現在、大規模なエンタープライズソリューションのパフォーマンスの向上に取り組んでいます。 その特異性により、多くのユーザーが同様のアクションを実行でき、それに応じて、アプリケーションサーバーは同じコードで動作します。 そして今、アプリケーションの高速化への長い道のりのある時点で、log4jが最もパフォーマンスの低いセクションの最上位になっていることがわかりました。 最初に考えたのは、過剰なログ記録でしたが、その後の分析では拒否されました。 さらに、これはサポートエンジニアにとって非常に重要なデータであり、今すぐ削除すると、コードが返されるか、サーバーの生産問題の分析が非常に難しくなります。
これにより、私はこの研究を促されました-ロギングプロセスを最適化する方法はありますか?
免責事項 : サイケデリックな関連付けを引き起こすこの記事の図が豊富であるため(このように:これは同期および非同期のロギングモードの比較ではありません、ドラゴンはここでヘビを殺します!)、未成年者、不安定な精神を持つ人、およびコードがすでにある妊婦には推奨されません生産と次のパッチのリリースは今年ではありません。
注意、トラフィックがカットされています。
その理由は何ですか?
いつものように、理由はありふれています-「競争力のあるアクセス」。 浮動小数点数の並列スレッドを使用したいくつかの実験の後、ロギングコールの作業時間が線形ではないことが明らかになりました。そのため、ハードドライブが大幅に失われます。
測定結果は次のとおりです。
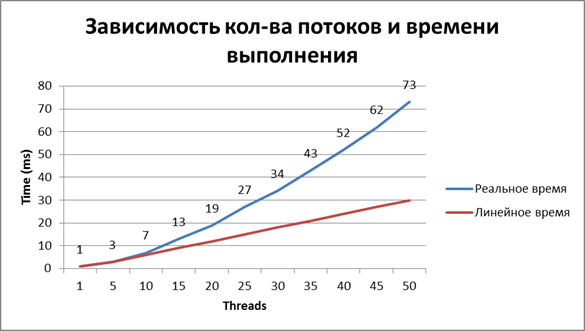
解決策は何ですか?
他のロギング方法を探し、ライブラリをアップグレードします。これはすべて可能ですが、タスクは最小限の労力で最大限の結果を達成することです。 log4j 2ライブラリについても説明できますが、これは別の記事になります。 ここで、log4j 1.xで提供される「箱から出してすぐに」提供される手段を検討します。
ライブラリに付属するアペンダーには、AsyncAppenderがあります。これは、中間バッファーを使用してログイベントを蓄積し、ファイルシステムとの非同期作業を整理することを可能にします(最終アペンダーがファイルロガーの場合は、もともとSMTPロガーを対象としていたため)。 生成されると、ロギングイベントが蓄積され、特定のレベルのバッファがいっぱいになった場合にのみ、ファイルに記録されます。
