 ソフトウェアをプロファイリングした結果、バッファー比較機能を最適化する必要があると結論付けました。
ソフトウェアをプロファイリングした結果、バッファー比較機能を最適化する必要があると結論付けました。
なぜなら CLRはメモリの2つの部分を比較する標準的な方法を提供しないため、関数は独立して機能しました(機能する場合のみ)。
「.Netのバイト配列を比較する最良の方法」というフレーズをグーグルで探しましたが、ほとんどの場合、人々はLINQまたはEnumerable.SequenceEqual()を使用することを提案しました。 StackOverflowでも、これが最も一般的な回答でした。 つまり 壊滅的に人気のあるフォームの妄想:
「コンパイラとランタイム環境はループを最適化するので、パフォーマンスを心配する必要はありません。」
最初にこの投稿を書くことを考えさせられたのはそれでした。
C#から利用可能なバッファーを比較する5つの方法の比較テストを実施し、テスト結果に基づいて、メソッドの選択に関する推奨事項を示しました。
さらに、いくつかの関数を逆コンパイルし、x86構成用にJITコンパイラーによって生成されたコードを分析し、同様の目的でJITコンパイラーによって生成されたマシンコードとCRT関数のマシンコードを比較しました。
背景
別のユーティリティを作成して機能させた後、プロファイラを起動し、バイト配列の比較に非常に時間がかかっていることを確認しました。
CompareByteArrays()関数はクリティカルパス上にあり、やるべきことがありました。
パフォーマンスの問題に対するアルゴリズムの解決策は見当たりませんでした。アルゴリズムは事前に選択されており、結果として生じる複雑さを軽減する方法についてのアイデアはありませんでした。
World Wide Webでの検索結果はあまり期待できませんでした。メソッドの速度の比較はありましたが、これらの数値はどのデータで、どの条件で誰も書くことを気にせずに得られました。
私は、誰がどのような条件下でより速くなるかについて、独自の仮定を持っていました。 確認することにしました。
結果は面白かったので、ここでの断食の考えはついに成熟しました。
何をテストしましたか
主なもの
コードはコンパイルされ、Windows 7 x64マシン上で実行されました。 Microsoft Visual Studion 2010のデフォルト設定で、x86構成のみ、つまり これは32ビットコードです。 まず、出会ったコードのほとんどが32ビットシステム用に書かれているためです。 次に、この構成では.Netが重要であると考えています。 特に、大量の既存のコンポーネントが32ビット用に記述されており、誰もそれらを書き換えないため、それらと対話する必要があります。 最終的なアプリケーションの構成を決定します。 次に、64ビットを必要とするアプリケーションの数が非常に少ないため、必要なビット深度は主にメモリ要件とターゲットプラットフォームによって決まります。 最新の64ビットx86互換プロセッサは、ハードウェアで32ビットタスクをサポートします[1] [2]。 Windows x64が32ビットコードを直接実行することでこの機能を使用するのは論理的です[3]。 最初に32ビットアプリケーションを64ビットでコンパイルすると、コンパイラーオプションによってプロセッサーTLBサイズ、1次キャッシュも変更されず、ポインターサイズが2倍になり、必要なデータアライメント境界もあるため、必要なメモリが増加し、パフォーマンスが低下します変更[4]。
データサイズ
元のタスクでは、サイズが16バイトでサイズが1〜4 * 1024バイトのバイト配列を比較する必要がありました。 16バイトはMD5のサイズ、4 KbはWindowsの標準メモリページのサイズであるため、I / Oバッファ用に選択されました。
ただし、ハッシュのサイズが16バイトだけでなく、4バイト、さらには2バイト(CRC16、CRC32)、およびメモリページが4であるという単純な理由により、1バイトから1/2メガバイトのブロックで比較をテストしました。キロバイトだけでなく、2 MB [2]、さらには4 MBもあります。 1/2 MBブロックで示された結果は、大きなブロックでの作業について結論を出すのに十分でした。さらに、私の時間は無制限ではありません(テスト中にコンピューターに触れないようにして、説明されたプロセスから時間がかからないようにします)。
最初の実行の結果に基づいて、25種類のサイズのテストデータでメソッドを比較するだけで十分であることがわかりました。 これを行うには、最初のテストセットが1バイト配列で構成され、次の各ステップでテスト配列のサイズに同じ係数が乗算されるように、テストサイクルを構築しました。
パラメーターは、コード内の定数によって設定されました。
private const int CountArrays = 128; // private const int StartArraySize = 1; // private const int MaxArraySize = 512 * 1024; // private const int StepsCount = 25; // private const int MeasurementsCount = 10; //
メインのテストサイクルは次のようになります。
double sizeMultiplier = 1; DoInvestigationStep(sizeMultiplier); const int MaxMultiplier = MaxArraySize / StartArraySize; var stepMmltiplier = Math.Pow( MaxMultiplier, 1 / (double)StepsCount ); for (var step = 1; step <= StepsCount; step++) { sizeMultiplier = Math.Pow(stepMmltiplier, (double) step); DoInvestigationStep(sizeMultiplier); }
各ステップでの配列のサイズは、次のように計算されました。
var arraySize = (int) (StartArraySize * p_SizeMultiplier);
テスト済みのメソッド
System.Collections.IStructuralEquatableインターフェイスの使用
これはC#の比較的新しい方法であり、.NET 4でのみ登場したため、特に興味深いものでした。
private static bool ByteArrayCompareWithIStructuralEquatable(byte[] p_BytesLeft, byte[] p_BytesRight) { IStructuralEquatable eqa1 = p_BytesLeft; return eqa1.Equals(p_BytesRight, StructuralComparisons.StructuralEqualityComparer); }
LINQ、またはむしろEnumerable.SequenceEqual()
これは最も簡単な方法の1つで、実装が最も簡単です。 また、これは最も一般的な方法です。
private static bool ByteArrayCompareWithSequenceEqual(byte[] p_BytesLeft, byte[] p_BytesRight) { return p_BytesLeft.SequenceEqual(p_BytesRight); }
PInvoke、CRT memcmp()関数用
理論的には、これが最速の方法であるはずですが、常にそうであるとは限らないことが判明しました。プラットフォームとのやり取りのオーバーヘッドは非常に多くの時間を消費し、場合によってはこの方法はその魅力を失います。
ここで私はそれをSOで見つけた形で持ってきます。 この形式でテストしました。
PInvoke.netでは、少し異なります。
[DllImport("msvcrt.dll", CallingConvention = CallingConvention.Cdecl)] private static extern int memcmp(byte[] p_BytesLeft, byte[] p_BytesRight, long p_Count); private static bool ByteArrayCompareWithPInvoke(byte[] p_BytesLeft, byte[] p_BytesRight) { // Validate buffers are the same length. // This also ensures that the count does not exceed the length of either buffer. return p_BytesLeft.Length == p_BytesRight.Length && memcmp(p_BytesLeft, p_BytesRight, p_BytesLeft.Length) == 0; }
額に。 つまり for(;;)ループ内のバイトの直接比較
これは、2つの配列を比較する最も明白な方法であり、興味深いのはこのためです。
当初、この方法は速すぎるとは思われませんでしたが、多くの状況ではかなり許容できることが判明しました。
