講義は高校生-Small ShADの学生を対象としていますが、大人はそれを使用して機械学習の基本を理解することができます。

機械学習の主なアイデアは、トレーニングプログラムとパターン付きデータの例を用意することです。パターンのモデルを構築し、新しいデータでパターンを見つけることができます。
最近傍法
たとえば、単純な問題を解決します。 平面上には、赤と青の2色のドットが点在しています。 それぞれの座標と色は私たちに知られています。 新しいポイントの色を決定する必要があります。 各ポイントは調査対象オブジェクトであり、座標と色はそのパラメーターです。 たとえば、オブジェクトは人、座標は人の髪の毛の長さと長さ、色は人の性別です。
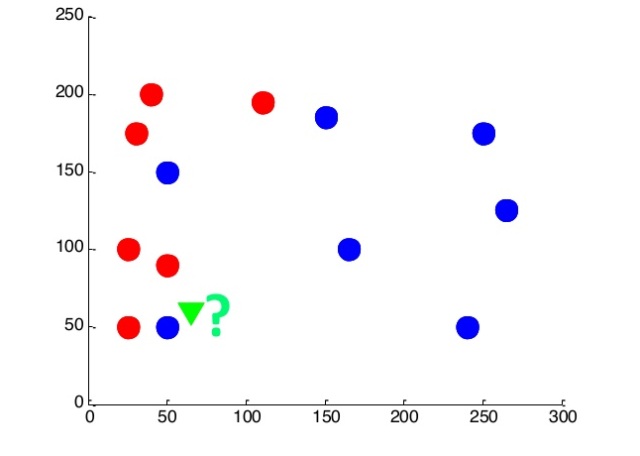
最近傍法で解決してみましょう。 新しいオブジェクトをその最近傍と同じクラスに属します。 平面上の各ポイントの予測を行います。最も近いポイントが青の場合、このポイントに表示される新しいオブジェクトは青です。 そしてその逆。

したがって、2つの領域が得られます。1つは赤色のドットが出現する可能性が高く、もう1つは青色です。
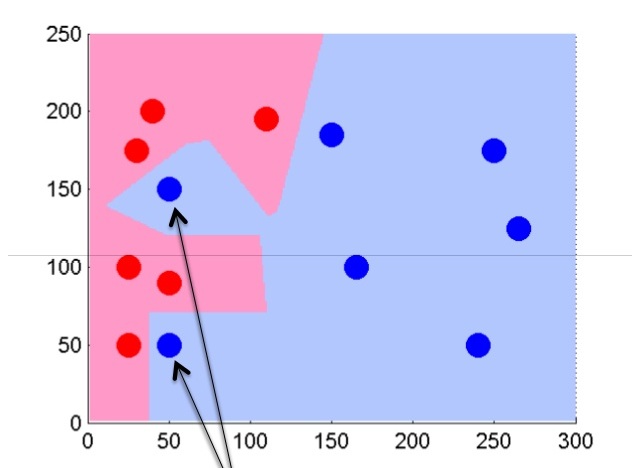
