデータに基づいて、外観、運転性能、インテリアと快適性、操作性、経験などの特性の評価がまとめられます。 - 仕事。 Yandex.Auto Jobsのように、労働者の検索でさまざまなサイトから広告を収集します。 通常、これらは任意の形式で構成されます。 富田はこれらのテキストを分析し、求職者と労働条件の要件を特定し、それらを正式化します。これにより、ユーザーは求人を検索するときに求人をフィルタリングできます。
実際にどのように機能するか
最小限の構成では、入力のパーサーには、分析されたテキスト自体、および辞書と文法が与えられます。 辞書の量と文法の複雑さは、分析の目的に依存します。それらは非常に小さい場合も、大きい場合もあります。 文法ファイルは、Tomit-parserの内部言語/形式で書かれたテンプレートで構成されています。 これらのパターンは、テキストで発生する可能性のある単語のチェーンを一般化された形式で記述します。 さらに、最終的な結論で抽出された事実を提示する方法は、文法によって決まります。
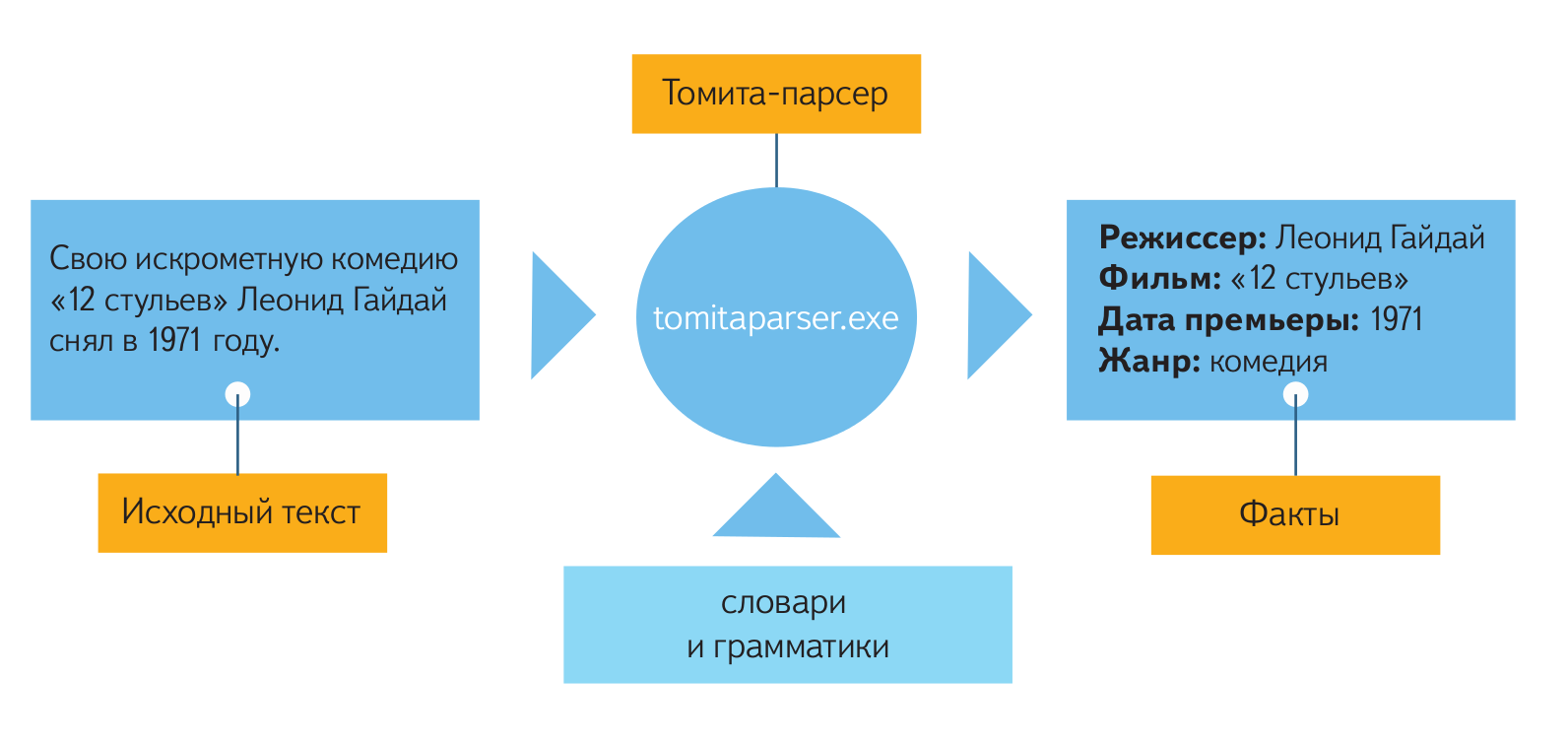
辞書には、文法分析プロセスで使用されるキーワードが含まれています。 このディクショナリの各記事は、共通のプロパティによって結合された多くの単語とフレーズを定義しています。 たとえば、「ロシアのすべての都市」。 文法では、「ロシアの都市です」というプロパティを使用できます。 単語またはフレーズは、リストで明示的に指定することも、目的のチェーンを説明する文法を示すことで「機能的に」指定することもできます。
以下は、自然言語のテキストから抽出し、監督の名前、映画の名前とジャンルを互いに結び付けるのに役立つ文法です。 テキストで使用できるさまざまなジャンルと形式をリストした辞書もあります。
文法
#encoding "utf-8" #GRAMMAR_ROOT S PersonName -> Word<h-reg1, nc-agr[1]> Word<h-reg1, nc-agr[1]>*; // - , FilmName -> AnyWord<h-reg1, quoted>; // - FilmName -> AnyWord<h-reg1, l-quoted> AnyWord* AnyWord<r-quoted>; // , GenreChain -> Word<kwtype=genre_type> interp (Film.Genre); // - , genre Film -> ''; // Descr -> GenreChain | Film; // Director -> PersonName interp (Film.Director); // PersonName Director Film S -> Descr Director<gram=""> FilmName interp (Film.Name::not_norm); // - . , : " "
