街の外の志を同じくする友人とのミーティングは、アイデアを共有したり、記事を書いたり、手が届かない仕事を終えたりするのに適しています。 このため、データマイニングキャンプへの旅行を計画しました。 サウナ、ボードゲーム、コンタクト動物園、そしてプログラムのハイライトであるハッカソンがあることを決めました。
ハッカソンでは、専門家の助けを借りて、3人の研究に取り組みました:属性の階層的クラスタリングのモデル、オンラインコースの学生を退学させるためのモデル、Gradient Boosting Machinesアルゴリズムの改善を試み、Kaggleプラットフォームでの競争にも参加しました。 それがどうであったか、そして彼らがカットの下でこれらのアイデアに取り組んでいる方法について...

楽しい時間...
まず、プライベート動物園に行きました。 そこで戯れ、私の子供時代を思い出しました。誰もが自分の好みに合わせてエンターテイメントを見つけました。 誰かがタヌキのbe食、誰かのラクダ、またはラマが好きでした...

...しかし、勇敢な人たちは、大きくても親切な犬と遊ぶことを敢行しました。

初日の夜、サウナで親密な会話をし、明日のハッカソンの準備をして、到着したゲストに会いました。 翌朝は会話とボードゲームを巡りました。
エンターテインメントプログラムに触発されて、私たちは差し迫った問題について議論し始めました。 Munchkinゲームのすぐ後ろで、会話はデータマイニングの教育と新しい研究のためのアイデアに変わりました。
...そして時間があります!
私たちの中には、バイオインフォマティクス、金融、電気通信、ビッグデータの分野の専門家がいました。彼らは研究経験とお茶を共有しました。 たとえば、 EMCの専門家であるウラジミールスボーロフがトンボのゲノムを解読するという話を聞いた後、まだ解読できるアイデアやバイオインフォマティクスの分野での協力を開始する方法が数多く登場しました。

ロザリンドの専門家が教育経験を共有しました。 機械学習とデータ分析に関する講義は、実践よりも効果が低いと結論付けました。 ハッカソン、コンテスト、専門家による実際のタスク-これは、優れたスペシャリストになるために必要なものです。 質問は未解決のままでした:「オンライン教育とオフライン教育を組み合わせる方法は? コースを開始する前にCourseraで特定のコースを受講することをお勧めしますか? 講義を完全に除外しますか? それとも別の方法がありますか?」
一方、ハッカソンが近づいていたため、2つの独立したストリームに分割することにしました。ハッカソン#1の参加者はミニリサーチを実施し、その結果に関する記事を書き、ハッカソン#2の参加者は国際競争の問題を共同で解決しました。
ハッカソン#1
3つのチームが研究ハッカソンに参加しました。 最初のチームは、データ分析の主なタスクの1つであるキャラクター選択方法に取り組みました。 なぜこれが必要なのですか? 機能、つまりデータセットの列が多すぎると、計算が複雑になったり、不可能になったりする場合があります。 たとえば、サンプルサイズがフィーチャの数より小さい場合。
