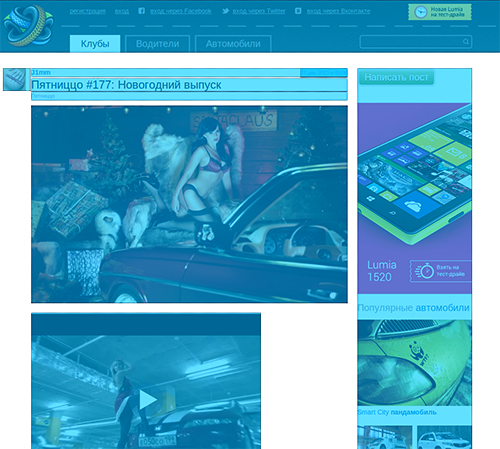
サイトAutoCADABRAのアルゴリズムの例。
挑戦する
おそらく、誰もがWebvisorサービスについて知っているため、サイトへの訪問者のアクションを記録し、ビデオモードで表示できます。 このツールは興味深いものですが、サイトに多くの訪問者がいる場合、サイトの生涯の写真を撮るのは問題です。各ビデオを見ることができず、グループ化することもできません。
訪問者とサイトとの相互作用を追跡し、サイトがどのように生きているかを確認し、同時に多くの訪問者にリーチする能力があると、はるかに便利です。 その結果、アイデアは訪問者のアクションの意味のあるリストの形式で情報を記録するように見えました:
- Dima :sepyraのリクエストでYandex RU検索エンジンからサイトにアクセスします(3分10秒前)
- Dima : Sepyra Web Analytics |公式WebサイトページからAboutページへの移行| Sepyra Web Analytics (1分30秒前)
- Dima :ブロック内のテキスト「 時間 」を強調表示「 Sepyra Webアナリティクスの重要な機能の1つは、訪問者のすべてのステップを認識したい機会です 」(40秒前)
- Dima :「 関税システムに関するFAQ FAQ連絡先ロシア語英語接続ログイン 」(20秒前)の「 接続 」サブブロックへの平均関心
- Dima :「 登録 」フォームの「 あなたの名前 」フィールドの入力/変更(10秒前)
レコードは2つの部分で構成されます。訪問者のアクションが発生するブロックとアクション自体です。たとえば、ブロック「 One of the key features ... 」のテキスト「 time 」を強調表示します。 この説明では、ページ上のブロックとその名前を定義する必要があります。 名前が多かれ少なかれ明確だった場合、ブロックの割り当てについて考える必要がありました。
ソリューションオプション
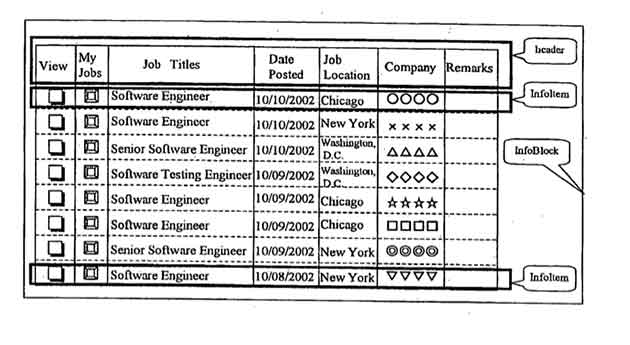
最初のステップは、この問題の既存の解決策を見つけることです。 それらの1つは、「類似のドキュメントを識別するためにWebページをセマンティックブロックに分割する方法」(D. I. Kosinov。Voronezh State University)です。 ここでは、コンテンツが残っている限り、最大の要素が決定され、ページから取り出されます。 <BODY>全体を一度に引き出さないようにするために、可能な限り低いレベルのブロックを選択するために、ノード深度インジケーターが重み関数に導入されました。 実装とテストの過程で、問題がいくつかの場所で発生することが判明しました。まず、重み関数の係数を正しく選択する必要があります。次に、コンテンツを削除した後、ページに「穴」があり、次のブロックが破れていることがわかります(図のブロック4など) 。

