現在関連しているのは、特定の知識分野でオントロジーを構築するタスクです。 明らかに、大規模な業界オントロジーの構築は、高いリソースコストを必要とする複雑な問題です。 いずれにせよ、一般的なオントロジーの構築における特定の段階は、対応するシソーラス、用語オントロジーの構築です。

本論文では、用語の自然階層のネットワークを構築するための方法論を提案します。これは、対応する用語オントロジーの形成の基礎である「準オントロジー」と見なすことができます。 用語の自然な階層のネットワークは、テキストの情報的に重要な要素に基づいており、単語やフレーズをサポートしています。その識別方法は[1、2]に記載されています。 このような要素を使用することにより、検索イメージを形成し、一般的なオントロジーをさらに構築するための基礎として知識の全領域をカバーすることができます。 用語の自然な階層を構築するための補助的な語句は、判別力などの特性を考慮して選択されます。 ただし、シソーラスとオントロジーを構築するには、このプロパティだけでは不十分です。 判別力の低い単語、特に選択したサブジェクトエリアで最も頻繁に使用される単語(たとえば、情報検索コーパスの「情報」、「検索」、「検索」など)は、検討中のタスクにとって重要です。
自然用語階層のネットワーク(SEIT)の形成は、対応する方向のテキストコーパスのコンテンツに基づいています。 この場合の用語の階層の「自然さ」は、セマンティック分析の特別な方法からのネットワークを形成するときの拒否として理解されます。 このようなネットワークのすべての接続は、統計的に有意な量のテキスト本文から抽出された単語やフレーズの自然な使用によって決定されます。 完全に自動的に作成された自然用語階層のネットワークは、用語オントロジーの自動化された形成の基礎と見なすことができます。
本論文で検討する用語の自然階層のネットワークを形成するためのアルゴリズムは、元のテキストコーパスの予備処理、用語の定義とソート、必要な数の最も重要な(コンパクト化された水平可視性グラフ[3]の最大ノード)の選択、SEITの構築、そのディスプレイ。 これらの手順をより詳細に検討してください。
1.最初の段階で、元のテキスト本文が選択されます。 そのようなコーパスの例として、550エントリの情報検索(rubric cs.IR)のトピックに関する2007-2010年の電子プレプリントarXiv(www.arxiv.org)の注釈の配列を以下で検討します。
このようなテキストコーパスの前処理には、レコードのテキスト部分の選択、非テキスト文字の除外、およびスタンプが含まれます。
2.第2段階では、テキストコーパスの個々の単語に、その「識別力」、つまりTFIDFの評価が割り当てられます。TFIDFは、正規形では、テキストフラグメントの単語の頻度(用語頻度)の逆数の2進対数による積に等しくなりますこの単語が見つかったテキストの断片(逆文書頻度)[4]。
3-4。 前のステップと同じことが実行されますが、2ワード(バイグラム)と3ワード(トリグラム)のフレーズに対してのみ実行されます。
5.用語のシーケンスとTFIDFによる重み値について、コンパクト化された水平可視性グラフ(CHVG)が構築され[1、2]、このアルゴリズムを使用して単語の重み値が再決定されます。 この手順を使用すると、テキストコーパスの一般的な主題にとって非常に重要な、高い識別力を持つ用語、および高頻度の用語に加えて、将来的にも考慮することができます。 その後、すべての用語は、対応するCHVGノードの計算された重み値の降順でソートされます。
いわゆるストップディクショナリの用語は、さらなる分析の対象ではありません。 これは、原則として、テキストのコンテンツで重要な役割を果たさないサービスワードの固定セットです。
6.必要なSEITの量(数N)は専門家の方法で決定され、その後、CHVGで最も高い重み値を持つ単一の単語、バイグラム、およびトリグラム(合計N + N + N要素)の対応する数が選択されます。
7.前の手順で選択した要素から、用語の自然階層のネットワークが構築されます。このネットワークでは、用語自体がノードと見なされ、関係は他の用語の出現に対応します。 図 図1は、リンクSEITを構築する原理を示しています。 この図の個々の幾何学的形状は、単一の単語に対応しています。