オリンピックで私たちの国がどのような位置を占めるかを予測したいと考え、より多くの情報を収集することにしました。 経済について:一人当たりGDP、対外債務の量、最低賃金、輸出入の量、移民の数。 地理学:首都の緯度、山が占める面積の割合、全国の面積。 過去のオリンピックについて:各ランクのメダルの数、アスリートの数、その国を代表するスポーツの数、開催地... そして、これは率直に言って、方程式の数が未知数の数よりも少なくなり、システムの非互換性または無限の数の解をもたらすため、良くありません。
余分な情報を取り除く必要があります。 通常、情報基準( AIC 、 BIC )を使用して、最適な機能セットを持つモデルを選択します。 最良の方法は、最小限の機能でデータを十分に完全に記述するモデルです。 または、モデルに組み込まれている正則化方法を使用します。つまり、モデル自体が誤ったデータに対処することを望んでいます。 または、主成分分析(PCA)を使用してデータディメンションを下げます。 主成分法の本質は、2つの機能を備えた例によって最も簡単に伝えられます。
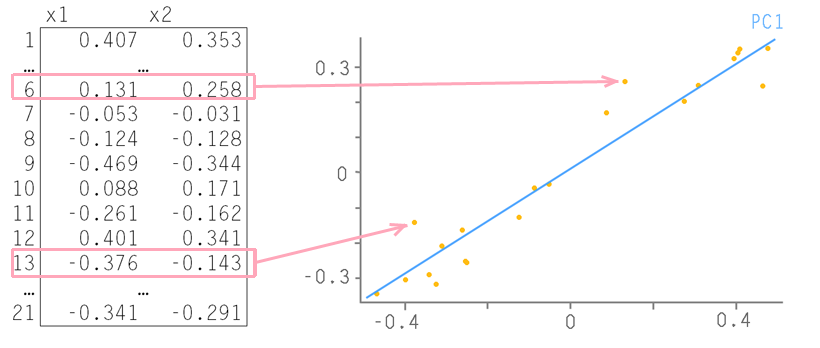
表の各行は、平面上の点に対応しています。 最大のデータ変更がそれに沿って発生するように、それらを通る直線を描画します。これは最初の主要コンポーネント-PC1と呼ばれます。 次に、この軸上のすべてのソースポイントを投影します。 新しい軸からのすべての偏差はノイズと見なされます。 これが本当にノイズであるかどうかを確認することができます。初期データで行ったのと同じ方法でこれらの残基を操作したので、それらの最大変化の軸を見つけます。 2番目のメインコンポーネント(PC2)と呼ばれます。 そのため、ノイズがすでに実際にノイズになるまで、つまりランダムなカオス的な量のセットになるまで行動する必要があります。 ここから例を取り上げます 。ここでは 、主成分の方法について詳しく読むことができます。
主成分法のように機能を変更したくない場合、またはモデルに組み込みの正則化(ニューラルネットワークなど)がなく、再トレーニングを簡単に受ける場合は、他のアプローチが必要です。 私たちは、属性の階層的クラスタリングのモデルを開発し、その後で最も成功した属性のサブセットを検索することにしました。
結果のアルゴリズムをさらに詳しく考えてみましょう。 階層はクラスタリングアルゴリズムを使用して形成されますが、最も一般的なのはk-means法です。 クラスターの数kは事前にわかっています; k = 2に設定するとします。 モデルから2つの属性をランダムに選択し、それらの周囲にクラスターを形成し始めます。 総二次偏差が最小になるまで、クラスターの中心を移動します。 この場合の記号は、n次元空間のポイントに変わります。ここで、nはテーブル内のエントリの数、つまりオリンピアードに参加している国の数です。 k-meansアルゴリズムのメカニズムはここにあります 。
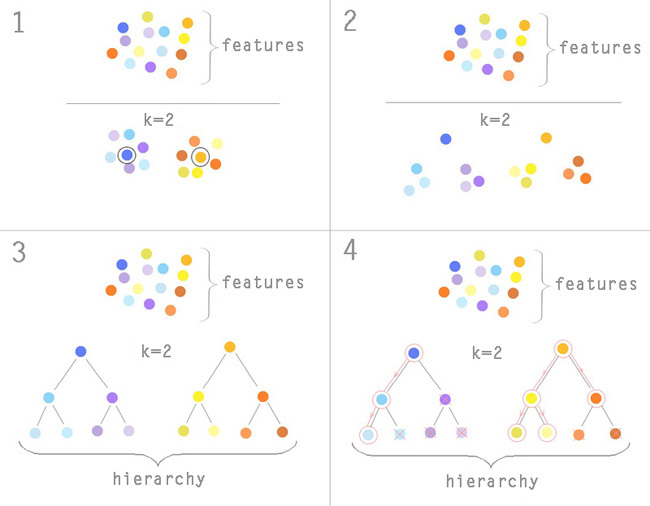
現在、サインは2つのグループに分けられています。 それらのそれぞれで、クラスターの中央値への近接性の原則に従って、1つの特徴的な特徴を選択しました(1) 。 繰り返しますが、結果の各グループをクラスター化し、特徴的な特徴を除外します(2) 。 サブグループ内のサインの数が2以上になるまで繰り返します。
