
トラフィックの急増の原因は何ですか? 通信チャネルで何が起こったのですか?
アクションは、銀行などの大規模なデータセンターで行われます。 また、チャネルには、テストサービスや多数のビジネスサービスのいずれかを含めることができ、データベースのバックアップも同様に成功します。
管理者が完全に曲がっておらず、状況がそれほど複雑ではない場合、10分で問題を引き起こす特定の原因を特定し、さらに15〜20分で問題を分析できます。 状況がより複雑な場合(以下の別の例を検討します)、数日間の交通行動の異常を探すことができます。 このような異常を検出するツールを使用すると、この例で問題を見つけるのに1分かかります。
以下に簡単な例を示します。 通信チャネルのトラフィックが急増しました。これは、ユーザーアプリケーションにブレーキがかかったためです。
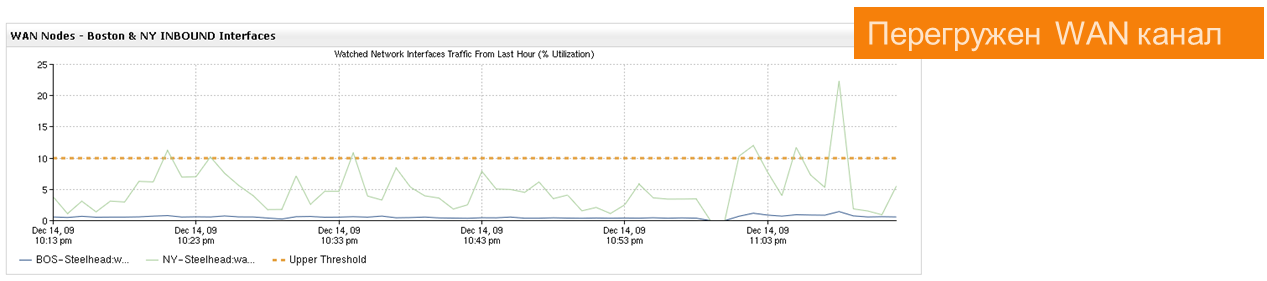
理解したいのは、通信チャネルで送信されるアプリケーション/サービスのトラフィックとサージの原因は何ですか?

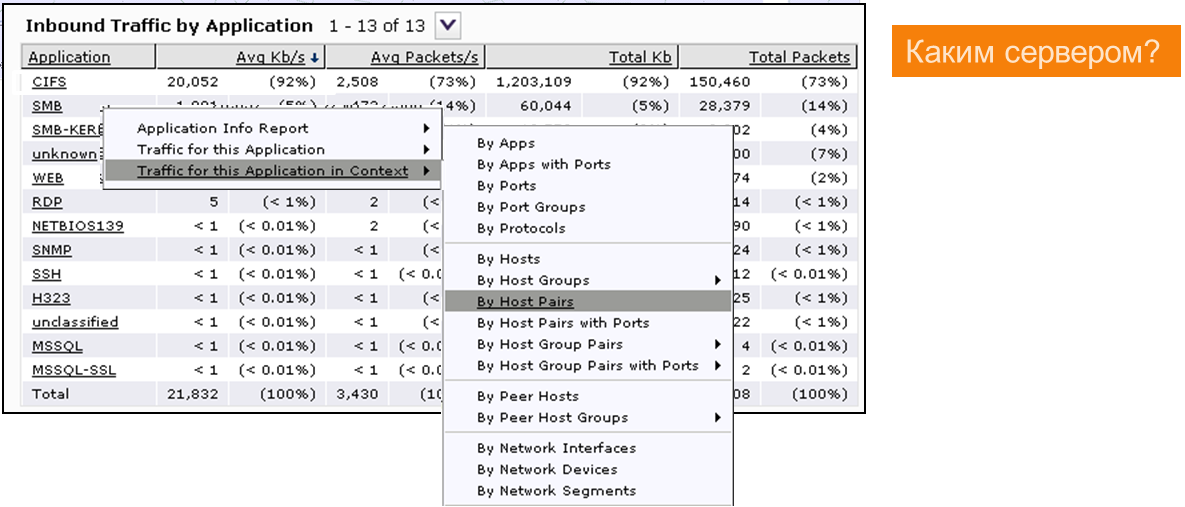
ええ、わかります... CIFS-総トラフィックの92%。

そこで働いた人(ホストとユーザー)を見つけます。
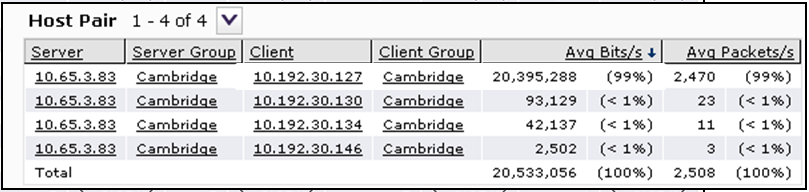
最初のクライアント/サーバーペアは、CIFSを介して通信チャネルを99%読み込みました。