図 1-用語の自然な階層の3レベルネットワークでのリンクの形成
最初の行は選択された単一単語のセットに対応し、2行目はバイグラムのセットに対応し、3行目はトライグラムのセットに対応します。 単一の単語がバイグラムまたはトライグラムに入るか、バイグラムがトライグラムに入ると、矢印で示される接続が形成されます。 用語が対応する多くのノードとリンクは、用語の自然な階層の3レベルのネットワークを形成します。
8. SEIT形成の最終段階では、複雑なネットワークの分析と視覚化のためのソフトウェアツールによって表示されます。 自然用語階層のネットワークをデータベースにロードするために、一般に受け入れられているcsv形式の発生マトリックスが形成されます。
選択されたテキストコーパス上のさまざまなサイズの用語の自然階層の構築されたネットワークについて、ノードの発信度数の分布が決定されました。これは、べき乗則に近いことが判明しました(p(k)= C * k ^ h)、すなわち これらのネットワークはスケールレスです。 さまざまなサイズ(20 + 20 + 20〜200 + 200 + 200)のネットワークの係数hは2.1〜2.3であることが判明しました。
図 図2は、サイズ20 + 20 + 20の用語の自然な階層の小さなネットワークを示しています。これは、著者が提案した方法に従ってらせんの形で視覚化されています。

図 2-サイズ20 + 20 + 20のSEITビュー
図 図3は、Gephiシステム(https://gephi.org/)を使用して視覚化された、サイズ200 + 200 + 200の用語の自然階層のネットワークの一般的なビューを示しています。

図 3-Gephiを使用したサイズ200 + 200 + 200でのSEITの視覚化
図 図4は、選択された基本用語に対応する用語の自然な階層の個々のネットワークフラグメントを示しています。
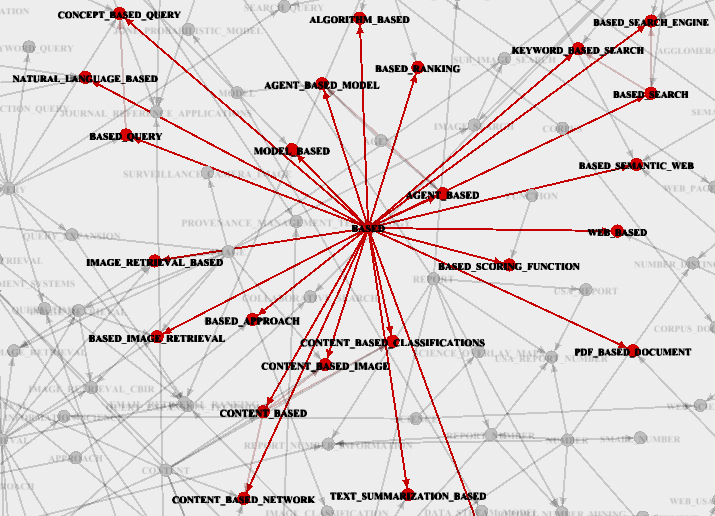

図 4-SEITのフラグメント
したがって、研究の結果:
- テキストのコーパスの分析に基づいて、自然用語階層のネットワークを構築するためのアルゴリズムが提案されています。
- このアルゴリズムに基づいて、用語の自然な階層のネットワークがテキストコーパスを使用して構築されます。
- 発信接続に対してスケールフリーであることが判明した用語の自然階層のネットワークの特性が調査されます。
- 自然用語階層のネットワーク用の視覚化ツールが選択されました。
- 提案された方法論を使用して構築された言語ネットワークは、関連するトピックのデータベースですぐに使用できるナビゲーションツールとして実際に使用され、コンテキストを整理するために、一般的なオントロジーを構築するためのベースとして使用できます情報検索システムのユーザーへのヒント。
文学
- Lande DV、Snarskii AA、Yagunova EV、Pronoza EVテキストの情報構造を定義する単語を特定するための水平方向の可視性グラフの使用//第12回人工知能に関するメキシコ国際会議、2013年-P. 209-215。
- Lande DV、Snarskii AA言語ネットワーク用のコンパクトな水平方向可視化グラフ// Prex Arxiv(1302.4619)
- Luque B.、Lacasa L.、Ballesteros F.、Luque J.水平可視性グラフ:ランダムな時系列の正確な結果//物理的レビューE、2009。-P. 046103-1-046103-11。
- Salton G.、McGill MJ現代情報検索入門。 -ニューヨーク:McGraw-Hill、1983 .-- 448 p。