ちなみに、この比較方法のバリエーションの1つは、CLR製造業者自身の記事で 、さらに必要なテキストで使用されていました。
どうやら、ユーザーはそのような質問でそれらを終えました。
private static bool ByteArrayCompareWithSimplest(byte[] p_BytesLeft, byte[] p_BytesRight) { if (p_BytesLeft.Length != p_BytesRight.Length) return false; var length = p_BytesLeft.Length; for (int i = 0; i < length; i++) { if (p_BytesLeft[i] != p_BytesRight[i]) return false; } return true; }
Hafor Stefansonの最適化された安全でない方法
メソッドの作成者は、この最適化されたメソッドは、配列の先頭がQWORD境界に揃えられていると仮定して、配列の可能な最大部分について64ビットのブロックで比較を行うと主張しています。 QWORDアライメントがない場合でも動作しますが、速度は遅くなります。
ただし、32ビット環境では、64ビットブロックでの比較はアセンブラーを使用してのみ実現できます。汎用レジスターは32ビットであり、コンパイラーはこれらを使用してマシンコードを生成します。
したがって、このメソッドが実際にどのように機能するかは、コンパイル方法によって異なります。 私の場合、それは間違いなく64ビットではありません。
// Copyright (c) 2008-2013 Hafthor Stefansson // Distributed under the MIT/X11 software license // Ref: http://www.opensource.org/licenses/mit-license.php. private static unsafe bool UnsafeCompare(byte[] a1, byte[] a2) { if (a1 == null || a2 == null || a1.Length != a2.Length) return false; fixed (byte* p1 = a1, p2 = a2) { byte* x1 = p1, x2 = p2; int l = a1.Length; for (int i = 0; i < l / 8; i++, x1 += 8, x2 += 8) if (*((long*) x1) != *((long*) x2)) return false; if ((l & 4) != 0) { if (*((int*) x1) != *((int*) x2)) return false; x1 += 4; x2 += 4; } if ((l & 2) != 0) { if (*((short*) x1) != *((short*) x2)) return false; x1 += 2; x2 += 2; } if ((l & 1) != 0) if (*((byte*) x1) != *((byte*) x2)) return false; return true; } }
テスト方法
テストセット
テスト条件を戦闘条件にできるだけ近づけ、プロセッサキャッシュ内のテストデータの「妨害」を排除するため(可能な限りメモリを使用)、多くのテスト配列を生成し、それらを相互に比較することが決定されました。 それぞれの各配列。
テストセットとして、「ジャグ」アレイが選択されました(元のドキュメントでは「ジャグアレイ」)。 そこいくつかの選択肢は、例えば、だった、
List<byte[]>
と
LinkedList<byte[]>
が、.NETの配列がここに輝いていなくても代替案は、アイテムのスーツの時間アクセスがなかった:、どのような場合にはCLRを出力配列境界のインデックスをチェックします、それがゼロベースの配列であっても。
テストデータは、すべての配列が異なり、配列の異なる要素がちょうど中央にあるような方法で生成されました。
テストデータ生成
private static void PrepareTestData(int p_ArraySize) { for (int i = 0; i < CountArrays; i++) { var byteArray = new byte[p_ArraySize]; byteArray[p_ArraySize / 2] = (byte) (i & 0x000000ff); s_arrays[i] = byteArray; } }
比較する
すべての配列はすべてと比較されることになっているため、実行時間を測定したメソッドの一般的なビューは、セットのすべての配列に対する2つのネストされたループであり、テストメソッドはその内部で呼び出されます。 何が起こっているかの本質は、コードで表現することができます。
for (int i = 0; i < CountArrays; i++) for (int j = 0; j < CountArrays; j++) Compare( s_arrays[i], s_arrays[j] );
ただし、「計算」の結果を使用しない場合、CLRには「計算」自体を実行しないすべての権利があります。 C ++を試していたときに、これに出くわしました。 「-O3」最適化をオンにすると、何も測定することが非常に困難になりました。 何度もゼロであることが判明しました。 したがって、比較機能の結果が「蓄積」されて返され、最高レベルで分析されるように、そのようなシナリオを最初から除外することが決定されました。
結果を無視しない比較
var result = true; for (int i = 0; i < CountArrays; i++) for (int j = 0; j < CountArrays; j++) { var tmp = Compare( s_arrays[i], s_arrays[j] ); result = result && tmp; } return result;
比較結果の分析
var stubLocalVar = p_omparisonMethod(); if (stubLocalVar) throw new InvalidOperationException();
5つの比較方法があり、上記のテンプレートは一般的であるため、一般的な「テンプレート」方法を決定し、それに比較方法を渡すことは論理的に思えます。 このように:
不正な関数呼び出しメソッド
private static bool CompareArraysWithExternalMethod(Func<byte[], byte[], bool> p_Method) { var result = true; for (int i = 0; i < CountArrays; i++) for (int j = 0; j < CountArrays; j++) { var tmp = p_Method( s_arrays[i], s_arrays[j] ); result = result && tmp; } return result; }
このようなプロセスは、当然のことながら、除外コピー/貼り付け、エラーの確率を減少させ、それと同時に、特に多くのその呼び出しを考慮し、測定の精度の損失への不要な間接コールと除外の取り込み方法(インライン化)、順番にリードを作成します。 そのため、ほぼ同じ5つのメソッドを作成する必要がありました。
private static bool CompareArraysWithUnsafeMethod(); private static bool CompareArraysWithSimplestMethod(); private static bool CompareArraysWithSequenceEqualMethod(); private static bool CompareArraysWithPInvokeMethod(); private static bool CompareArraysWithIStructuralEquatableMethod();
ただし、レベルが高い場合は、テンプレートメソッドを既に適用できます。
以下のコードは、比較メソッドの実行時間を測定するMeasureComparisonTime()関数が、パラメーターとしてFunc型のデリゲートを取ることを示しています。 測定されるのは彼のランタイムです。
メソッド測定機能
private static long GetMinimalMesuredValue(int p_MeasurementNumber, long p_PreviousValue, long p_MeasuredValue) { var result = p_MeasurementNumber == 0 ? p_MeasuredValue : Math.Min(p_PreviousValue, p_MeasuredValue); return result; } private static long MeasureComparisonTime(Func<bool> p_Method, long p_PreviousTime, int p_MeasurementNumber) { GC.Collect(); GC.Collect(); s_stopwatch.Start(); var stubLocalVar = p_Method(); s_stopwatch.Stop(); if (stubLocalVar) throw new InvalidOperationException(); var result = GetMinimalMesuredValue(p_MeasurementNumber, p_PreviousTime, s_stopwatch.ElapsedTicks); s_stopwatch.Reset(); return result; }