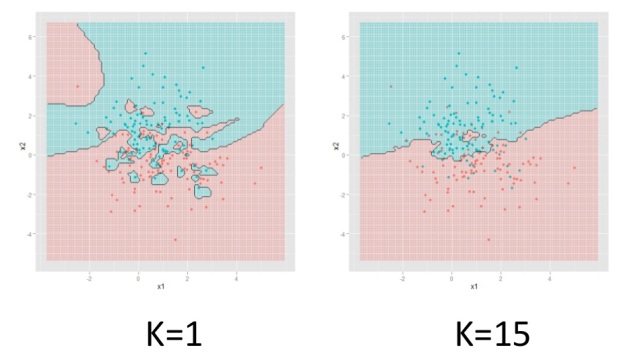
次に、アルゴリズムをわずかに変更して、いくつかの(k)最近傍に焦点を当てましょう。 kを5に等しくします。
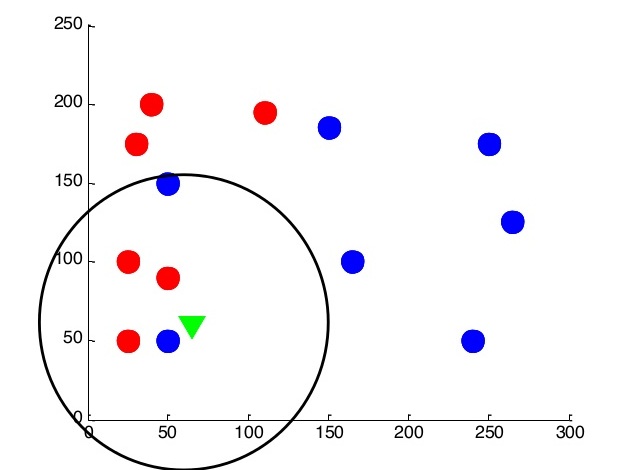
この場合、ノイズの可能性のあるオブジェクトをカットし、より均等なクラス分離境界を取得できます。
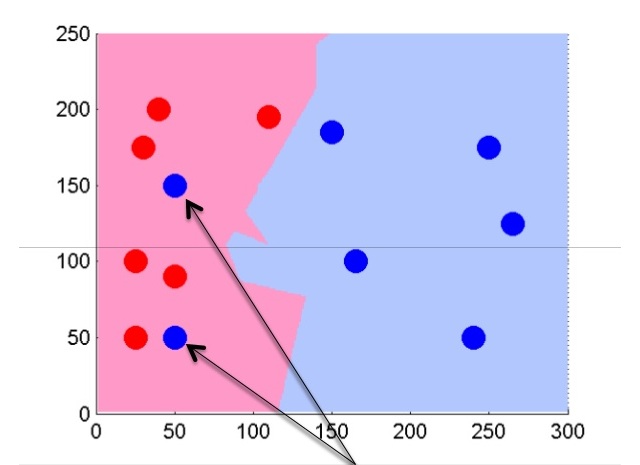
これは、正規分布によって取得された多数のオブジェクトの分離がどのように見えるかです。
アルゴリズムの品質とパラメーター
再び、赤と青のドットが特定の方法で配置された平面があると想像してください。

さまざまな方法でそれらの間に境界を描くことができます。 結果は、アルゴリズムがデータに対してどのように調整されるかに依存します。
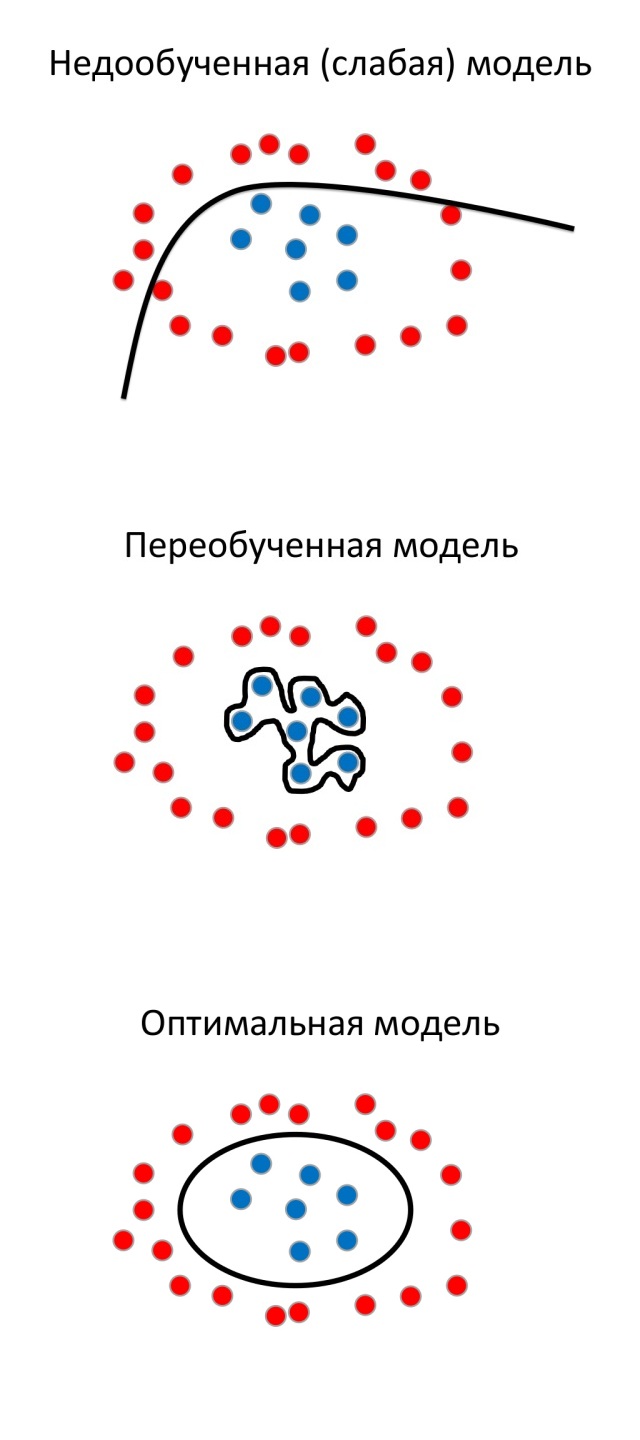
原則として、モデルの再トレーニングの傾向は、そのパラメーターの数に関連しています。 そのため、たとえば、パラメーターの数が少ないモデルは、再トレーニングすることができません