Active Directoryと診断システムを統合している場合、それが誰であるかを知ることができます。 やってみます。
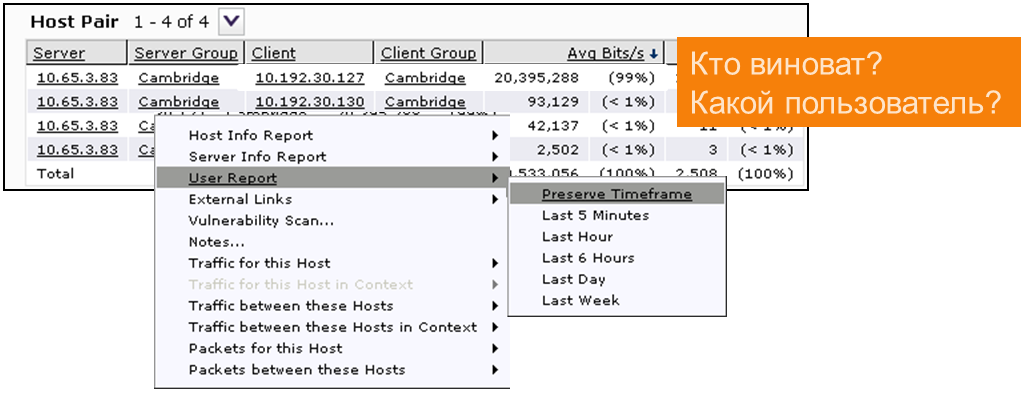
この種のジョン・スミスがいます。 問題には姓があります。 そして、このすべてを1分で。

例で作成されたレポート間のすべての遷移は、マウスの右ボタンをクリックして表示されるコンテキストメニューからレポートを選択することで実行されることを追加します。
次に、ERPシステム全体の速度が低下した場合の、より複雑な例を見てみましょう。
だから、そのような写真があります:
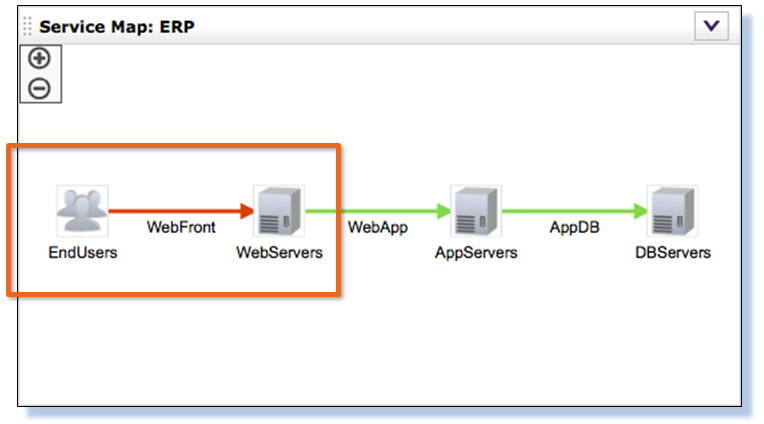
ERPの速度が低下すると、ユーザーは苦情を言います。 なんで? どこを見ますか? どこで見ますか?
もちろん、手動で理由を調べることができます。 これはおもしろいですが、数十の問題がある場合は骨が折れ、長くかかります。 さらに、トラフィックを分析し、トラフィックを収集して評価するには、独自のモジュールまたはサードパーティのモジュールの多くを使用する必要があります。 幸いなことに、すべてのデータを一度に1か所で取得できるツールがあります。 これがリバーベッドカスケードです。
一般的なタスク
これが単なる1つの問題ではなく、ビジネスサービスの低下を分析するさまざまなタスクの全体であるとします。 「インテリジェンス」を備えた通常のネットワークでは、次のことを理解する必要があります。
- サーバーはユーザーのリクエストにどのくらい応答しますか?