測定手順
時間は、 QueryPerformanceCounter()に基づく標準のストップウォッチ( クラスSystem.Diagnostics.Stopwatch )を使用して測定されました。 当然、彼らはミリ秒ではなくチックに興味がありました。小さなアレイの場合、ミリ秒単位の測定値はすべてゼロになります。 また、RDTSCの基礎[6]の「自転車」を使用するためのアイデアを持っていたが、最初にすべての、最初のいくつかの実行は、それが手続きの電流精度のために十分であることが示されている、第二に、使用の警告ProcessThread.ProcessorAffinityに登場し、ドキュメントの最近のバージョンでは、このクラスの基礎は前述のプロセッサクロックカウンタであることが示唆されています。 すべての測定は10回繰り返され、最適な時間が取られました。 最小の時間でかなり正確な結果が得られるため、数値10は実験的に選択されました。
すべての測定を行う機能
private static MeasurementsResults DoMeasurements() { MeasurementsResults result; result.SimplestTime = 0; result.SequenceEqualTime = 0; result.PInvokeTime = 0; result.IStructuralEquatableTime = 0; result.UnsafeTime = 0; for (int measurementNumber = 0; measurementNumber < MeasurementsCount; measurementNumber++) { Console.WriteLine(" {0}", measurementNumber); result.SimplestTime = MeasureComparisonTime(CompareArraysWithSimplestMethod, result.SimplestTime, measurementNumber); result.SequenceEqualTime = MeasureComparisonTime(CompareArraysWithSequenceEqualMethod, result.SequenceEqualTime, measurementNumber); result.PInvokeTime = MeasureComparisonTime(CompareArraysWithPInvokeMethod, result.PInvokeTime, measurementNumber); result.IStructuralEquatableTime = MeasureComparisonTime(CompareArraysWithIStructuralEquatableMethod, result.IStructuralEquatableTime, measurementNumber); result.UnsafeTime = MeasureComparisonTime(CompareArraysWithUnsafeMethod, result.UnsafeTime, measurementNumber); } return result; }
測定結果と最初の結論
実験を開始する前に、どの方法が勝者であり、どの方法が部外者であるかがわかっていましたが、それでも結果は驚きました。 私の予測は完全に正しくありませんでした。
| ベストタイム(チック) | 配列サイズ(バイト) | 安全でない | 額 | ピンボーク | シーケンス | IStructuralEquatable |
|---|---|---|---|---|---|---|
| 276
| 1
| 1.7
| 1
| 6
| 10.5
| 55
|
| 276
| 1
| 1.7
| 1
| 6.3
| 10.1
| 55.7
|
| 325
| 2
| 1.3
| 1
| 5.3
| 11
| 95.2
|
| 374
| 4
| 1,1
| 1
| 4.8
| 11,4
| 121.3
|
| 413
| 8
| 1
| 1.3
| 5
| 14.1
| 181.2
|
| 412
| 13
| 1
| 1.7
| 4.7
| 17.5
| 252.5
|
| 490
| 23
| 1
| 2,3
| 3,7
| 22.1
| 364.8
|
| 554
| 39
| 1
| 3.4
| 3,5
| 30.1
| 535.9
|
| 691
| 67
| 1
| 4.3
| 2.9
| 39.1
| 727.5
|
| 887
| 114
| 1
| 5,6
| 2,4
| 50.3
| 964.1
|
| 1212
| 194
| 1
| 4.6
| 2.1
| 61.5
| 1190.9
|
| 1875
| 328
| 1
| 4.8
| 1.8
| 65.8
| 1295.8
|
| 2897
| 556
| 1
| 5
| 1,6
| 71.5
| 1416.9
|
| 4565
| 942
| 1
| 5.3
| 1.4
| 76.3
| 1521.1
|
| 7711
| 1595
| 1
| 5.2
| 1.3
| 76,2
| 1521.2
|
| 12482
| 2702
| 1
| 5,4
| 1.3
| 79,4
| 1593.6
|
| 20692
| 4576
| 1
| 5.5
| 1,2
| 81.2
| 1626.2
|
| 34369
| 7750
| 1
| 5,6
| 1,2
| 82.8
| 1657.1
|
| 58048
| 13124
| 1
| 5,6
| 1,2
| 82.9
| 1661.9
|
| 97511
| 22226
| 1
| 5,6
| 1,2
| 83.6
| 1677.3
|
| 173805
| 37640
| 1
| 5,4
| 1,1
| 79.5
| 1585.7
|
| 295989
| 63743
| 1
| 5.3
| 1,1
| 79.3
| 1574.9
|
| 588797
| 107949
| 1
| 4.6
| 1,1
| 67.5
| 1340.9
|
| 1010768
| 182811
| 1
| 4.6
| 1,1
| 67
| 1340.4
|
| 1705668
| 309590
| 1
| 4.6
| 1,1
| 67.3
| 1334.1
|
| 2885452
| 524287
| 1
| 4.6
| 1,1
| 67.3
| 1329.1
|
結果は次のとおりです。
最初に:CRT関数は単純に最適化する必要があり、特定の段階(テスト配列のサイズ)でその速度がプラットフォーム呼び出しのオーバーヘッドをブロックすると計算しましたが、これは起こりませんでした。 後で、はるかに大きなアレイでテストを繰り返しましたが、1.5メガバイトでも安全でないコードの方が高速であることがわかりました。
2番目:IStructuralEquatableは遅くなると思いましたが、数字は単に私を驚かせました:私は間違いなくこれを期待していませんでした。
個々の機能の診断と分析
等しく深刻大きいアレイ上危険な最も単純な差がある(私はこれ以上の2つの3時間「利点」より予想)ネットサポーターは、請求項のように.NETの配列の要素を最適化し、控訴のサイクルはそれほど滑らかではないことを示唆しています。 したがって、私はJIT'erの仕事の結果を見ることの喜びを否定しませんでした。 直接生成されたマシンコード。
CompareArraysWithSimplestMethod()関数の分析
これを行うために、メソッドの最初にThread.Sleep(60 * 1000)が挿入されました。 リリースビルドを起動した後、OllyDebugプロセスを選択しました。 このようなトリッキーな動きは、CLRの最適化を損なうことがないようにするために必要でした。
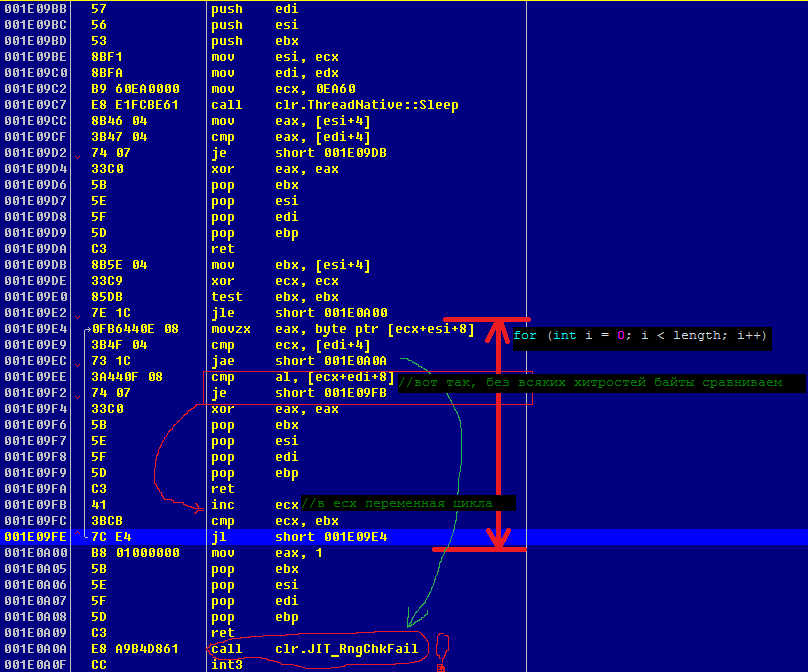
ntdll.NtDelayExecution()とSleepEx()からコールスタックを下って行くと、私は自分の関数を見つけ、慎重に研究した後、再び不快に驚きました。 ここで本当に好きではなかったもの:
- 単一のRngChkFailチェック(ループ全体に対して)の代わりに、CLRはインデックスごとにこのチェックを行います!!!
- サイクルは、私が書いた形のままでした。コンパイラはそれを「デプロイ」しませんでした。
- したがって、CLRは4バイト(レジスタサイズ)の比較を行うなど、CLRを最適化することはできましたが、比較はバイト単位のままでした。
- 単一のエピローグで単一の戻り値を返してスタックをクリアする代わりに、CLRはそれらを3回コピーし、コードを「膨張」させました。 実際、マシンコードはC#コードをほぼ1対1で繰り返します。 これに関して、疑問が生じます。彼はコードをまったく最適化しましたか?! 彼はこれを行う方法を知っていますか?