測定
アプローチが定義されたので、適切な測定を実行するために、その効果を理解する必要があります。
このように測定します。
0)プロセッサが別のジョブに切り替わったことが明らかな場所で、「美しいデータを実行しませんでした」と事前に警告し、これらの場所をそのままにしました。 これも、システムの実際の作業の一部です。
1)テストを3つのグループに分けます。
-10個のロギングイベント(1から10まで1ずつ増加)
-550個のロギングイベント(10から100まで、10ずつ増加)
-5500のロギングイベント(100から1000まで、100ずつ増加)
2)各グループには、テストの3つのサブグループがあります-バッファーのサイズに応じて(最適なものを見つけてください):
-500イベント
-1500イベント
-5000イベント
3)テストは同期的および非同期的に実行されます。
同期ロガーの構成
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd" > <log4j:configuration> <appender name="fileAppender" class="org.apache.log4j.FileAppender"> <param name="file" value="st.log"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d{ABSOLUTE} %5p %t %c{1}:%M:%L - %m%n"/> </layout> </appender> <root> <priority value="info" /> <appender-ref ref="fileAppender"/> </root> </log4j:configuration>
非同期ロガーの構成
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd" > <log4j:configuration> <appender name="fileAppender" class="org.apache.log4j.FileAppender"> <param name="file" value="st.log"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d{ABSOLUTE} %5p %t %c{1}:%M:%L - %m%n"/> </layout> </appender> <appender name="ASYNC" class="org.apache.log4j.AsyncAppender"> <param name="BufferSize" value="500"/> <appender-ref ref="fileAppender"/> </appender> <root> <priority value="info" /> <appender-ref ref="ASYNC"/> </root> </log4j:configuration>
4)テスト自体は、「ランダム操作」(ファイルへの代替アクセスを可能にするために1から15ミリ秒の期間)が散在する単純なロギング呼び出しです。
テストソースコード
package com.ice.logger_test; import org.apache.commons.lang3.time.StopWatch; import org.apache.log4j.Logger; import java.util.Random; public class SimpleTest { private static Logger logger = Logger.getLogger(SimpleTest.class); private static double NANOS_TO_SEC = 1000000000.0d; private static String LOG_MESSAGE = "One hundred bytes log message for performing some tests using sync/async appenders of log4j library"; public static void main(String[] args) throws InterruptedException { //performTest("Single