- パケットはネットワークをどのくらいの速度で通過しますか?
- どのデータがどこに行きますか?
- トラフィック交換の性質は何ですか(たとえば、多くの小さな頻繁な要求または大きな要求、アップダウンローディングプロファイル、潜在的な重複排除、または高速キャッシュへの配置)。
- ネットワークおよびサーバーの遅延はどこで発生しますか?
- このトラフィックはどのようにマークされますか(右?)
- サーバーはどのように相互作用しますか?
- アプリケーションモジュールはどのように接続されますか?
Riverbed Cascadeの使用
完全なソリューションは、3つ半の部分で構成されています。
- データ分析を担当するプロファイラー。 パイロットコンソールワークステーションアドオン-センサーに記録されたパケットコピー(TCPダンプ)の高速処理と分析のためのプロファイラーアシスタント。 簡単に言えば、Pilotは既知のすべてのWiresharkへのグラフィカルインターフェイスです。
- ゲートウェイ-スイッチ、ルーターなどの主要ソースからのデータ収集。 ゲートウェイはすべてのフロータイプを受け入れ、データは重複排除され、プロファイラーに送信されて分析されます。
- ミラーリングされたデータを観察し、遅延を測定するセンサー。 センサーは、問題の履歴分析のために収集されたパッケージも保存します。 統計は、分析のためにプロファイラーに送信されます。