- おそらく前の段落(コードの膨張)のおかげで、関数はインライン化されませんでした。
UnsafeCompare()関数分析
この関数を逆コンパイルした結果、私の好奇心が燃え上がり、他の関数について考えるようになりました。 CRT機能と安全でないオプションを比較することにしました。 まず、安全でないオプションを検討することにしました。 これを行うには、最初の関数と同じ操作を行いましたが、Thread.Sleep()は関数自体ではなく、呼び出される前に挿入されました。 これは、何が起こっているかの本質にほとんど影響を与えることはできませんでしたが、逆コンパイルを幾分単純化しました。安全でない関数は明らかに最初のものより複雑です。
挿入スレッド。スリープ()
private static bool CompareArraysWithUnsafeMethod() { var result = true; for (int i = 0; i < CountArrays; i++) for (int j = 0; j < CountArrays; j++) { Thread.Sleep( 60 * 1000 ); var tmp = UnsafeCompare(s_arrays[i], s_arrays[j]);
この関数の前半も重要です。 UnsafeCompare()が呼び出されるまで。 最初の例と同様に、配列の要素にアクセスすると、配列の境界内でインデックスがチェックされます。 私は、リストにこのことを強調しました。
CPU Disasm CompareArraysWithUnsafeMethod
;Address Hex dump Command Comments 001B0B88 55 push ebp ; 001B0B89 8BEC mov ebp, esp 001B0B8B 57 push edi 001B0B8C 56 push esi 001B0B8D 53 push ebx 001B0B8E BF 01000000 mov edi, 1 ; result = true; 001B0B93 33DB xor ebx, ebx ; for (int i = 0; 001B0B95 33F6 xor esi, esi ; for (int j = 0; 001B0B97 B9 60EA0000 mov ecx, 0EA60 ; Thread.Sleep( 60 * 1000 ); 001B0B9C E8 0CFBC161 call clr.ThreadNative::Sleep 001B0BA1 8B15 A8337A03 mov edx, [s_arrays] ; EDX <-- s_arrays 001B0BA7 3B5A 04 cmp ebx, [edx+4] ; Compare(s_arrays.Length, ) (1) !!! 001B0BAA 73 31 jae short stub_CLR.JIT_RngChkFail 001B0BAC 8B4C9A 0C mov ecx, [ebx*4+edx+0C] ; ECX <-- s_arrays[i] 001B0BB0 3B72 04 cmp esi, [edx+4] ; Compare(s_arrays.Length, ) (2) !!! 001B0BB3 73 28 jae short stub_CLR.JIT_RngChkFail 001B0BB5 8B54B2 0C mov edx, [esi*4+edx+0C] ; EDX <-- s_arrays[j] 001B0BB9 FF15 F0381400 call near UnsafeCompare
関数の逆コンパイルの結果は非常に大きく、1つの画面に収まらないため、デバッガウィンドウのスクリーンショットは提供しませんでした。 大規模な統合されたリストは読むのが退屈で非生産的であるため、ここでは論理的に関連した断片で説明し、各断片に短いコメントを付けます。
UnsafeCompare()。
;a1 ========> ECX ;a2 ========> EDX ;Address Hex dump Command Comments 001B0BF8 55 push ebp ; 001B0BF9 8BEC mov ebp, esp 001B0BFB 57 push edi ; , , , 001B0BFC 56 push esi ; 001B0BFD 53 push ebx ; 001B0BFE 83EC 0C sub esp, 0C ; 3*sizeof(DWORD), .. 3 001B0C01 33C0 xor eax, eax ; (!) 001B0C03 8945 F0 mov [ebp-10], eax ; var1 <-- 0 (!) 001B0C06 8945 EC mov [ebp-14], eax ; var2 <-- 0 (!) 001B0C09 85C9 test ecx, ecx ; Compare(a1, null) 001B0C0B 74 0C je short return1 001B0C0D 85D2 test edx, edx ; Compare(a2, null) 001B0C0F 74 08 je short return1 001B0C11 8B41 04 mov eax, [ecx+4] ; eax <-- a1.Length 001B0C14 3B42 04 cmp eax, [edx+4] ; Compare(eax, a2.Length) 001B0C17 74 0A je short argsIsValid return1: 001B0C19 33C0 xor eax, eax ; result <-- 0 001B0C1B 8D65 F4 lea esp, [ebp-0C] 001B0C1E 5B pop ebx 001B0C1F 5E pop esi 001B0C20 5F pop edi 001B0C21 5D pop ebp 001B0C22 C3 ret argsIsValid: ;
.NET Framework [7] [8]に続くfastcall呼び出し規約によると、最初と2番目のパラメーターは、左から右の順にecxおよびedxレジスターにあります。 上記のリストでは、入力パラメーターの順次チェックが明確に表示されており、C#のコードにほぼ明確に対応しています。
if (a1 == null || a2 == null || a1.Length != a2.Length) return false;
ただし、強調表示されている行には特別な注意が必要です。その目的は不明であり、混乱を招きます。 それが何である必要があるのかを理解するために、別の実験を行う必要がありました。その間に、C#で最も単純な安全でない関数を作成しました。この関数は固定句とポインター処理を使用し、同様のアクションを実行しました。
private static unsafe int func1(byte[] param1) { fixed (byte* p = param1) { return *p; } }
最も単純な安全でない機能の悲惨さ
;param1 ========> ECX Address Hex dump Command Comments $ ==> 55 push ebp ; $+1 8BEC mov ebp, esp $+3 50 push eax ; (!) $+4 33C0 xor eax, eax ; (!) $+6 8945 FC mov [ebp-4], eax ; var1 <-- 0 (!) $+9 85C9 test ecx, ecx ; Compare(param1, null) $+B 74 06 je short param_is_null $+D 8379 04 00 cmp dword ptr [ecx+4], 0 ; Compare(param1.Length, 0) $+11 75 07 jne short not_zero_len param_is_null: $+13 33D2 xor edx, edx $+15 8955 FC mov [ebp-4], edx ; var1 <-- 0 $+18 EB 0C jmp short ret_1 not_zero_len: $+1A 8379 04 00 cmp dword ptr [ecx+4], 0 $+1E 76 10 jbe short call.JIT_RngChkFail $+20 8D49 08 lea ecx, [ecx+8] ; ecx <-- param1.BufferPointer $+23 894D FC mov [ebp-4], ecx ; var1 <-- ecx ret_1: $+26 8B45 FC mov eax, [ebp-4] ; eax <-- var1 $+29 0FB600 movzx eax, byte ptr [eax] ; eax <-- *eax $+2C 8BE5 mov esp, ebp ; $+2E 5D pop ebp $+2F C3 ret call.JIT_RngChkFail: $+30 E8 B3BDC861 call clr.JIT_RngChkFail $+35 CC int3
それをリスト上からにかかわらず、汎用レジスタの可用性の、スタック上に置くようにしてください固定提案におけるJITコンパイル変数の結果としてその明確になります。 これは、eaxレジスターがスタックに保存され、将来使用されず、したがって操作のために無料でアクセス可能である(関数の開始からオフセット0x26まで)が、オフセット変数スタック変数が一時データを格納するために使用されたという事実から明らかですebp-4](var1と呼びましょう)。 変数は、それが使用されていませんが、単純に上書きされているにもかかわらず、すぐに必ずしもゼロに初期化されます。 例えば、VAR1ゼロで0x15のオフセットは既にゼロ格納され、この時点で存在するという事実にもかかわらず、再び入力されます。
したがって、それはリストUnsafeCompare.CPU Disasm.ParametersCheckingで選択された行に特別な意味はないクマが存在しないことが明らかになり、それはコンパイルのちょうど副作用です。 また、上記のリストから、配列が3つの段階で固定式でチェックされることが明らかになります:最初に、配列のnullがチェックされ、次にその長さがゼロと等しいか(jneコマンドがZFのみを分析する)、ゼロと負の値が等しいかがチェックされます( jbeはZFとCFの両方をチェックします)。 私の視点からは、条件分岐がフラグをリセットしないため、CMP命令は、2回実行されていることを、すべてのより多くの奇妙な最後の2つの手順が一つに結合されたことはなく、奇妙である、と。 それは私が無駄にしようとしていないことを意味し、およびアセンブリリストの私の発掘調査は無駄ではなかったので、他のものの中で、私は、この行を読んであなたの人々に心から感謝しています。
この実験は、さらにコード分析を大幅に簡素化します。
CompareArraysWithUnsafeMethod()関数の固定句