thread"); ThreadRunner t1 = new ThreadRunner(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); new Thread(t1).start(); } private static void performTest(String message) throws InterruptedException { logger.info("Warm-up..."); logger.info("Warm-up..."); logger.info("Warm-up..."); StopWatch timer = new StopWatch(); Random ran = new Random(); for(int i = 1; i <= 10000; i += getIncrementator(i)) { timer.reset(); timer.start(); int iterations = 0; for(int j = 1; j <= i; j++) { timer.suspend(); Thread.sleep(ran.nextInt(15)+1); // some work timer.resume(); logger.info(LOG_MESSAGE); timer.suspend(); Thread.sleep(ran.nextInt(15)+1); // some work timer.resume(); iterations = j; } timer.stop(); System.out.printf(message + " %d iteration(s) %f sec\n", iterations, (timer.getNanoTime() / NANOS_TO_SEC)); } } private static int getIncrementator(int i) { if(i >= 0 && i < 10) return 1; if(i >= 10 && i < 100) return 10; if(i >= 100 && i < 1000) return 100; if(i >= 1000 && i < 10000) return 1000; if(i >= 10000 && i <= 100000) return 10000; return 0; } static class ThreadRunner implements Runnable { @Override public void run() { try { performTest(Thread.currentThread().getName()); } catch (InterruptedException e) { e.printStackTrace(); } } } }
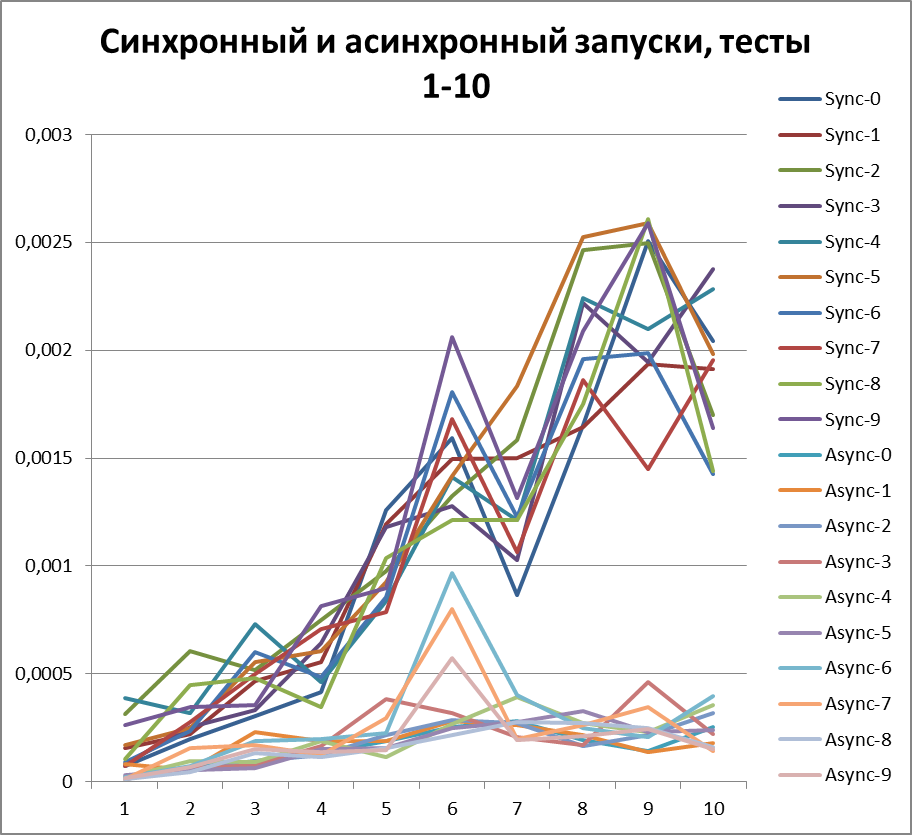
明確にするために、両方の結果(スレッドを失わないように中間を加えたもの)、同期および非同期が図で視覚化されます。
それでは始めましょう。
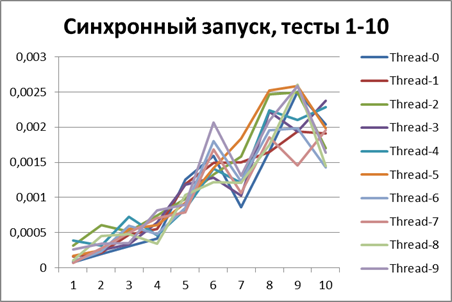
同期開始、2スレッド
まず、ロガーが同期構成でどのように動作するかを見てみましょう。 2つのスレッドですべてのスクリプトを実行します。結果は次のとおりです。

非同期開始、2スレッド
バッファー= 500
非同期モードに切り替え、同時に最適なバッファーを見つけようとします。500から始めます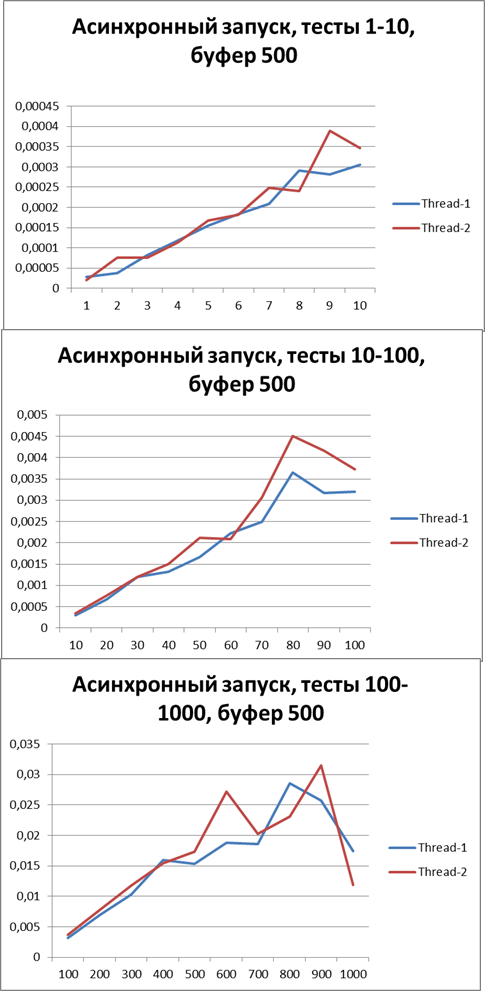
バッファー= 1500
バッファーを3倍に増やし、同じテストを実行します。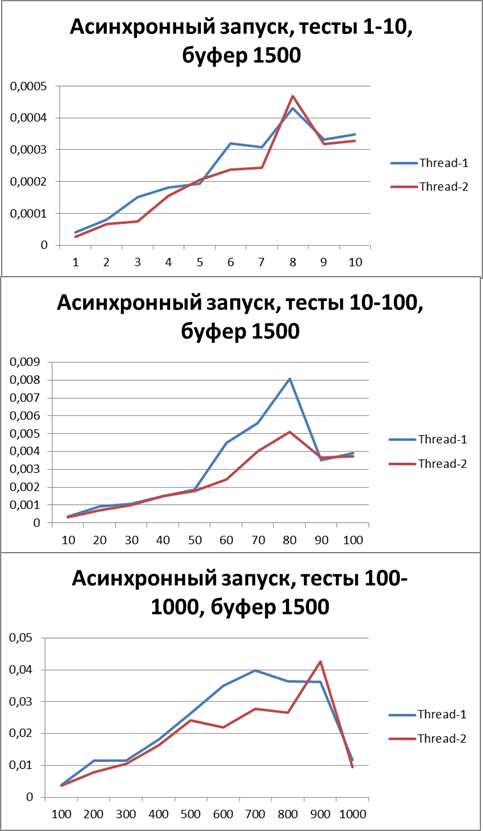
バッファー= 5000
バッファーを10倍に増やして、同じテストを実行してみましょう。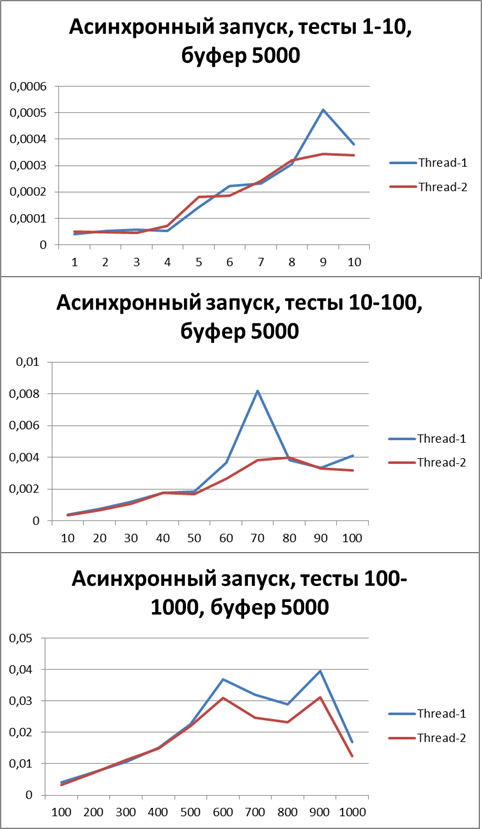
合計2スレッド
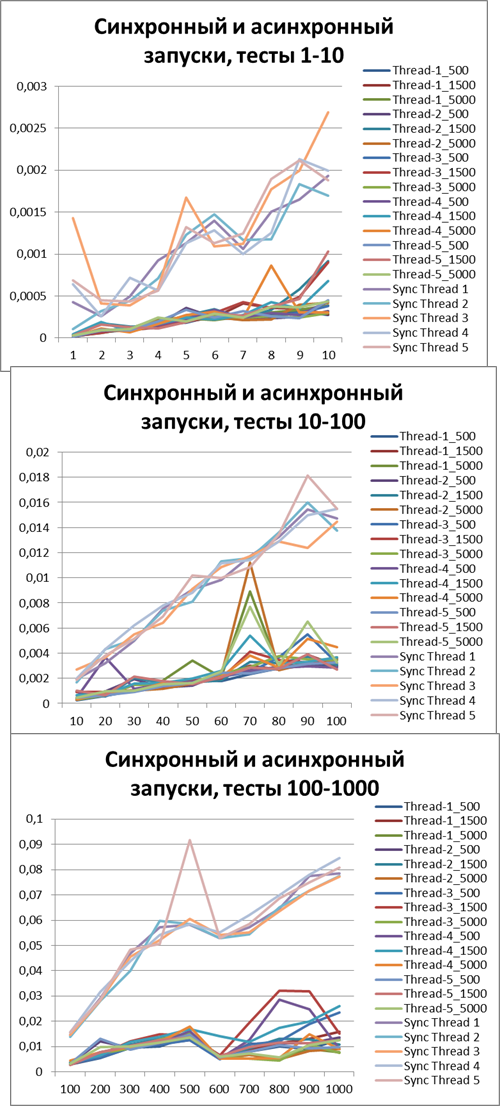
ここで、わかりやすくするために、すべての非同期(最適なバッファーを決定するために)および同期(わかりやすくするために、誰が勝ったか)テストを1つの図にまとめます。
今、私は非同期モードでの加速がはっきりと見えると思います。
しかし、結論を出す前に、5および10のスレッドでテストを繰り返しましょう。
同期開始、5スレッド