特定のデータセンターの例:3つのモジュールすべてがインストールされています。 Shark Sensorはサーバーファームスイッチからミラーデータを受信し、Virtual Sharkは仮想マシン間の相互作用を分析します-ゲートウェイはルーターとオプティマイザーからフローを受信します。 その後、すべての統計がプロファイラーに送られます。 パイロットは、Shark Sensorに保存されたトラフィックのコピーを処理します
物思いサーバー
問題を抱えてERPに戻ります。
エンドユーザーとWebサーバーの間のセグメントで何が起こったのか、システムがそれについて信号を送った理由を理解し始めます。
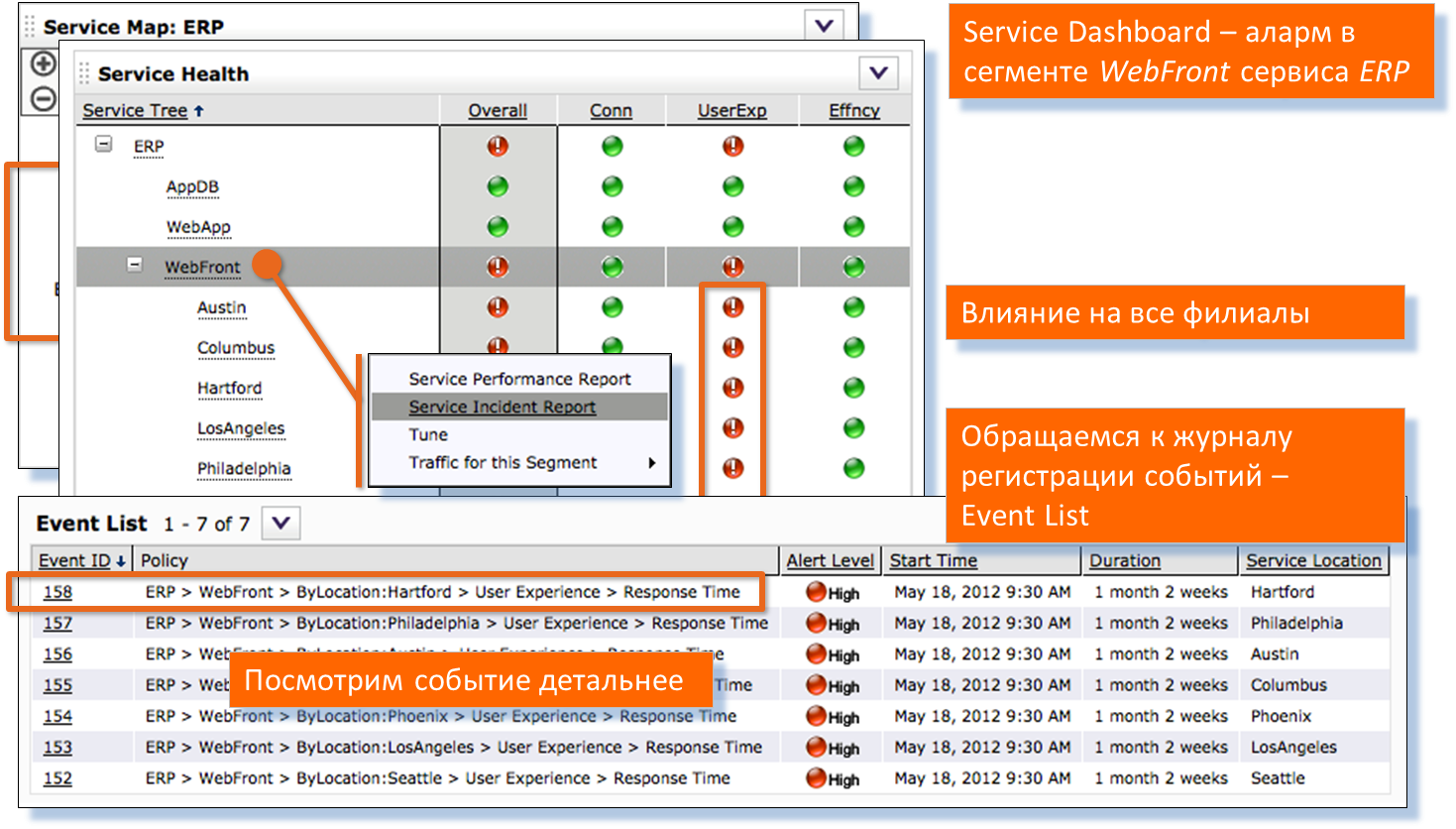
デスクトップのセマフォシステムを使用します。 会社のすべてのリモートブランチに問題があることがわかります。 この問題に関するインシデントを確認します。 詳細な分析に進みます-サーバーからの応答時間が増加したことは明らかです。 以下のグラフと表は、1つのレポートで作成されます。
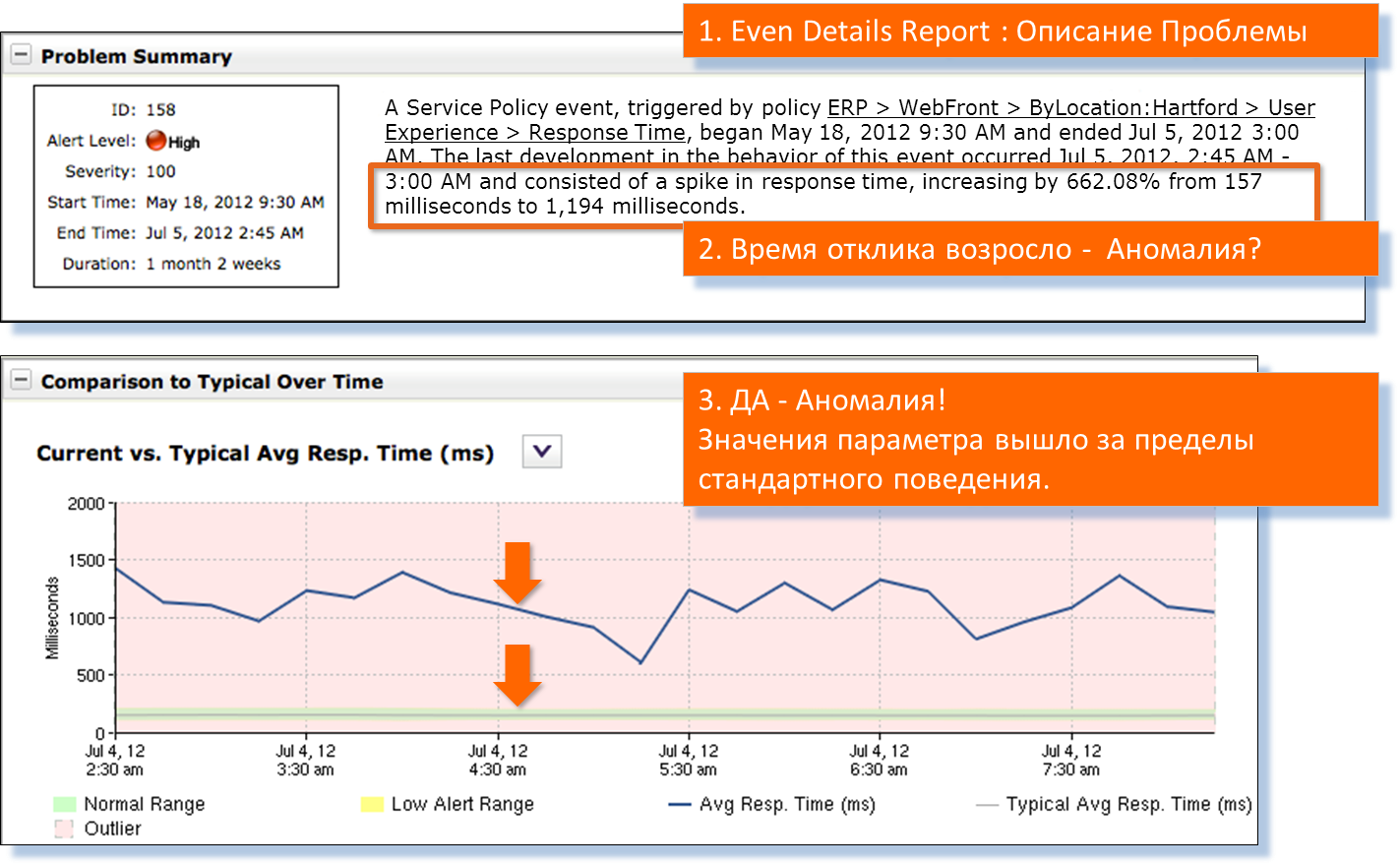
グラフの下部にある緑色の線は、サーバーの通常のプロファイルです。 これは、サーバーの安定した動作に必要です。
グラフでは、サーバーの応答時間の実際の値が青で表示されます。 下のレポートを下にスクロールします。

クライアントとサーバーの相互作用を調べます。 すべてのクライアントに何らかの問題があることがわかります。 ただし、サーバークラスターに問題があるサーバーは1つだけです。