argsIsValid: 001B0C23 8379 04 00 cmp dword ptr [ecx+4], 0 ; Compare(a1.Length, 0) 001B0C27 75 07 jne short a1Len_NonZero ; 001B0C29 33C0 xor eax, eax 001B0C2B 8945 F0 mov [ebp-10], eax ; var1 <-- 0 001B0C2E EB 10 jmp short a1Len_Zero a1Len_NonZero: 001B0C30 8379 04 00 cmp dword ptr [ecx+4], 0 ; Compare(a1.Length, 0) () 001B0C34 0F86 B5000000 jbe call.JIT_RngChkFail ; 001B0C3A 8D41 08 lea eax, [ecx+8] ; eax <-- a1.BufferPointer 001B0C3D 8945 F0 mov [ebp-10], eax ; var1 <-- eax a1Len_Zero: 001B0C40 837A 04 00 cmp dword ptr [edx+4], 0 ; Compare(a2.Length, 0) 001B0C44 75 07 jne short a2Len_NonZero ; 001B0C46 33D2 xor edx, edx 001B0C48 8955 EC mov [ebp-14], edx ; var2 <-- 0 001B0C4B EB 10 jmp short part3 a2Len_NonZero: 001B0C4D 837A 04 00 cmp dword ptr [edx+4], 0 ; Compare(a2.Length, 0) () 001B0C51 0F86 98000000 jbe call.JIT_RngChkFail ; 001B0C57 8D52 08 lea edx, [edx+8] ; edx <-- a2.BufferPointer 001B0C5A 8955 EC mov [ebp-14], edx ; var2 <-- edx
コンパイラはここで驚きを示しませんでした。 コンパイルアルゴリズムにより、簡単に予測可能な結果が得られます。 たとえば、固定句で初期化された変数は、とにかくスタックにプッシュされます。
固定ブロック内の変数の初期化:
part3: ; ECX <======= a1 ; EDX <======= a2.BufferPointer ; var1 <======= a1.BufferPointer ; var2 <======= a2.BufferPointer 001B0C5D 8B45 F0 mov eax, [ebp-10] ; eax <-- var1 001B0C60 8BF0 mov esi, eax ; esi <-- eax 001B0C62 8B45 EC mov eax, [ebp-14] ; eax <-- var2 001B0C65 8BF8 mov edi, eax ; edi <-- eax 001B0C67 8B41 04 mov eax, [ecx+4] ; eax <-- a1.Length 001B0C6A 8945 E8 mov [ebp-18], eax ; var3 <-- eax
固定ブロック内の変数の初期化は、JITコンパイラーがコードを生成する原理をよく示しているという点で興味深いものです。ここでは、スタック変数からインデックスレジスタに値を直接送信する代わりに、値が最初にアキュムレータレジスタに配置されることが明確に示されています。たぶん、これはある種の秘密の魔法の意味ですが、それは余分なアクションのように見えます(eaxに送信)。
8バイトのループ
001B0C6D 33C9 xor ecx, ecx ; <-- 0 001B0C6F 8BD8 mov ebx, eax ; ebx <-- a1.Length 001B0C71 85DB test ebx, ebx 001B0C73 79 03 jns short ebx_greaterZero 001B0C75 83C3 07 add ebx, 7 ; , 7 ebx_greaterZero: 001B0C78 C1FB 03 sar ebx, 3 ; ebx <-- a1.Length / 8 001B0C7B 85DB test ebx, ebx 001B0C7D 7E 1D jle short fourBytesComparing for8_body: 001B0C7F 8B06 mov eax, [esi] 001B0C81 8B56 04 mov edx, [esi+4] 001B0C84 3B57 04 cmp edx, [edi+4] 001B0C87 75 04 jne short setResult_jumpReturn 001B0C89 3B07 cmp eax, [edi] 001B0C8B 74 04 je short for8_increment setResult_jumpReturn: 001B0C8D 33C0 xor eax, eax ; result <-- 0 001B0C8F EB 56 jmp short return2 ; goto return for8_increment: 001B0C91 41 inc ecx 001B0C92 83C6 08 add esi, 8 001B0C95 83C7 08 add edi, 8 for8_expression: 001B0C98 3BD9 cmp ebx, ecx 001B0C9A ^ 7F E3 jg short for8_body
サイクルの構造は非常に簡単です。たとえば、サイクルカウンターは伝統的にecxに配置され、カウンターの境界値はebxに配置されますが、これも伝統的です。ここで注目すべきは、ループ条件の最初のチェックが初期化直後にあり、メインループ条件のように見えないことです。奇跡が起こらないことも明らかであり、REXプレフィックスは保護モードまたは互換モードのいずれでも使用できません。 QWORDブロックとの比較は不可能であるため、DWORDサイズのブロックが比較されます。ただし、コードは、比較を実行する前に、最初の配列の対応する部分がeax、edxレジスタにロードされることを示しています。 JITコンパイラは、ソースコードに可能な限り近いマシンコードを生成しようとしました。
コンパイラがここでCMPSD文字列命令、つまり、esiとediアドレスに配置されたDWORDブロックを比較し、適切なフラグを設定する「短い」形式を使用しなかったことは驚くべきことです。この場合、マシンコードのサイズは数倍小さくなります:movコマンドのサイズは2バイトと3バイト、cmpコマンドのサイズは2バイトと3バイト、各CMPSDコマンドのサイズ(短い形式)は1バイトのみです。 。 2チームの場合は2バイトのみ。これは、JITコンパイラーがコードの最適化を望まないことを示唆しています。
上記のリストから、最初のコマンドがeaxへの転送であるいくつかのコマンドが、コンパイラーが厳密に従うパターンであることは明らかです。
そのようなボリュームが残っている場合、DWORDサイズのブロックを比較しようとします。
fourBytesComparing: 001B0C9C F745 E8 0400000 test dword ptr [ebp-18], 00000004 ; ZF <-- (var3 & 4) == 0 001B0CA3 74 10 je short length_lowerThenFour 001B0CA5 8B06 mov eax, [esi] 001B0CA7 3B07 cmp eax, [edi] 001B0CA9 74 04 je short dwords_equals ; , 001B0CAB 33C0 xor eax, eax 001B0CAD EB 38 jmp short return2 dwords_equals: 001B0CAF 83C6 04 add esi, 4 001B0CB2 83C7 04 add edi, 4
WORD, , :
length_lowerThenFour: 001B0CB5 F745 E8 0200000 test dword ptr [ebp-18], 00000002 ; ZF <-- (var3 & 2) == 0 001B0CBC 74 10 je short length_lowerThenTwo 001B0CBE 0FBF06 movsx eax, word ptr [esi] 001B0CC1 66:3B07 cmp ax, [edi] 001B0CC4 74 04 je short words_equals ; , 001B0CC6 33C0 xor eax, eax 001B0CC8 EB 1D jmp short return2 words_equals: 001B0CCA 46 inc esi 001B0CCB 46 inc esi 001B0CCC 47 inc edi 001B0CCD 47 inc edi
BYTE, , :
length_lowerThenTwo: 001B0CCE F745 E8 0100000 test dword ptr [ebp-18], 00000001 ; ZF <-- (var3 & 1) == 0 001B0CD5 74 0B je short 001B0CE2 001B0CD7 0FB606 movzx eax, byte ptr [esi] 001B0CDA 3A07 cmp al, [edi] 001B0CDC 74 04 je short 001B0CE2 ; , 001B0CDE 33C0 xor eax, eax 001B0CE0 EB 05 jmp short return2 001B0CE2 B8 01000000 mov eax, 1
:
return2: 001B0CE7 8D65 F4 lea esp, [ebp-0C] 001B0CEA 5B pop ebx 001B0CEB 5E pop esi 001B0CEC 5F pop edi 001B0CED 5D pop ebp 001B0CEE C3 ret JIT_RngChkFail: 001B0CEF E8 C4B1DB61 call clr.JIT_RngChkFail 001B0CF4 CC int3
CRT memcmp()
, , , , , , .
, 0x76C20000 C:\Windows\SysWOW64\msvcrt.dll 7.0.7601.17744.
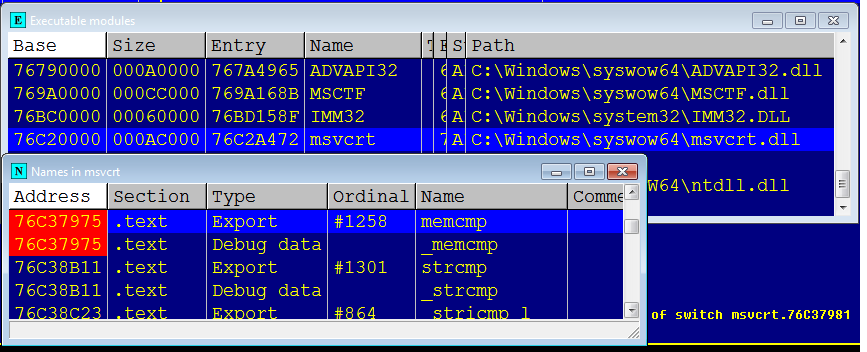
, , .. , , .
: -, , , , -, . «» , switch 32 case' .
:
76C37975 . 8BFF mov edi, edi ; <--(!) INT msvcrt.memcmp(buf1,buf2,count) 76C37977 . 55 push ebp 76C37978 . 8BEC mov ebp, esp
, , .. , nop, 2 . , , . . nop.
It's a hot-patch point.