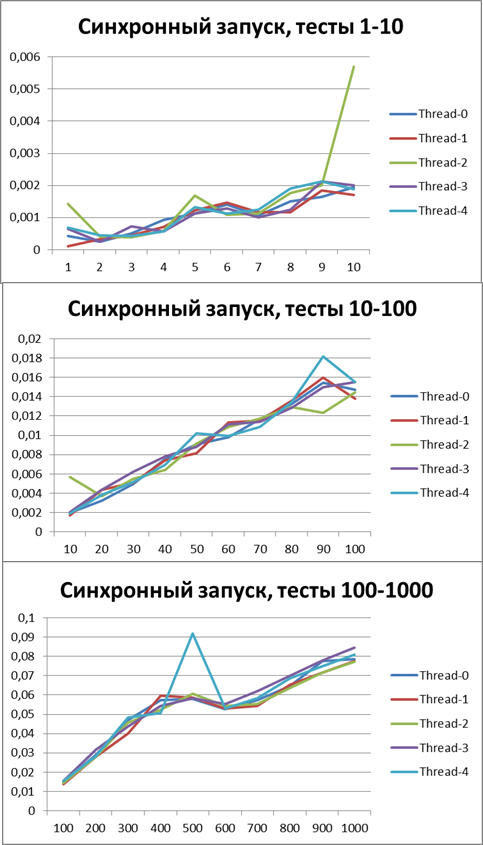
非同期開始、5スレッド
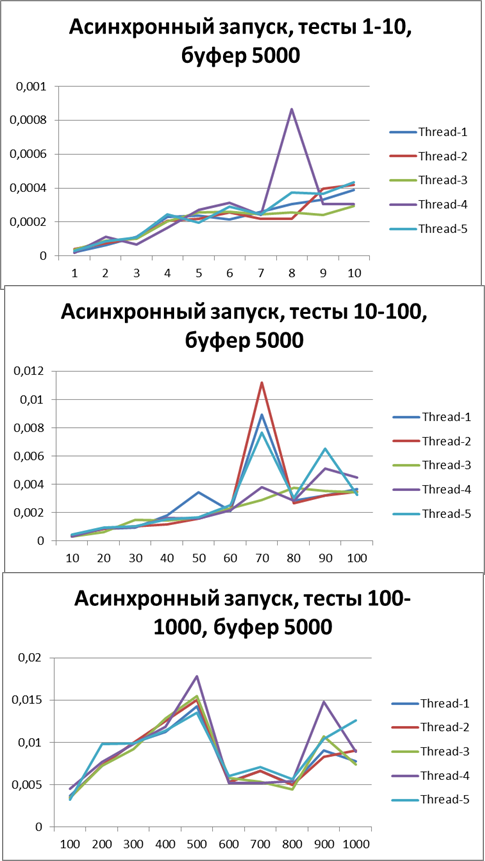
バッファー= 500

バッファー= 1500
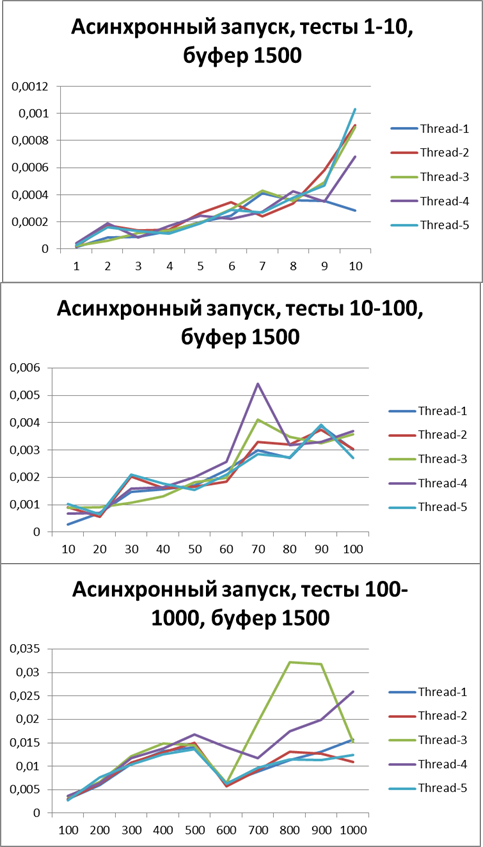
バッファー= 5000
5スレッドの合計
同期開始、10スレッド
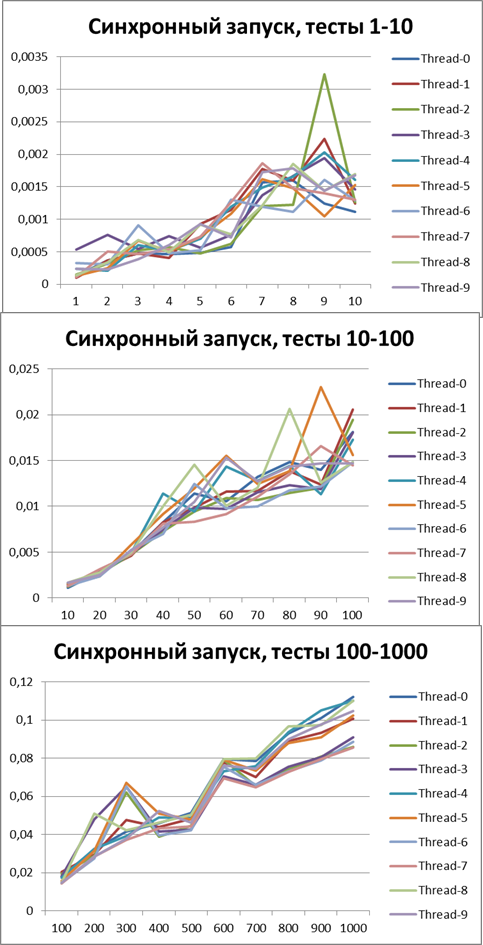
非同期開始、10スレッド
バッファー= 500
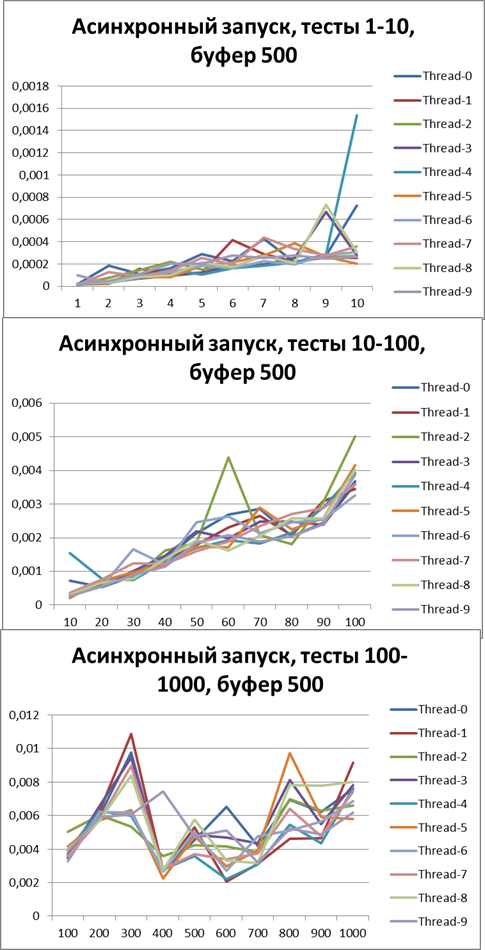
バッファー= 1500
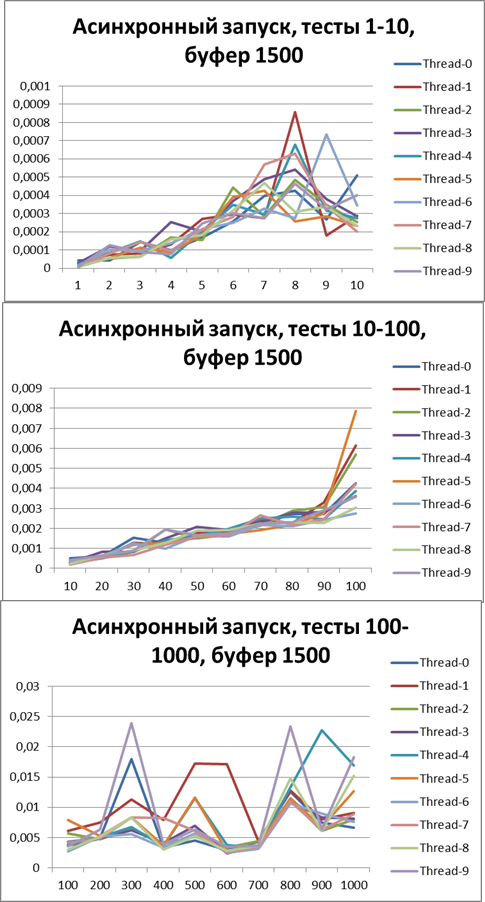
バッファー= 5000
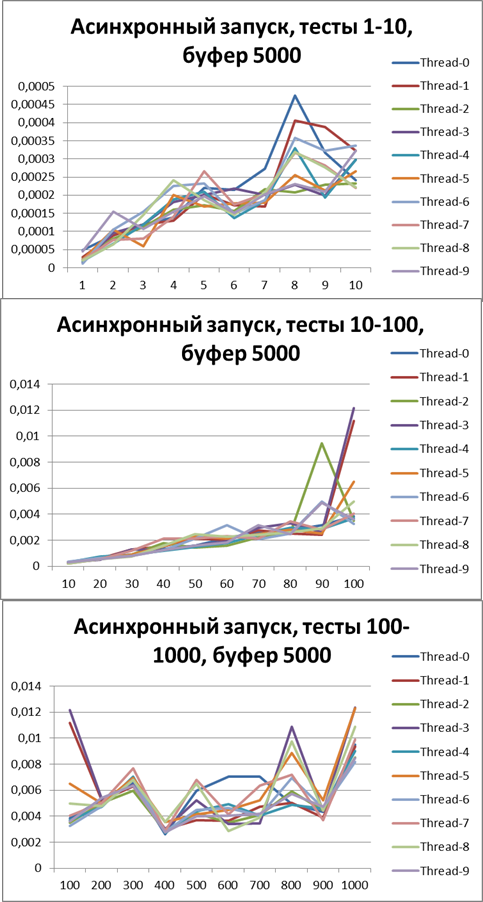
10スレッドの結果
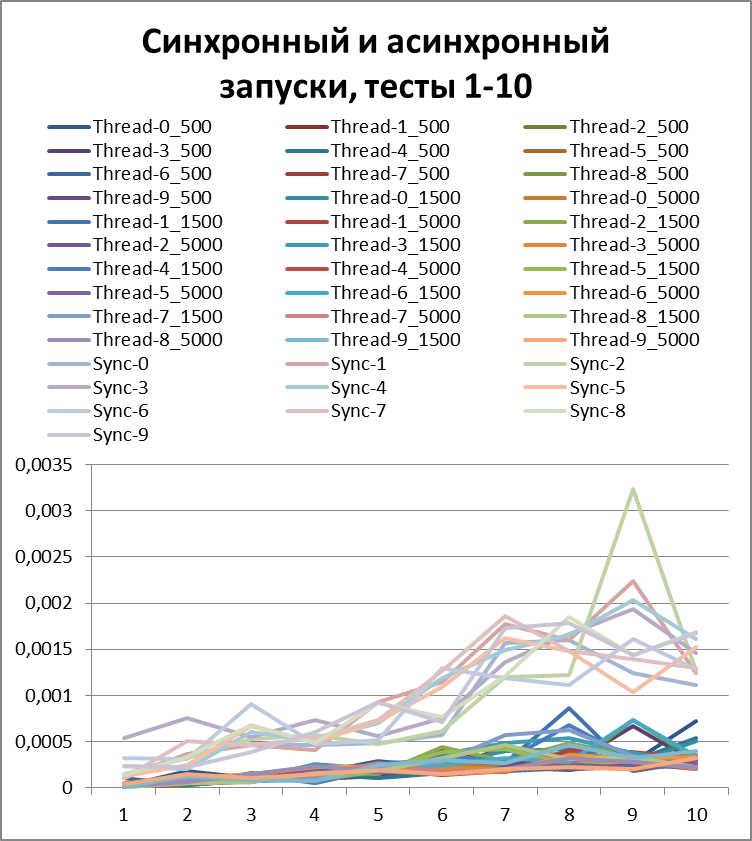
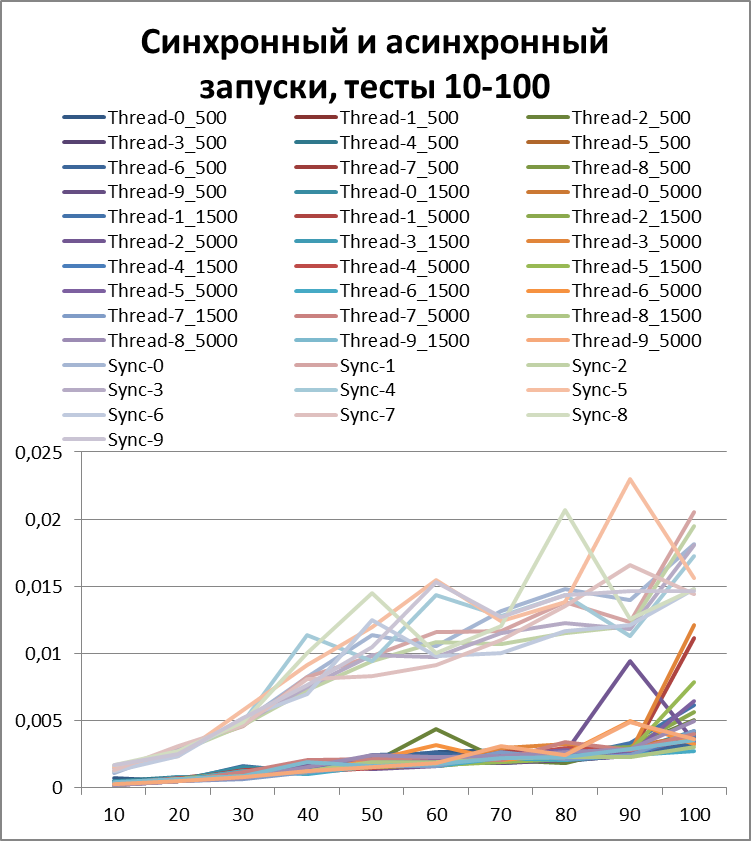
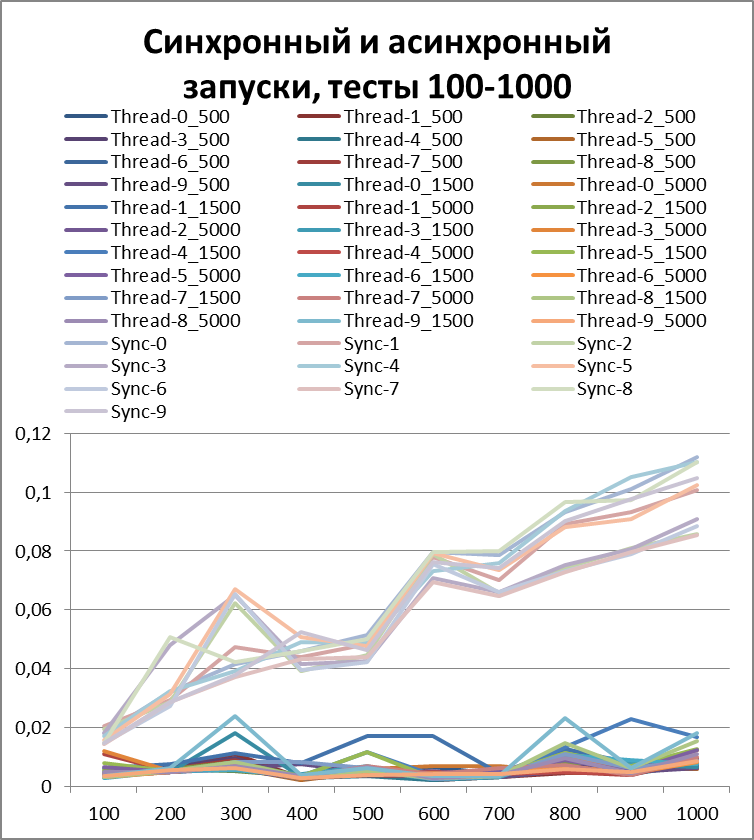
結論は、彼らが言うように、顔に。
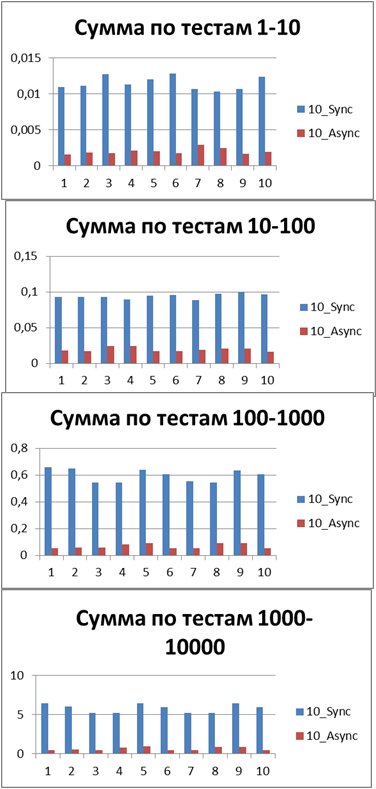
以来、ロギングの非同期方式の利点について明確に説明できるようになったので、テストの量をさらに10倍増やしてみましょう。 55,000のログイベントのテストを追加します(1000から1000単位で1000まで)。 500に等しいバッファーを使用します(一見、後で証明されるため、テストで最も最適であるため)。
同期開始、大量のデータで10ストリーム
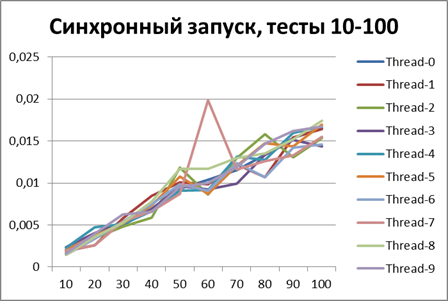
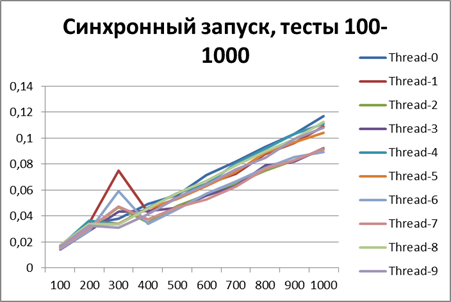
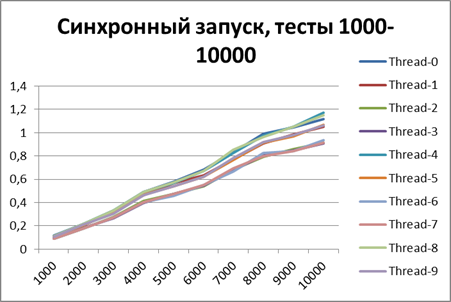
非同期開始、大量のデータで10スレッド
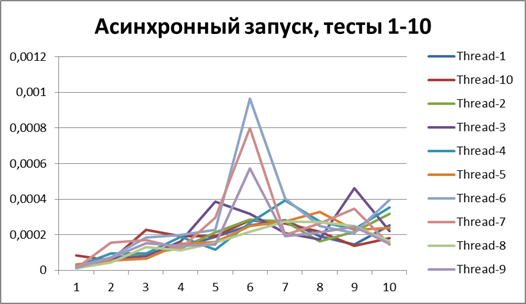
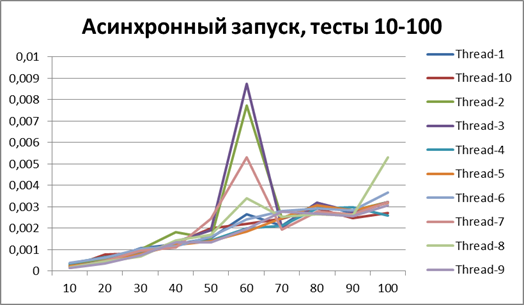
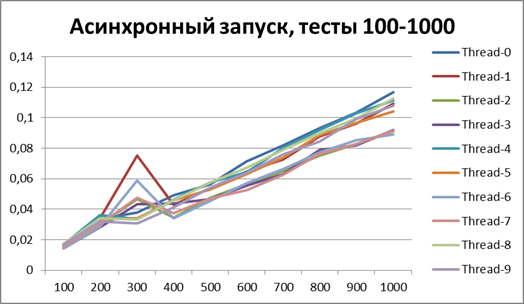