問題のあるサーバーの統計を考慮してください。

サーバーのMACアドレス、スイッチのIPアドレス、およびサーバーが接続されているスイッチのポートが表示されます。 Wireshark-パイロットコンソールへのグラフィカルシェルでの問題のあるサーバーのトランザクションを検討してください。
オブジェクトごとのサーバー応答時間レポートは、1つのオブジェクトのみを提供する時間が増加したことを示しています。

ここに彼は:complex.psp
確認します。 トランザクション相互作用図を作成しています。 私たちはチェックします:
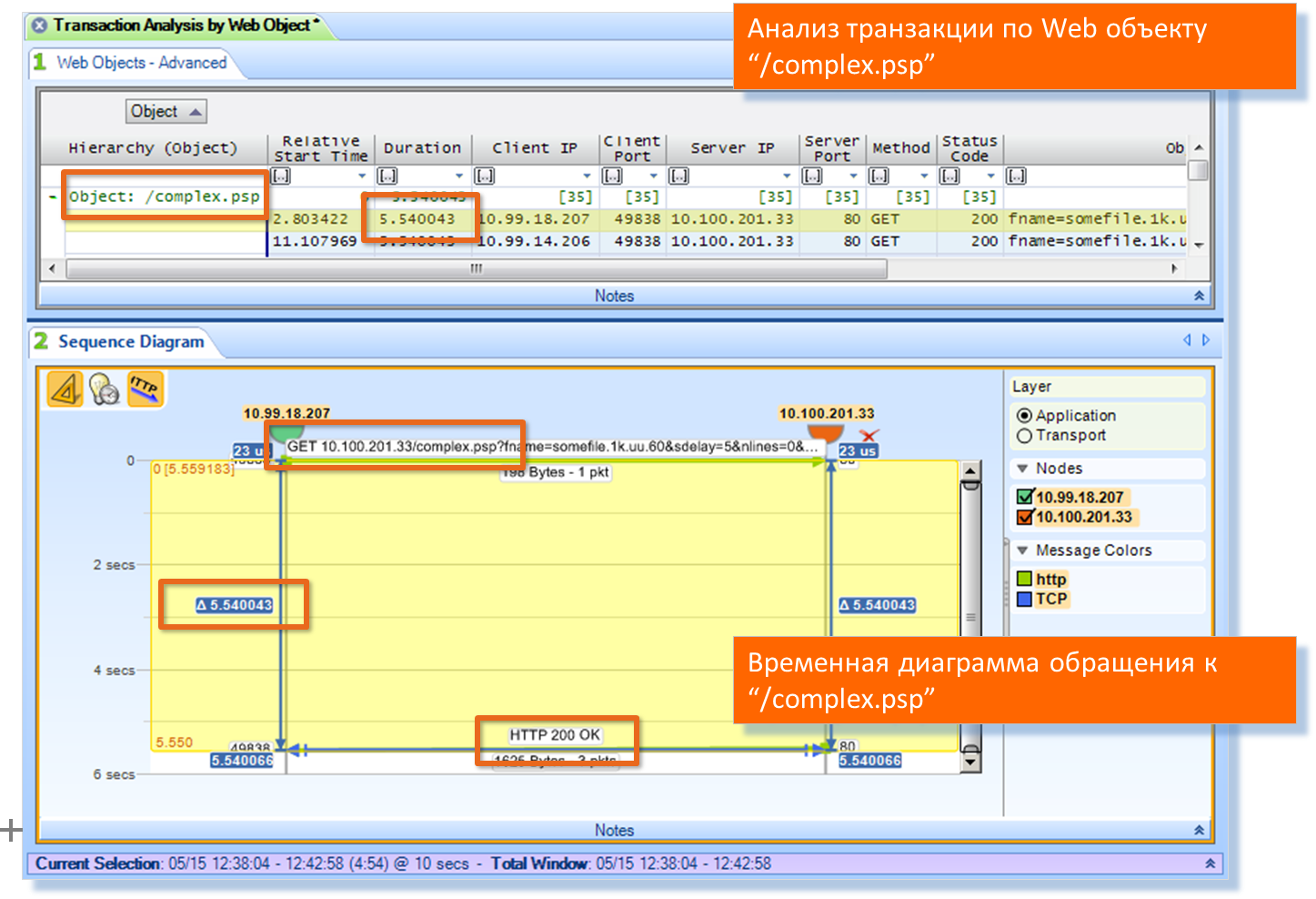
はい、それだけです。
まだ信じられない場合はチェックしてください。同じトランザクションのWiresharkでの手動バッチ分析に進みます。

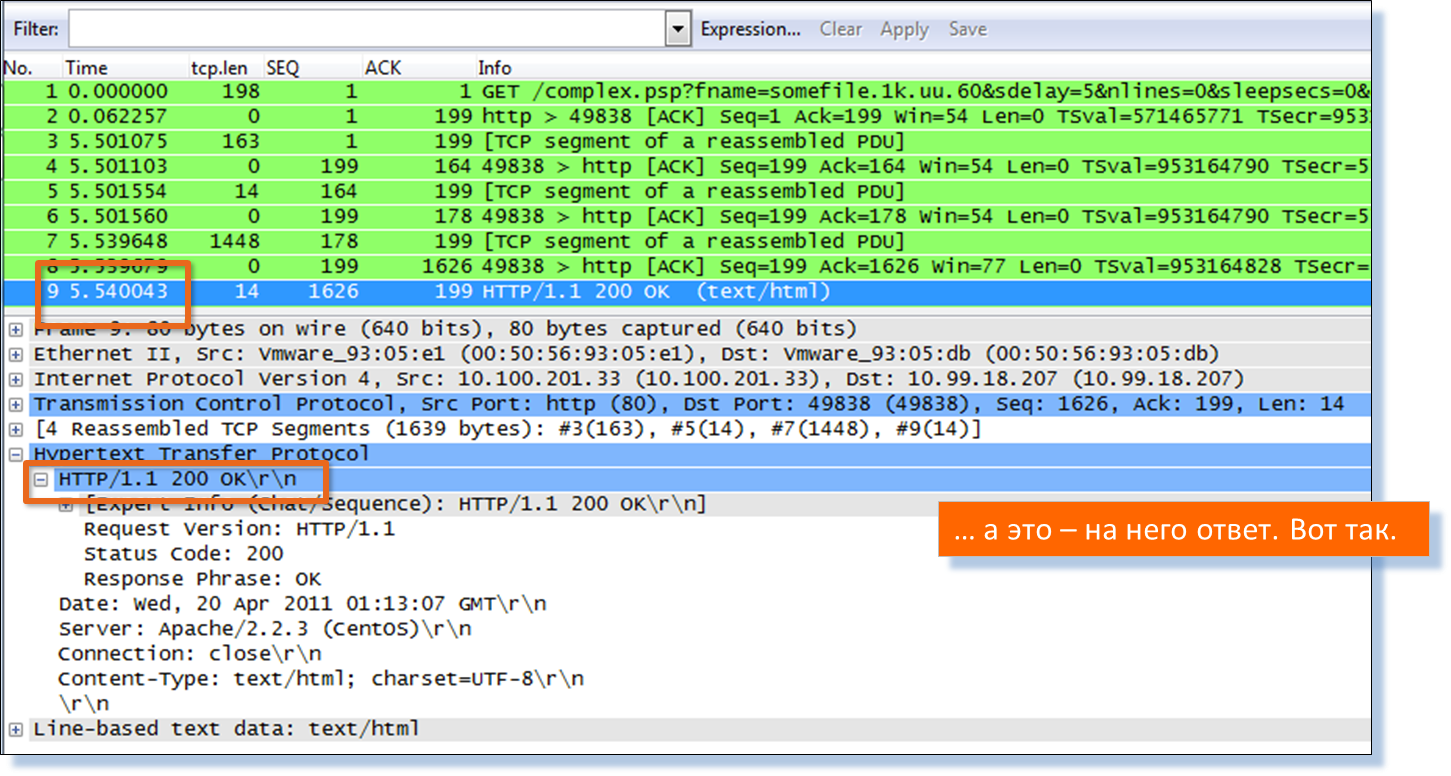
そのため、ERPサービスのWebサーバーとのユーザーインタラクションの包括的な画像を取得しました。これにより、サーバー上の不良なWebサーバー、または不良なオブジェクトを見つけることができました。
階層化されたアプリケーションの問題のローカライズ
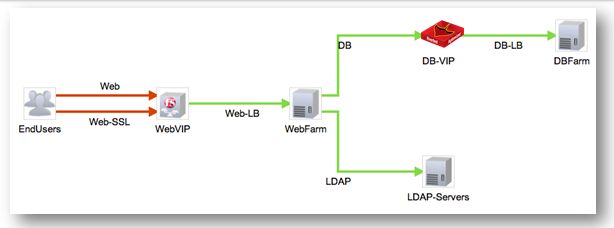