The MOV EDI, EDI instruction is a two-byte NOP, which is just enough space to patch in a jump instruction so that the function can be updated on the fly. The intention is that the MOV EDI, EDI instruction will be replaced with a two-byte JMP $-5 instruction to redirect control to five bytes of patch space that comes immediately before the start of the function. Five bytes is enough for a full jump instruction, which can send control to the replacement function installed somewhere else in the address space.
blogs.msdn.com/b/oldnewthing/archive/2011/09/21/10214405.aspx
switch
Address Hex dump Command Comments 75A9797C . 8B7D 10 mov edi, [ebp+10] ; edi <-- length 75A9797F . 8BC7 mov eax, edi 75A97981 . 83E8 00 sub eax, 0 ; 75A97984 . 0F84 E7070100 je msvcrt.zeroResult_GoReturn ; (length == 0)=> {result <-- 0, goto return;} (!) ; ; 75A979BC . 83FF 1F cmp edi, 1F ; Switch (cases 1..1F, 32. exits) 75A979BF . 77 5B ja short msvcrt.75A97A1C 75A979C1 . FF24BD 1F8AA975 jmp near [edi*4+msvcrt.75A98A1F] ; (!) (!) ; ; 75A98A1F . 1C7AA975 dd msvcrt.75A97A1C ; (00) , jump 75A98A23 . E88AA975 dd msvcrt.75A98AE8 ; (01) 75A98A27 . CA8AA975 dd msvcrt.75A98ACA ; (02) 75A98A2B . 8C8BA975 dd msvcrt.75A98B8C ; (03) 75A98A2F . 0A7AA975 dd msvcrt.75A97A0A ; (04) 75A98A33 . 088FA975 dd msvcrt.75A98F08 ; (05) 75A98A37 . B88AA975 dd msvcrt.75A98AB8 ; (06) 75A98A3B . 758BA975 dd msvcrt.75A98B75 ; (07) 75A98A3F . F479A975 dd msvcrt.75A979F4 ; (08) 75A98A43 . 238FA975 dd msvcrt.75A98F23 ; (09) 75A98A47 . 9F8AA975 dd msvcrt.75A98A9F ; (0A) 75A98A4B . A18BA975 dd msvcrt.75A98BA1 ; (0B) 75A98A4F . DE79A975 dd msvcrt.75A979DE ; (0C) 75A98A53 . 3A8FA975 dd msvcrt.75A98F3A ; (0D) 75A98A57 . FD8AA975 dd msvcrt.75A98AFD ; (0E) 75A98A5B . ED8EA975 dd msvcrt.75A98EED ; (0F) 75A98A5F . C879A975 dd msvcrt.75A979C8 ; (10) 75A98A63 . 518FA975 dd msvcrt.75A98F51 ; (11) 75A98A67 . BA8EA975 dd msvcrt.75A98EBA ; (12) 75A98A6B . 6A98A975 dd msvcrt.75A9986A ; (13) 75A98A6F . 8990A975 dd msvcrt.75A99089 ; (14) 75A98A73 . CD98A975 dd msvcrt.75A998CD ; (15) 75A98A77 . D58EA975 dd msvcrt.75A98ED5 ; (16) 75A98A7B . 8598A975 dd msvcrt.75A99885 ; (17) 75A98A7F . 1899A975 dd msvcrt.75A99918 ; (18) 75A98A83 . E898A975 dd msvcrt.75A998E8 ; (19) 75A98A87 . 698FA975 dd msvcrt.75A98F69 ; (1A) 75A98A8B . 9D98A975 dd msvcrt.75A9989D ; (1B) 75A98A8F . 3399A975 dd msvcrt.75A99933 ; (1C) 75A98A93 . 0099A975 dd msvcrt.75A99900 ; (1D) 75A98A97 . 848FA975 dd msvcrt.75A98F84 ; (1E) 75A98A9B . B598A975 dd msvcrt.75A998B5 ; (1F)
, :
- (overhead) «» (PInvoke)
- .
関数を呼び出すオーバーヘッドを推定するために、マネージコードから関数自体の開始までコードをトレースすることにしました。これを行うために、関数の先頭にブレークポイントが設定され、Thread.Sleep()から戻った後、トレースが開始されました。ただし、最初のトレース試行の結果は失敗しました。トレースログが大きすぎて(約10万行)、DllMain()が実行されたことを示している可能性があり、一部のCLRコードがキャプチャされた可能性もあります。 JITコンパイラコード。そこで何が正確に行われたのか、私は発見し始めませんでした。このような開始コードは1回だけ実行され、全体像にはほとんど影響しません。このコードを除外するために、Thread.Sleep()を呼び出して再度トレースする前に、memcmp()への別の呼び出しを挿入しました。その結果、100行を少し超えました。
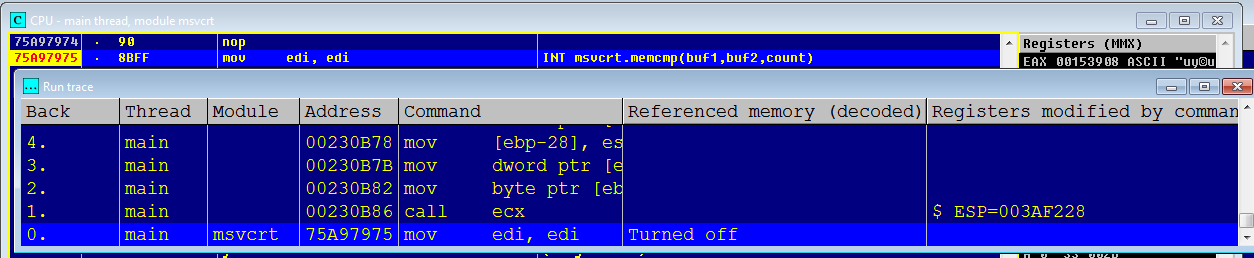
トレースログの一部:
main 00480AEA call 0031C19C ESP=0016F368 ; main clr.628C3B5F call near [eax+14] ESP=0016F248 ; (1) ; main 00480B87 mov eax, [ebp-1C] EAX=00313880 main 00480B8A mov eax, [eax+14] EAX=0031391C main 00480B8D mov ecx, [eax] ECX=75A97975 ; (2) main 00480B8F push dword ptr [ebp+0C] ESP=0016F328 main 00480B92 push dword ptr [ebp+8] ESP=0016F324 main 00480B95 push edi ESP=0016F320 main 00480B96 push dword ptr [ebp-10] ESP=0016F31C main 00480B99 mov dword ptr [ebp-2C], 0 main 00480BA0 mov [ebp-28], esp main 00480BA3 mov dword ptr [ebp-24], 480BB0 main 00480BAA mov byte ptr [ebx+8], 0 main 00480BAE call ecx ESP=0016F318 ; (3) main msvcrt.memcmp mov edi, edi -------- Logging stopped
上記のログから、まず、関数への途中で少なくとも1つの間接呼び出しが発生し、次に、CLRが何らかのデータ構造から最終関数のアドレスを抽出することがわかります。課題にはかなりの間接性があり、移行予測ユニットにその使命を果たす希望を残しません。これにより、一度に大量のデータを処理せず、多くの計算時間を必要としない場合、マネージコードの範囲外でそのような関数を使用するのは無意味になります。
メイン機能コードの評価
, , . . . , .
, , . , -, , , , -, , , , .