その後、彼らの決定がうまくいき始めました。オプションの1つは、特定の長さのコンテンツを持つブロックを選択することでしたが、完全に成功したわけではありませんでした。 ある晩、別の決定が下され、最終決定になりました。 本質はシンプルで、なぜページ上のセマンティックブロックを探すのか、レイアウトが基本的に意味によってブロックを組み合わせる場合、ブロックが壊れているレベルとブロックを判断するだけです。
最終版
Webページをブロックに分割するためのアルゴリズム
アルゴリズムの基本的な考え方は、Webページの共通要素がDOMツリーに共通の親を持つことが多いと想定することです 。 ページ上の孤立したセマンティックブロックの数は、平均してDOMツリーの最下位レベルの要素数の平方根(つまり、子を持たない要素数の平方根)に等しいことが実験的に確立されました。
簡単に言うと、アルゴリズムは次の手順で説明できます。
- DOMツリーのルート要素を配列に入れます
- 配列内の要素の数は、DOMツリーの下位レベルにある要素の数の平方根より少ないですが、次のサイクルを繰り返します。
- 子を持つ最大の重みを持つ要素を選択します。 そうでない場合は、そのままにします。
- 適切な要素が見つかった場合、その要素を配列から削除し、リモート要素の子を配列に追加して、ループの先頭に戻ります。
スプリット関数の例
function getSeparatedNodes(rootObj, numBlocks) { var nodes = [rootObj]; while (nodes.length < numBlocks) { var maxWeightNode = nodes[0]; var nodeIndex = 0; for (var i = 0; i < nodes.length; i++) { if (((nodes[i].weight > maxWeightNode.weight) || (maxWeightNode.lowerChildrenCount == 1)) && (nodes[i].lowerChildrenCount > 1)) { maxWeightNode = nodes[i]; nodeIndex = i; } } if (maxWeightNode.lowerChildrenCount <= 1) { break; } nodes.splice(nodeIndex, 1); nodes = nodes.concat(maxWeightNode.children); } return nodes; }
アイテム重量
重みは、次の要素を子に分割するかどうかを決定し、コンテンツのサイズと要素の領域の両方を考慮に入れます。
Element_weight = log(text_length * 0.1 + 1.01)* log(area * 0.9 + 0.11)。
要素領域には高い優先順位が与えられます;マジックナンバー1.01および0.11は、重みが正の数のままになるように対数を制限します。 空のノードはアルゴリズムによって除外されるため、テキストサイズと面積の最小値は1です。 内部にテキストを含めることができないオブジェクト(画像、埋め込みオブジェクトなど)の場合、 text_lengthパラメーターは面積/ 140 (140は1つのテキスト文字の面積の平均値)と見なされます。 テキストの長さを計算するとき、繰り返されるスペースは除外され、<STYLE>および<SCRIPT>要素の内部テキストも考慮されません。
ブロック名
ブロック名の検索は非常に簡単です。
- ヘッダー要素はブロック内で検索されます(H1-H6)
- タイトル要素が見つからない場合、最大フォントサイズの要素が検索されます
- すべての要素が同じフォントを持っている場合、最大フォント重量の要素が検索されます
- すべてのテキストが同じ太字である場合、テキストの開始と終了が使用されます。
どうした
以下は最終的に出てきたものの例です(写真はクリック可能です):
AutoCadabra
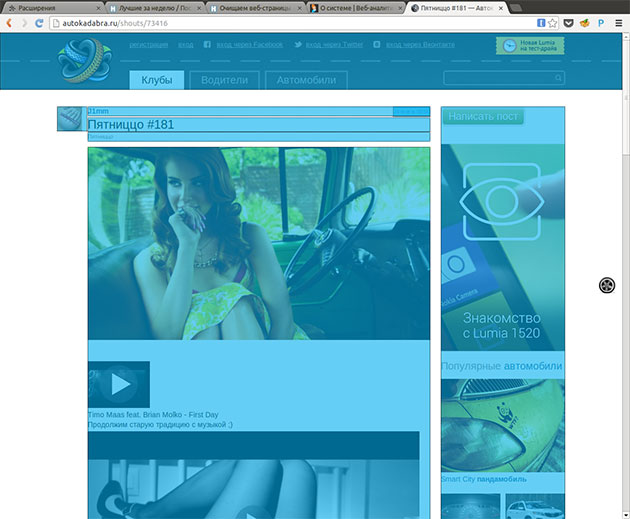
セピラ
Habréに関する記事のリスト

同じアルゴリズムを使用して、ブロックをサブブロックに分割することができます。

他の例と同様に、 ここでライブを見ることができます。
同様のソリューション
また、この主題に関する多くの特許があり、それらは便利です。
- 特許「モバイル通信端末でWebページを表示するための装置と方法」(US 2007/0110037 A1)は、モバイルデバイスで表示するためにWebページをブロックに分割する方法を提供します(以下、各ブロックが独自のキーを持っている場合は便利です)ナビゲーション用);
- 特許US 2011/0289435 A1は、ナビゲーションにTVリモコンを使用する場合、TV画面に表示するためにページをブロックに分割します。
- US 2004/0103371 A1、ページはブロックに分割されますが、画面が小さいデバイスでより適切に表示されるように、ブロックはユーザーの関心に応じてランク付けされます。
- さまざまな画面にウェブページを便利に表示するための特許US 2011/0285750 A1。
- 特許US 2012/0005573 A1は、ユーザーが興味を持っているものを追跡し、ページのこの領域をユーザーに強調表示します。
- US 2006/0149726 A1ヒューリスティック分析を考慮したWebページのセグメンテーション。
- US2005 / 0066269A1(ウェブページから情報ブロックを抽出するためのデバイスおよび方法)、繰り返しパターンに基づいてウェブページを情報ブロックにセグメント化するいくつかの方法が提示されている。
おわりに
アルゴリズムは、非常にシンプルで理解しやすい機能であることが判明しました。これは重要です。 マイナスの点では、あまり安定しておらず、コードの小さな変更に耐えますが、ページにウィジェットを追加するとき、ドキュメントの構造の他の変更、ブロックが異なるように壊れる可能性があります。