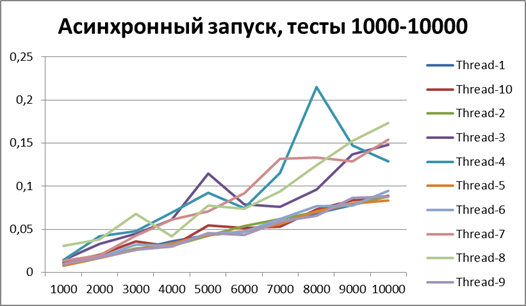
大量のデータで10スレッドの結果
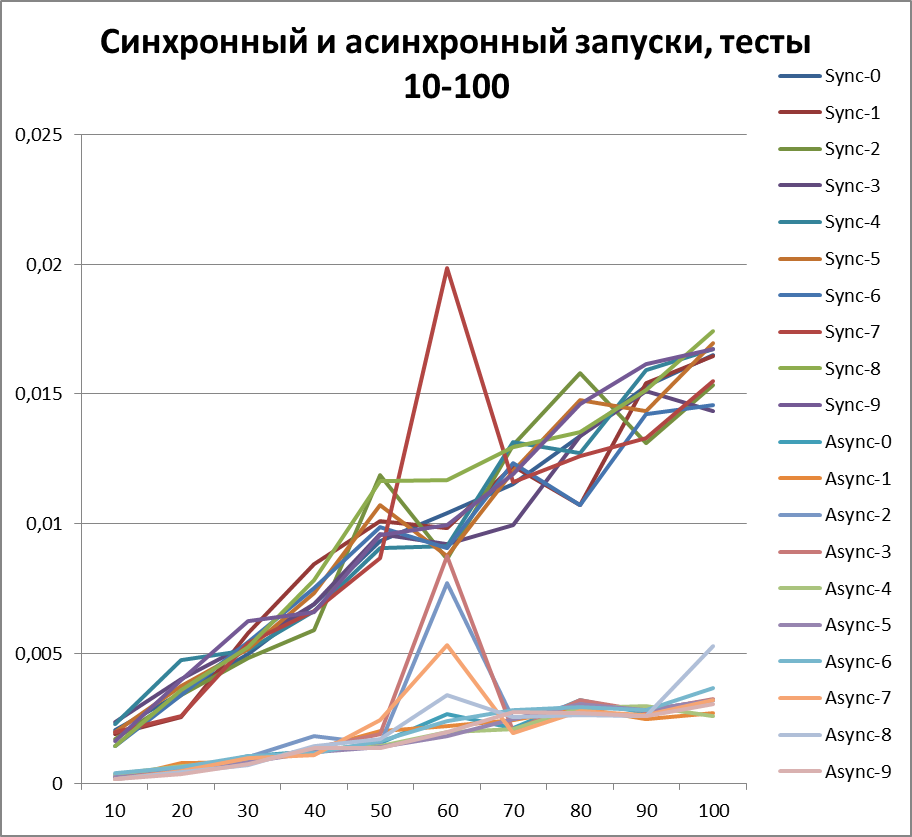
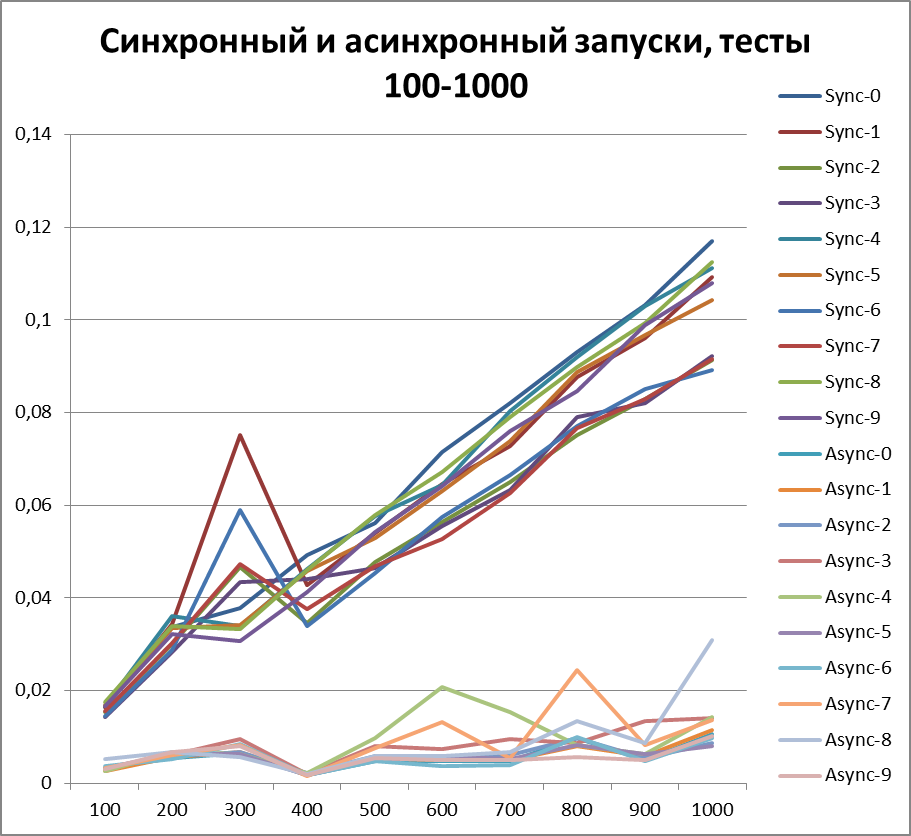
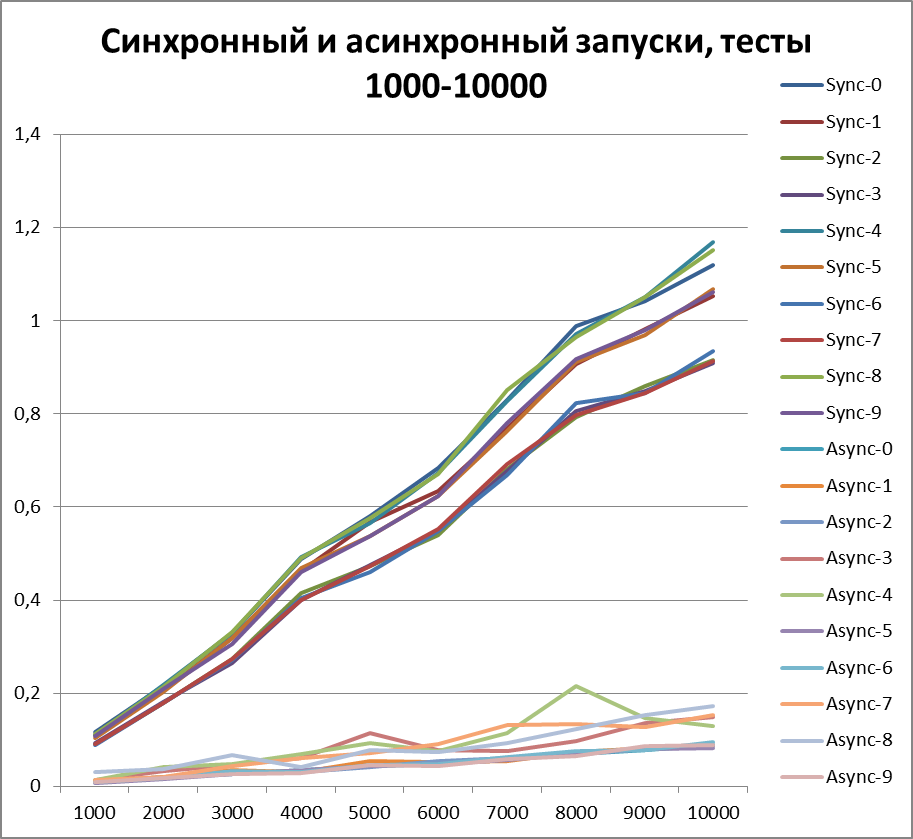
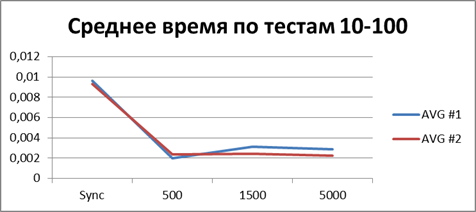
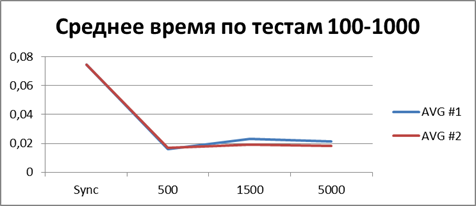
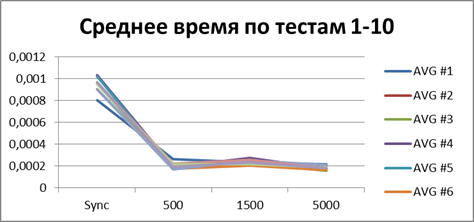
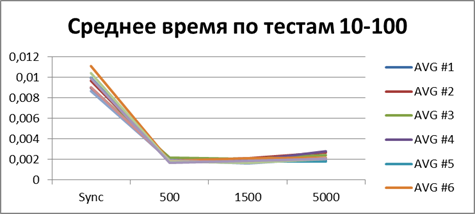
最適なバッファー
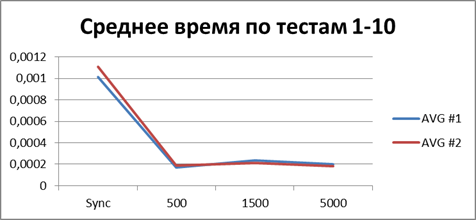
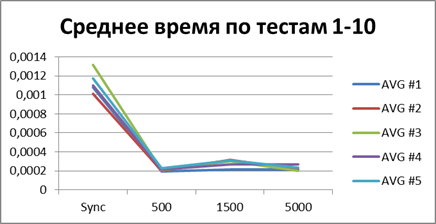
現時点では、かなり多くの統計をすでに蓄積しているので、それらをすべて平均して、どの種類のバッファーが最適かを見てみましょう。| 2スレッド | |
| 
|
| 5スレッド | |
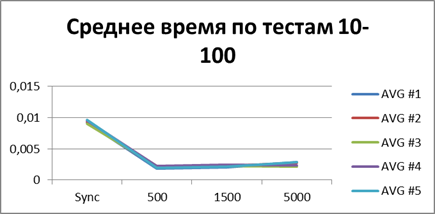

| 
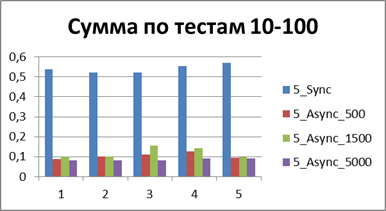
|
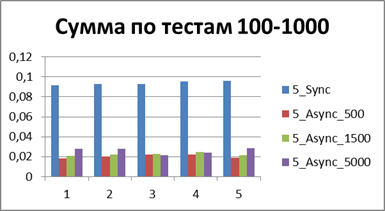
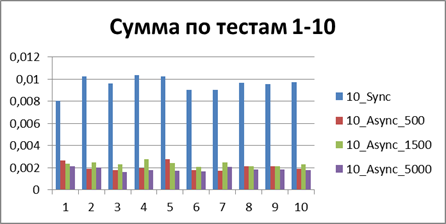
| 10スレッド | |

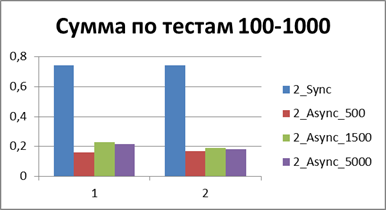
| 
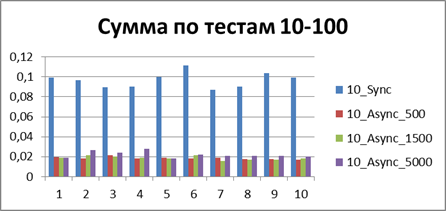
|
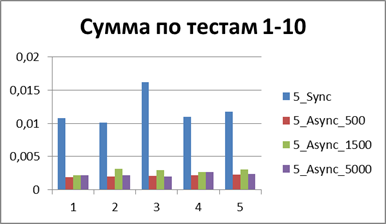
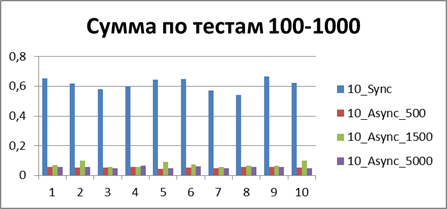
| 10スレッド、大量のテスト | |

| 
|
合計-500イベント 。これは、非同期モードで最も効率的に作業できるようにするバッファーです。
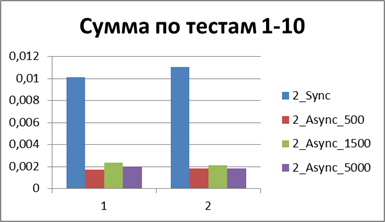