トラフィックロードバランサーを含むすべてのコンポーネントを示すマルチレベルアプリケーションの写真が表示されます。 システムは、サービス全体の劣化を分析する必要があるセグメントを視覚的に即座に明らかにします。トラフィックバランサーのVIPアドレスにアクセスすると、エンドユーザーセグメントは赤でマークされます。 その後、このセグメントのトラフィックの詳細な分析と、トラフィックバランサーのパフォーマンスの分析に進むことができます。 マルチレベルアプリケーションの各セグメントを手動で分析したり、このアプリケーションのコンポーネントが相互作用する方法を理解したりする必要はありません。アプリケーションコンポーネントの相互作用のマップを最初に見ると、視覚的にすべてが明確になります。
トラフィックオプティマイザーの互換性
以前の投稿で、データチャネルを完全に圧縮できるトラフィックオプティマイザーデバイスについて既に書いています。これは、銀行、通信事業者、その他の大企業だけでなく、通信チャネルをより効率的に使用してアプリケーションを高速化しようとする中規模および大規模企業でよく使用されます。 そのため、オプティマイザーは同じメーカーの製品であるため、Riverbed Cascadeモニタリングシステムを使用して、オプティマイザーからオプティマイザーを収集することもできます。 2つのソリューションは完全に(そして安価に、重要に)組み合わされ、企業のアプリケーションパフォーマンスの問題を包括的に解決します。
これらは、Riverbed Cascadeによって収集されたトラフィック最適化メトリックです。