変更された配列比較関数
private static bool CompareArraysWithPInvokeMethod() { var result = true; for (int i = CountArrays - 1; i >= 0; i--) // for (int j = 0; j < CountArrays; j++) { var tmp = ByteArrayCompareWithPInvoke(s_arrays[i], s_arrays[j]); result = result && tmp; } return result; }
最初のトレース(ベストケース)
main msvcrt.memcmp mov edi, edi main msvcrt.75A97977 push ebp ESP=0041EC74 main msvcrt.75A97978 mov ebp, esp EBP=0041EC74 main msvcrt.75A9797A push esi ESP=0041EC70 main msvcrt.75A9797B push edi ESP=0041EC6C main msvcrt.75A9797C mov edi, [ebp+10] EDI=00080000 ; edi <-- count main msvcrt.75A9797F mov eax, edi EAX=00080000 ; eax <-- edi main msvcrt.75A97981 sub eax, 0 ; if (eax == 0) {result <-- 0; return;} main msvcrt.75A97984 je msvcrt.zeroResult_GoReturn main msvcrt.75A9798A dec eax EAX=0007FFFF main msvcrt.75A9798B je msvcrt.75A98C10 main msvcrt.75A97991 dec eax EAX=0007FFFE main msvcrt.75A97992 je msvcrt.75A9E610 main msvcrt.75A97998 dec eax EAX=0007FFFD main msvcrt.75A97999 je msvcrt.75A9E5DF main msvcrt.75A9799F dec eax EAX=0007FFFC main msvcrt.75A979A0 je msvcrt.75A98BD2 main msvcrt.75A979A6 mov ecx, [ebp+0C] ECX=034C53B8 ; ecx <-- buf1 main msvcrt.75A979A9 mov eax, [ebp+8] EAX=05C41038 ; eax <-- buf2 main msvcrt.75A979AC push ebx ESP=0041EC68 main msvcrt.75A979AD push 20 ESP=0041EC64 ; main msvcrt.75A979AF pop edx EDX=00000020, ESP=0041EC68 ;-------------------------------- main msvcrt.75A979B0 cmp edi, edx main msvcrt.75A979B2 jae msvcrt.75A993A7 main msvcrt.75A993A7 mov esi, [eax] ESI=4241403F main msvcrt.75A993A9 cmp esi, [ecx] main msvcrt.75A993AB jne msvcrt.75AA80E7 ; main msvcrt.75AA80E7 movzx esi, byte ptr [eax] ESI=0000003F main msvcrt.75AA80EA movzx ebx, byte ptr [ecx] EBX=00000001 main msvcrt.75AA80ED sub esi, ebx ESI=0000003E ; DWORD' main msvcrt.75AA80EF jne msvcrt.75AA8178 main msvcrt.75AA8178 xor ebx, ebx EBX=00000000 ; ebx main msvcrt.75AA817A test esi, esi main msvcrt.75AA817C setg bl EBX=00000001 main msvcrt.75AA817F lea ebx, [ebx+ebx-1] main msvcrt.75AA8183 mov esi, ebx ESI=00000001 main msvcrt.75AA8185 test esi, esi main msvcrt.75AA8187 jne msvcrt.75A98AB1 main msvcrt.75A98AB1 mov eax, esi EAX=00000001 main msvcrt.75A98AB3 jmp msvcrt.75A97A1E main msvcrt.75A97A1E pop ebx EBX=00852AE0, ESP=0041EC6C main msvcrt.return1 pop edi ESP=0041EC70, EDI=034C53B8 main msvcrt.75A97A20 pop esi ESP=0041EC74, ESI=034C53B0 main msvcrt.75A97A21 pop ebp ESP=0041EC78, EBP=0041ECC4 main msvcrt.75A97A22 ret ESP=0041EC7C
ここで最初に目を引くのは、特殊なケースの処理です。パラメータカウントが[0..4]内にある場合、非常にまれになります。これがswitch句のコンパイルの結果なのか、ローカル変数が実際にセットアップされたのかを推測することしかできません。ローカル変数はチェックの各ステップで減少しました。ただし、デバッグ情報は、それがまだスイッチであると主張しています。最適化の観点から、これは非常に合理的なアクションです。ループの初期化は実行されません。
すぐに私の目を引いた2番目のことは、(スタックを介して)番号0x20をedxレジスタに入力する非常に珍しい方法でした。これは、ある種のコンパイルアーティファクトと非常によく似ており、関数がアセンブラーで記述されていないことを明確に示しています。人はこれを書かないでしょう、なぜならこれは無意味です。スタックはメモリ内にあり、スタックへのアクセスは常にレジスタよりも遅くなります。これがインラインアーティファクトであることを提案しようと思います。
0x75AA8178, esi ebx , . , , , , . , , . , DWORD' , .
;Address Hex dump Command Comments 75AA80E7 > 0FB630 movzx esi, byte ptr [eax] 75AA80EA . 0FB619 movzx ebx, byte ptr [ecx] 75AA80ED . 2BF3 sub esi, ebx ; DWORD' 75AA80EF .- 0F85 83000000 jne msvcrt.75AA8178 ; ebx 75AA80F5 > 0FB670 01 movzx esi, byte ptr [eax+1] 75AA80F9 . 0FB659 01 movzx ebx, byte ptr [ecx+1] 75AA80FD . 2BF3 sub esi, ebx 75AA80FF .- 0F84 1EF9FEFF je msvcrt.75A97A23 ; 75A97A23 > 0FB670 02 movzx esi, byte ptr [eax+2] 75A97A27 . 0FB659 02 movzx ebx, byte ptr [ecx+2] 75A97A2B . 2BF3 sub esi, ebx 75A97A2D .- 74 15 je short msvcrt.75A97A44 ; 75A97A44 > 0FB670 03 movzx esi, byte ptr [eax+3] 75A97A48 . 0FB659 03 movzx ebx, byte ptr [ecx+3] 75A97A4C . 2BF3 sub esi, ebx 75A97A4E .- 0F84 5F190000 je msvcrt.75A993B3 ; - 75A97A54 . 33DB xor ebx, ebx ; ebx 75A97A56 . 85F6 test esi, esi 75A97A58 . 0F9FC3 setg bl 75A97A5B . 8D5C1B FF lea ebx, [ebx+ebx-1] 75A97A5F . 8BF3 mov esi, ebx 75A97A61 .- E9 4D190000 jmp msvcrt.75A993B3 ; 75A993B1 . |33F6 xor esi, esi 75A993B3 > |85F6 test esi, esi 75A993B5 .-|0F85 F6F6FFFF jne msvcrt.75A98AB1
コードの複製は良くありませんが、恐ろしいことではありませんが、特にバイト数が結果に影響しないため、ダブルバイトを比較するための連続したバイト比較は最良の方法ではありません。したがって、おそらくソースコードがさらに奇妙であるために、このコードが多少奇妙であることはすでに明らかです。
最初に2番目のトレースのログを見てください:ループの1回の繰り返しで8個のダブルワードが比較されますが、これは良いことです:ループが展開されることは明らかです。私はこれがなぜ行われたのかについての仮定はありませんが、これがどのように起こるかについての仮定があります:まず、アセンブラーコードを形成したいくつかのマクロの結果に非常に似ています、そして、 Microsoft Cコンパイラは、以前考えていたほど良くないということです。
2番目のトレース(ループのみ)
;-------------------------------- main msvcrt.75A979B0 cmp edi, edx main msvcrt.75A979B2 jae msvcrt.75A993A7 main msvcrt.75A993A7 mov esi, [eax] ESI=00000000 main msvcrt.75A993A9 cmp esi, [ecx] main msvcrt.75A993AB jne msvcrt.75AA80E7 main msvcrt.75A993B1 xor esi, esi main msvcrt.75A993B3 test esi, esi main msvcrt.75A993B5 jne msvcrt.75A98AB1 main msvcrt.75A993BB mov esi, [eax+4] main msvcrt.75A993BE cmp esi, [ecx+4] main msvcrt.75A993C1 jne msvcrt.75AA811F main msvcrt.75A993C7 xor esi, esi main msvcrt.75A993C9 test esi, esi main msvcrt.75A?993CB jne msvcrt.75A98AB1 main msvcrt.75A993D1 mov esi, [eax+8] main msvcrt.75A993D4 cmp esi, [ecx+8] main msvcrt.75A993D7 jne msvcrt.75A97A9A main msvcrt.75A993DD xor esi, esi main msvcrt.75A993DF test esi, esi main msvcrt.75A993E1 jne msvcrt.75A98AB1 main msvcrt.75A993E7 mov esi, [eax+0C] main msvcrt.75A993EA cmp esi, [ecx+0C] main msvcrt.75A993ED jne msvcrt.75A97B1F main msvcrt.75A993F3 xor esi, esi main msvcrt.75A993F5 test esi, esi main msvcrt.75A993F7 jne msvcrt.75A98AB1 main msvcrt.75A993FD mov esi, [eax+10] main msvcrt.75A99400 cmp esi, [ecx+10] main msvcrt.75A99403 jne msvcrt.75A97BA4 main msvcrt.75A99409 xor esi, esi main msvcrt.75A9940B test esi, esi main msvcrt.75A9940D jne msvcrt.75A98AB1 main msvcrt.75A99413 mov esi, [eax+14] main msvcrt.75A99416 cmp esi, [ecx+14] main msvcrt.75A99419 jne msvcrt.75A97C29 main msvcrt.75A9941F xor esi, esi main msvcrt.75A99421 test esi, esi main msvcrt.75A99423 jne msvcrt.75A98AB1 main msvcrt.75A99429 mov esi, [eax+18] main msvcrt.75A9942C cmp esi, [ecx+18] main msvcrt.75A9942F jne msvcrt.75AA1172 main msvcrt.75A99435 xor esi, esi main msvcrt.75A99437 test esi, esi main msvcrt.75A99439 jne msvcrt.75A98AB1 main msvcrt.75A9943F mov esi, [eax+1C] main msvcrt.75A99442 cmp esi, [ecx+1C] main msvcrt.75A99445 jne msvcrt.75A97CFC main msvcrt.75A9944B xor esi, esi main msvcrt.75A9944D test esi, esi main msvcrt.75A9944F jne msvcrt.75A98AB1 main msvcrt.75A99455 add eax, edx EAX=031353B8 main msvcrt.75A99457 add ecx, edx ECX=031353B8 main msvcrt.75A99459 sub edi, edx EDI=0007FFE0 main msvcrt.75A9945B jmp msvcrt.75A979B0
大量のテストデータで、このコードは、安全でないコードを使用した場合よりも10%ほど悪い結果を示したことは注目に値します。データ配列を比較するときのほとんどの時間は、メモリからの読み取り操作を必要とすることは明らかです。これは、プロセッサキャッシュ、特にレジスタよりもはるかに遅いです。しかし、プロセッサレジスタを使用した操作によってのみ与えられたこのような重大な違いは、コンパイラの最適化が非常に重要であることを示唆しています。たとえば、クロック速度が遅いプロセッサなど、より弱いプロセッサでテストを行うと、はるかに大きな違いが生じることを提案しようと思います。
結論
- 小さい(7バイト以下)配列をすばやく比較する必要がある場合は、最も明白な方法(ループ内のバイト比較)を使用します。大きい配列は安全ではなく、他のすべては巧妙です。
- .Net CLR . , JIT- , , CLR «» . . JIT- , . — C++- Intel, , (AMD Intel) .