その結果、より低いレベルへのノードがすべて重要度の低い兆候であるツリーを取得します(3) 。 その後、選択が行われます。 8つの標識を残す必要があるとします。 最初に、モデルは階層の最上位からの標識でのみ訓練されます。 それらのそれぞれについて、モデルへのフィーチャの寄与に基づいて決定が行われます。モデルに残す、サブグループを削除する、またはサブグループに深く入ります。 貢献が十分に大きい場合-そのまま残し、真ん中の場合-離れてサブグループに深く入り、それが非常に小さい場合-サブグループ全体を一緒に捨てます。 モデルの予測誤差が減少し、選択された符号の数が8未満になるまで、ツリーを下っていきます(4) 。
2番目のチームは、例として3つのプラットフォームを使用してMOOC(大規模オープンオンラインコース)ユーザー出口モデルを作成するために取り組みました: Coursera 、 Rosalind、およびStepic 。 このタスクは現在、オンライン教育に非常に関連しています。インタビューの1つで、Daphne Koller氏はCourseraのコースを修了するユーザーはわずか7%であると述べました。 目標は、アクティビティを追跡してボトルネックを見つけるために、トレーニングのさまざまな段階でのユーザーの行動を記述するモデルを作成することです。
ハッカソンでは、ロサリンドプラットフォームのデータを調査しました。これは、主に実用的な問題の解決を支援するバイオインフォマティクスの準備を目的としています。 ハッカソン中に、彼らはモデルの属性のリストとターゲット変数のオプションを決定しました。 モデルを構築するために、以下を特徴付ける3種類の機能が識別されました。
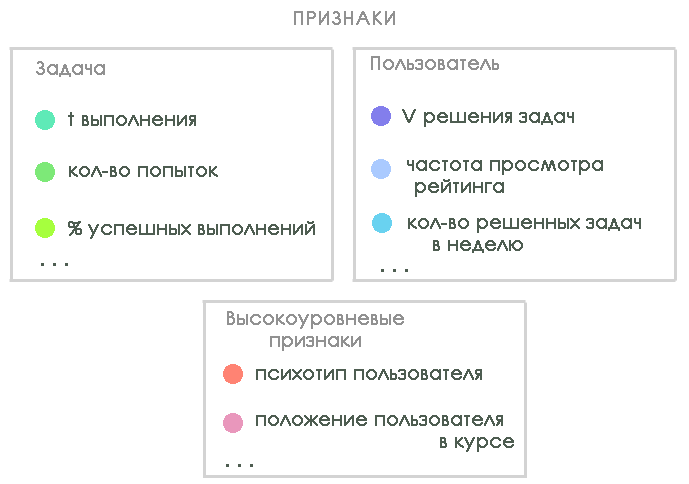
ハッカソンでは、すべての兆候がカウントされたわけではありません(十分な能力と作業手がなかった)が、男たちがさらなる研究に行くべき場所が明らかになりました。
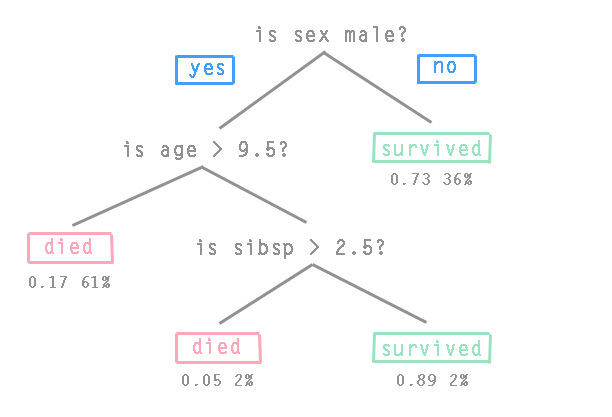
3番目のチームは、 勾配ブースティングアルゴリズムの改善を試みました。 このアルゴリズムは、「base-learner」または「base bricks」と呼ばれる「弱い」予測モデルのアンサンブルから予測モデルを構築します。 弱いモデルはトレーニングセットでトレーニングされ、最終予測モデルが各反復でより正確になるように結合されます。 通常、勾配ツリーブースティングアルゴリズムが使用されます。このアルゴリズムでは、固定サイズのCART決定ツリーが「基本的なブリック」です。 決定木のノードには遷移条件が含まれ、葉には目的関数の値が含まれます。 写真では、タイタニック号の乗客に関する決定ツリーの典型的な例です(sibspは船上の親ofの数です):
彼らは、アンサンブルのコンポーネントをさまざまな方法で混合することにより、モデルの精度を高めることができるかどうかを考えました。 アンサンブルがSVM回帰、線形モデル、およびさまざまなツリーバリアントで構成される場合、GBM(勾配ブースティングマシン)バリアントが検討されました。 これまでのところ、標準のGBMを打ち負かすことはできませんでしたが、ハッカソン終了後も作業は沸騰し続けています。
3つのチームすべての目標は、北京で夏に開催される機械学習ICMLに関する国際会議に参加するための記事を書くことでした。
ハッカソン#2