語彙
// ( genre), - genre_type "_1" { key = { " " agr=gnc_agr } // key = { " " agr=gnc_agr } // key = { " " agr=gnc_agr } mainword = 2 // lemma = "" //, } genre_type "_2" // { key = "" lemma = "" // } genre_type "_" { key = { " " gram={",", word=2} } key = "" | "" lemma = " " } genre_type "" { key = "" lemma = "" }
例からわかるように、文法では、最初に監督の名前と姓を、数字と大文字小文字で調整された1つ以上の大文字の単語で構成される単語のチェーンとして決定します。 次に、映画の名前を識別する方法を示します。1つ以上の単語を引用符で囲み、最初の単語は大文字で始まる必要があります。 映画のジャンル所属を判断するために、特別に用意されたジャンルの辞書を参照します。 辞書には、文法が参照するタイプでマークされた記事が含まれています。 各記事は、タイトル、キー、および補題で構成されます。 1つまたは複数のキーは、テキストに1つまたは別の概念を表示する方法を反映しますが、キー内の単語間の調整オプションを指定することもできます。 一方、補題は、正規化中にすべてのキーが削減される形式であるため、すべてがファクトとともにファイナルテーブルに表示されます。

映画についてのテキストの同じ分析を独自に実行しようとすることができます。 リンク別アーカイブには、作業に必要なすべてのファイルと、当社がコンパイルしたテンプレートに適したオファーの例が含まれています。
プロジェクトで富田を使用する方法は?
Windows、OS X、およびLinuxのバイナリパッケージの形で、Tomitaパーサーが利用可能になりましたが、独自の文法と辞書を自分で理解することはそれほど簡単ではありません。 そのため、一連のトレーニングビデオを用意しました。 次の投稿では、これらの教訓に基づいて富田を操作する構文と原則についてもう少し詳細に説明しようとします。 さて、最もせっかちで永続的な人は、 ビデオとドキュメントを見ることができます 。