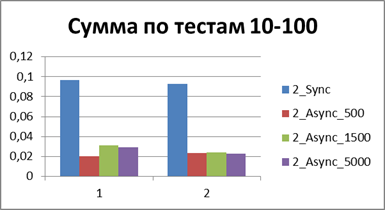
そして今、すべてのテストの合計(または平均)ランタイムを比較すると、同期モードの前に非同期モードの勝率を表示する定数を取得できます-8.9(回)です。
おわりに
上記の資料は、非同期ロギング戦略がパフォーマンスの向上をもたらすことを明確にします。 それから質問は頼みます-なぜそれを常に使用しませんか。 特定の方法を優先して選択するには、内部に隠されているメカニズムを想像する必要があります。 以下は、オフサイトから取られたいくつかの要約です。
1)AsyncAppenderは独自のスレッドで動作しますが(FileAppender自体は現在のスレッドのコンテキストで実行されます)、それを使用する場合は、アプリケーションサーバースレッドの制限を増やすことが望ましいです。
2)AsyncAppenderを使用すると、ロギングイベントがファイルに即座にダンプされるのではなく、バッファーがいっぱいになった後、メモリのオーバーヘッドが発生します。
3)ログファイルのロックは、同期アプローチを使用する場合よりも長く続きます。これは、メッセージバッファに記録のためのより多くの情報が含まれているためです。
原則として、すべては散文的ですが、ここでは同期自体もロックであるため、ある場所から別の場所に同期を転送しても悪化しないことを理解する必要があります。
本当に必要な場所で非同期を使用します。
-長時間実行されるアペンダー-SMTP、JDBC
-一般的なリソースのブロック-FTP、ローカルファイルストレージ
しかし、まず最初に、コードのプロファイルを作成してください。
この記事のExcelバージョン:
docs.google.com/spreadsheet/ccc?key=0AkyN15vTZD-ddHV0Y3p4QVUxTXVZRldPcU0tNzNucWc&usp=sharing
docs.google.com/spreadsheet/ccc?key=0AkyN15vTZD-ddFhGakZsVWRjV1AxeGljdDczQjdNbnc&usp=sharing
ご清聴ありがとうございました。 この記事がお役に立てば幸いです。
生産的な週を過ごしてください!