2番目のハッカソンは、KaggleクラウドソーシングプラットフォームでのYandexとの競争に捧げられました。 タスクは、ユーザー設定に基づいて検索結果でWebページをランク付けすることです。 Yandexは27日間で約600万人のユーザーの履歴を提供しました。これは約2,100万件のリクエストです。 各リクエストには、ユーザーID、リクエスト内の単語のリスト、出力からの10の位置、ユーザーが選択した位置の番号、各ユーザーアクションの時間がありました。 これに加えて、次の3日間のテストセッションデータが提供されました。
最大のNDCG(正規化された割引累積ゲイン)を取得するために、テストセッションで結果を調整する必要がありました。 それが何であるかをより詳細に検討しましょう。 DCG-割引された累積ゲインまたは減少した合計関連性の有効性は、次の式を使用して計算されます。
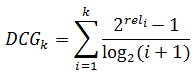
ここで、iは問題のシリアル番号、relはリクエストへの準拠の程度です。 0から3の対応スケールでは、結果の最初の6ページを、たとえば次のように評価できます:3,2,3,0,1,2。 関連性の総有効性の低下を計算します。
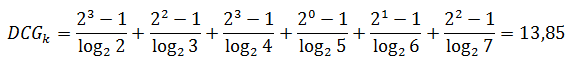
そして、完全なランキングで要約された関連性の有効性:
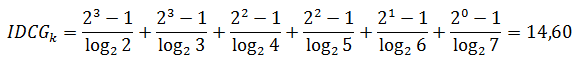
実際のDCGを理想的なものに分割することにより、結果を正規化します。
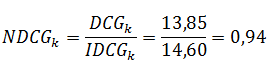
このメトリックは、情報の取得やランキングのランク付けでよく使用されます。
パフォーマンス指標を処理した後、彼らは働き始めました。 準備されたユーザーリクエストログは60ギガバイト以上を占有したため、機械学習アルゴリズムを使用することは困難でした。 締め切り前には何もなかったので、個人的なナビゲーションリクエストにのみデータを残すことにしました。 サンプルの10%、つまり6ギガバイトに達しました。
現在の出力を改善するために、チームは過去に同じクエリ(query_id)を入力したユーザーがいるかどうかを確認することにしました。 多くの場合、そのようになりました。 このユーザーが特定のドキュメントにアクセスした時間、クリック頻度、トレーニングサンプルの他のパラメーターを分析し、このデータを使用して現在の出力をランク付けしました。 最も単純なルールが使用されました。以前に同じリクエストを持つユーザーが何度もアクセスした場合、Webドキュメントは上に移動し、平均訪問時間は400 tsを超えました(タイムスタンプは時間に相当します。ユーザーへのドキュメント)。
競争の結果、私たちのチームはベースラインを上回りました。結果は、Yandexがモデルとして提供したものと比較して0.6%改善されました。 比較のために、リーダーボードの最良の結果はベースラインをわずか1.6%だけ上回っていました。 ここでは、そのような金額のために、サービスの品質を改善するための闘争があります。
印象
翌朝、全員が家に帰りました。 仕事や娯楽、興味深い会話やアイデアの交換に気付かれずに時間が経ちました。

このような会議を開催するというアイデアは成功したように思えたので、非公式の設定で定期的にミニ会議を開催することにしました。 次は春に予定されており、正確な日付を記載した発表をHabréで行います。 私たちは志を同じくする新しい人々に常に満足しています。これについて興味深いアイデアがあれば、コメントで共有してください!