一般的な場合、機械学習の問題では、平面上ではなく、多次元空間内の点が考慮されます。 各座標は記号です。 したがって、トレーニングサンプルは次のように表すことができます。
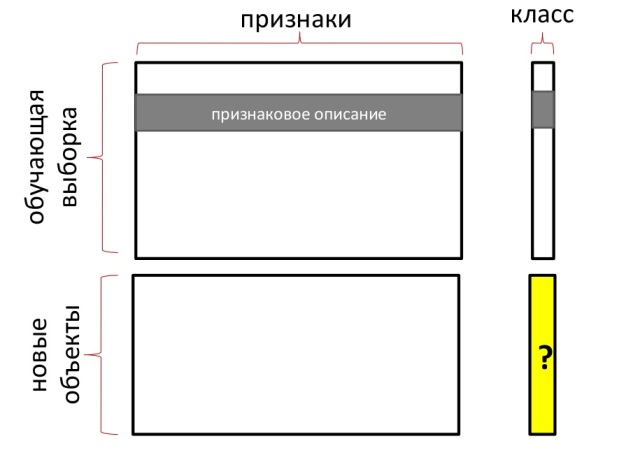
しかし、どのアルゴリズムを選択し、その作業の品質をどのように評価するのでしょうか? このため、ラベル付きのトレーニングサンプルは2つの部分に分割されます。 最初の部分では、トレーニングが直接行われ、2番目の部分はコントロールとして使用されます。 その上で、アルゴリズムが生成したエラーの数をチェックします。
問題解決サイクル
機械学習の問題を解決するおおよそのサイクルは次のようになります。
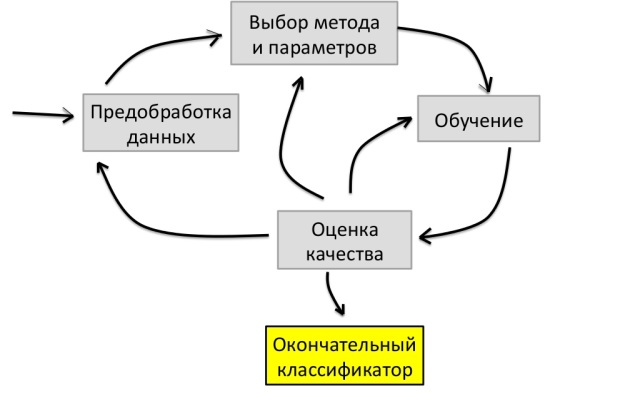
まず、データを前処理してから、分類方法とパラメーターを選択し、トレーニングを実施して品質を評価します。 品質が3倍になると、タスクは完了したと見なされます。 それ以外の場合は、メソッドとパラメーターの選択に戻ります。
より詳細な情報、機械学習の実際の問題の例、および超平面、 ニューラルネットワークに関するストーリー。 ビデオ講義では、ディープラーニング、 Viola-Jonesメソッド 、 決定的なツリー 、ブースティングが利用できます。