LANトラフィック(青色のグラフ)とWANトラフィック(緑色のグラフ)の比率と最適化。 通信チャネルのトラフィック量がどれだけ減少したかを明確に確認できます
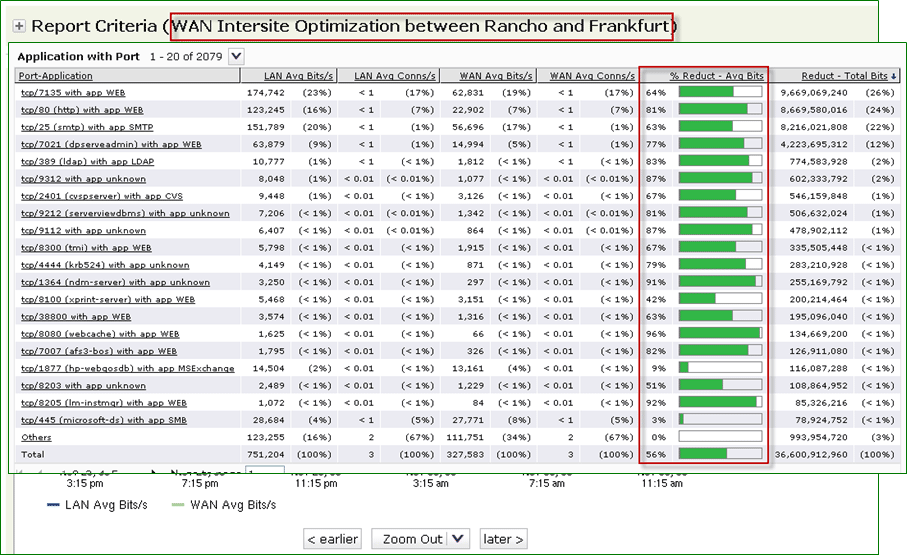
アプリケーションごとのトラフィックの最適化とそれぞれの帯域幅使用量の減少率
報告書
もちろん、このソリューションは、アプリケーショントラフィックの動作の問題や異常をローカライズするためだけに使用されるわけではありません。 たとえば、インフラストラクチャ開発の計画のために、レポートを作成すると非常に便利です。 たとえば、トラフィック量と支店別の種類に関するレポートを使用すると、Citrixトラフィックをリードする都市を見つけ、この方向を最適化することの利点を評価できます。
歴史的な観点とその出現時のリアルタイムの両方で問題を探すことができます(そして、ここでは、このような強力なアシスタントがいることにとても満足しています)。
エキスパートシステム
Riverbedソリューションには、行動分析というもう1つの優れた機能があります。 ご存じのとおり、最も重要なタスクの1つは、ビジネスサービスの低下についてタイムリーに関係者に通知することです。 通常、システムでは、アプリケーションパフォーマンスメトリックの固定しきい値のみを設定できます。 それらは管理者自身が発明しなければなりません。