- C-RunTime , , C- – MS VC. « » (http://rsdn.ru/article/optimization/optimization.xml): « , , ».
- Intel® 64 and IA-32 Architectures Software Developer Manuals .CHAPTER 2. Intel ® 64 Architecture
- AMD64 Architecture Programmer's Manual Volume 1 : Application Programming CHAPTER 1 Long Mode
- Intel® 64 and IA-32 Architectures Optimization Reference Manual . CHAPTER 3. Alignment
- Windows Internals, Sixth Edition, Part 1, CHAPTER 5 Processes, Threads, and Jobs
- Windows Internals, Sixth Edition, Part 2, CHAPTER 10. Memory Management
- Intel® 64 and IA-32 Architectures Software Developer Manuals. CHAPTER 17. TIME-STAMP COUNTER
- MSDN Magazine 2005, May: Drill Into .NET Framework Internals to See How the CLR Creates Runtime Objects
- Joe Duffy, Professional .NET Framework 2.0 (Programmer to Programmer). Chapter 3: Inside the CLR, Just-In-Time (JIT) Compilation
21.03.2014 4:37
- , «CRL».
- ( ), MSDN.
- .
前回、コメントに間違ったソースを投稿しました。事実、私は知らなかった、または部分的に書いた実験の過程で、ソースコードは記事から結果を得るのに適していないということです。例:
- メソッドへのいくつかの呼び出しはコメント化されました
DoMeasurements()
。result.SequenceEqualTime = result.IStructuralEquatableTime = result.PInvokeTime;
- このメソッド
PrepareTestData(int p_ArraySize)
は、最初のバイトとは異なる配列を生成しました。 - 定数は、配列の開始サイズが512 * 1024で、配列が64のみになるように設定されました。
- このメソッドは
CompareArraysWithPInvokeMethod()
、異なる配列が最初に比較されるように変更されています。理論的には、これは最終データにあまり影響しないはずです。
, , , .
, Saladin GitHub , , .
25.03.2014 6:37
RtlCompareMemory()
.
, , SuppressUnmanagedCodeSecurity
memcmp()
RtlCompareMemory()
, , user-mode kernel-mode, CRT.
メモリの両方のブロックが常駐している場合、RtlCompareMemoryの呼び出し元は任意のIRQLで実行できます。
猫の下での結果
Unsafe MemCMP RtlCompareMemory 1 279 1 : 001,7 1 : 003,2 1 : 008,8 1 : 001,0 1 278 1 : 001,8 1 : 003,2 1 : 008,9 1 : 001,0 2 325 1 : 001,3 1 : 002,9 1 : 006,1 1 : 001,0 4 374 1 : 001,1 1 : 002,6 1 : 009,0 1 : 001,0 7 422 1 : 001,0 1 : 002,5 1 : 007,0 1 : 001,1 12 426 1 : 001,0 1 : 002,5 1 : 006,9 1 : 001,7 19 490 1 : 001,0 1 : 002,2 1 : 006,0 1 : 001,9 32 560 1 : 001,0 1 : 002,0 1 : 005,3 1 : 002,7 54 622 1 : 001,0 1 : 002,0 1 : 005,4 1 : 003,8 89 802 1 : 001,0 1 : 001,7 1 : 004,3 1 : 004,7 147 1092 1 : 001,0 1 : 001,5 1 : 003,7 1 : 004,0 242 1571 1 : 001,0 1 : 001,4 1 : 003,0 1 : 004,2 398 2328 1 : 001,0 1 : 001,4 1 : 002,7 1 : 004,5 657 3664 1 : 001,0 1 : 001,2 1 : 002,2 1 : 004,6 1082 5519 1 : 001,0 1 : 001,2 1 : 002,1 1 : 005,0 1782 8554 1 : 001,0 1 : 001,2 1 : 002,1 1 : 005,3 2936 13520 1 : 001,0 1 : 001,2 1 : 002,0 1 : 005,5 4837 21771 1 : 001,0 1 : 001,2 1 : 002,0 1 : 005,6 7967 35464 1 : 001,0 1 : 001,2 1 : 001,9 1 : 005,7 13124 58073 1 : 001,0 1 : 001,2 1 : 001,9 1 : 005,7 21618 96457 1 : 001,0 1 : 001,2 1 : 001,9 1 : 005,7 35610 167952 1 : 001,0 1 : 001,1 1 : 001,8 1 : 005,4 58656 285282 1 : 001,0 1 : 001,1 1 : 001,8 1 : 005,3 96617 534712 1 : 001,0 1 : 001,1 1 : 001,6 1 : 004,7 159146 924569 1 : 001,0 1 : 001,1 1 : 001,6 1 : 004,5 262143 1520968 1 : 001,0 1 : 001,1 1 : 001,6 1 : 004,5
デバッガーウィンドウのスクリーンショットでは、ライブラリバージョン 

機能は驚くほど小さいことが判明しました。すべてがここにあります。この関数は、繰り返しプレフィックス(
cmps*
)を使用して文字列比較演算を積極的に使用します。メモリの比較は直接の順序で行われます。これは、コマンドによってリセットされるDFフラグによって決定され
cld
ます。この関数のサイズと単純さは、それがアセンブリ言語で書かれていることを示唆していますが、それについてはわかりません。
文字列比較操作のアルゴリズムは非常に簡単です。たとえば、次のコマンドで指定されたDWORDを順方向に比較します。
repe cmpsd ; ecx DWORD';
Javaでは、次のように表すことができます。
while ( ( 0 != ecx ) & ( 0 == Compare( (DWORD) RAM[esi], (DWORD) RAM[edi] ) ) ) { --ecx; edi += 4; esi += 4; }
単語とバイトの配置を想像できるほぼ同じ方法。
カットの下でのコメントと悲惨
push esi ; push edi cld ; DF <-- 0 mov esi, [esp+0C] ; esi <-- Source1 mov edi, [esp+10] ; edi <-- Source2 mov ecx, [esp+14] ; ecx <-- SIZE_T shr ecx, 2 ; ecx <-- (ecx >> 2) ( 4) jz short smaller_4 ; repe cmpsd ; ecx DWORD'; jne short not_zero ; if ( !ZF ) goto not_zero; smaller_4: mov ecx, [esp+14] ; ecx <-- SIZE_T and ecx, 00000003 ; ecx &= 3 jz short return_SIZE_T ; if ( ZF ) goto return_SIZE_T; repe cmpsb ; jne short found_difference return_SIZE_T: mov eax, [esp+14] ; eax <-- SIZE_T pop edi ; pop esi ret 0C ; return eax not_zero: sub esi, 4 ; esi -= 4 sub edi, 4 ; edi -= 4 mov ecx, 4 ; ecx -= 4 repe cmpsb ; found_difference: dec esi ; --esi sub esi, [esp+0C] ; esi <-- (esi - Source1) mov eax, esi ; eax <-- esi pop edi ; pop esi ret 0C ; return eax