ここで、Riverbed Cascadeはすべての競合他社よりも優れています。数十のメトリックを必要とし、各メトリックの通常の動作のプロファイルを作成します。 しきい値を設定する必要はありません。システムは履歴統計を収集し、それに基づいてしきい値が生成されます。 そして、あなたが標準から逸脱すると、システムは管理者またはそのマネージャーに通知します。
アプリケーションパフォーマンス分析に加えて、システムにはセキュリティ分析機能が含まれています。 つまり、次の場合、システムは管理者に警告します。
- ユーザーがネットワークをスキャンします。
- ユーザーは開いているポートをスキャンします。
- ネットワークに新しいホストが表示されます。
- ホストは新しいポートを使用します。
また、インストールされているウイルス対策システムがネットワーク上で新しいウイルスの拡散を確認しなくても、Riverbed Cascadeは、出現した異常なトラフィックの「ワーム」の拡散を検出します。
ご質問
ゴールドマイニング会社、地理的に分散した銀行、ロジスティクス会社にこのソリューション(トラフィック最適化を完備)を実装し、エネルギー会社のプロジェクトを完了し、さらに数十の小規模プロジェクトを完了しました。 このようなことは、私には思えるように、すべてのデータセンターで必要です。 一般に、質問がある場合は、 AVrublevsky @ croc.ruまたはコメントで質問してください 。 また、メールでインフラストラクチャの価格を指定することもできます。