 認識問題では、重要な役割はオブジェクトの重要なパラメーターの選択とその数値の評価によって演じられます。 それでも、良い数値データを受け取った後でも、それらを正しく使用できなければなりません。 問題のさらなる解決は簡単であるように思われ、数値データから認識結果を取得するために「一般的な考慮事項から」したい場合があります。 しかし、この場合の結果は最適にはほど遠いです。 この記事では、認識問題の例によって、最も単純な数学モデルを簡単に適用し、それによって結果を大幅に改善する方法を示したいと思います。
認識問題では、重要な役割はオブジェクトの重要なパラメーターの選択とその数値の評価によって演じられます。 それでも、良い数値データを受け取った後でも、それらを正しく使用できなければなりません。 問題のさらなる解決は簡単であるように思われ、数値データから認識結果を取得するために「一般的な考慮事項から」したい場合があります。 しかし、この場合の結果は最適にはほど遠いです。 この記事では、認識問題の例によって、最も単純な数学モデルを簡単に適用し、それによって結果を大幅に改善する方法を示したいと思います。
パターン認識問題について
パターン認識のタスクは、オブジェクトを特定のクラスに割り当てるタスクです。 クラスが属するかどうかを判断するために、特定のオブジェクトパラメータのセットが使用されます。 たとえば、目の間の距離、肌の色、鼻の長さ、虹彩パターン、特徴的な音声の頻度、指の数などのいくつかのパラメータで人を認識することができます。
 これらのパラメーターは、固定次元の数値ベクトルとして表すことができます(数値パラメーターの場合、これは簡単です。虹彩/顔の画像の色/パターンなどについては、これを行う方法を理解する必要があります)。 つまり、特定の数のクラスX 1 、X 2 、... X Nがあり、パラメータ値のセットで記述されたプロトタイプがあります
これらのパラメーターは、固定次元の数値ベクトルとして表すことができます(数値パラメーターの場合、これは簡単です。虹彩/顔の画像の色/パターンなどについては、これを行う方法を理解する必要があります)。 つまり、特定の数のクラスX 1 、X 2 、... X Nがあり、パラメータ値のセットで記述されたプロトタイプがあります  、そして、彼がこれらのクラスのいずれかに属しているかどうかについて彼に言いたい。 通常、クラスはこのクラスのいくつかのサンプルの形式で提示されます。たとえば、異なる角度からのオブジェクトの視覚画像、さまざまなパラメーター測定、虹彩写真のさまざまなコピーなどです。 次に、認識の最も簡単な方法は、受信したオブジェクトを各クラスの各サンプルと比較し、最も近いオブジェクトまでの距離に応じてそれが彼であるかどうかを決定することです。
、そして、彼がこれらのクラスのいずれかに属しているかどうかについて彼に言いたい。 通常、クラスはこのクラスのいくつかのサンプルの形式で提示されます。たとえば、異なる角度からのオブジェクトの視覚画像、さまざまなパラメーター測定、虹彩写真のさまざまなコピーなどです。 次に、認識の最も簡単な方法は、受信したオブジェクトを各クラスの各サンプルと比較し、最も近いオブジェクトまでの距離に応じてそれが彼であるかどうかを決定することです。
一見すると、タスクは無数のクラスを持つ分類タスクのように聞こえます。オブジェクトの各タイプは個別のクラスであり、新しいオブジェクトは各クラスと比較する必要があります。
 これは、特にクラスの数に制限がない場合、かなり難しいタスクです。たとえば、人を認識する場合、データベースにいない人、つまり別のクラスの人が通過できます。 しかし実際には、調査対象のオブジェクトとクラスサンプルとの差dxを計算し、それが同じオブジェクトであるか異なるかを判断します。 たとえば、指紋で人を認識したい場合、結果の指紋を特定のデータベースからのすべての指紋と比較し、指紋の各ペア間の類似性の尺度を計算し、最も類似した指紋のこの類似性の尺度について、同じであると判断します印刷物が非常に類似している場合、または最も類似した印刷物がまだ類似していない場合、この人物がデータベースにない場合。 つまり、分類器はオブジェクトxのパラメーターを入力として受け入れませんが、2つのオブジェクトのパラメーターの差dx = x-x i (各コンポーネントの差のモジュールを取り、減算順序が重要でないようにすることをお勧めします)、これらのパラメーターの特性(類似性の尺度)を提供します)、決定を下すことができます:これらは同じオブジェクトまたは異なるオブジェクトです。
これは、特にクラスの数に制限がない場合、かなり難しいタスクです。たとえば、人を認識する場合、データベースにいない人、つまり別のクラスの人が通過できます。 しかし実際には、調査対象のオブジェクトとクラスサンプルとの差dxを計算し、それが同じオブジェクトであるか異なるかを判断します。 たとえば、指紋で人を認識したい場合、結果の指紋を特定のデータベースからのすべての指紋と比較し、指紋の各ペア間の類似性の尺度を計算し、最も類似した指紋のこの類似性の尺度について、同じであると判断します印刷物が非常に類似している場合、または最も類似した印刷物がまだ類似していない場合、この人物がデータベースにない場合。 つまり、分類器はオブジェクトxのパラメーターを入力として受け入れませんが、2つのオブジェクトのパラメーターの差dx = x-x i (各コンポーネントの差のモジュールを取り、減算順序が重要でないようにすることをお勧めします)、これらのパラメーターの特性(類似性の尺度)を提供します)、決定を下すことができます:これらは同じオブジェクトまたは異なるオブジェクトです。  これは、「同一のオブジェクトのペア」と「異なるオブジェクトのペア」という2つのクラスを持つ分類問題と見なすことができます。 さらに、「同一のペア」のクラスはゼロに近くグループ化され、異なるものは-反対に、傍観者のどこかになります。 従来、分類子は類似性の数値的尺度(たとえば、0から1)を提供する必要があります。これは、これらが異なるオブジェクトである可能性が高いほど大きくなります。 さらに、システムの要件に応じて、 第1種および第2種のエラーが依存する決定を行うためのしきい値が決定されます。
これは、「同一のオブジェクトのペア」と「異なるオブジェクトのペア」という2つのクラスを持つ分類問題と見なすことができます。 さらに、「同一のペア」のクラスはゼロに近くグループ化され、異なるものは-反対に、傍観者のどこかになります。 従来、分類子は類似性の数値的尺度(たとえば、0から1)を提供する必要があります。これは、これらが異なるオブジェクトである可能性が高いほど大きくなります。 さらに、システムの要件に応じて、 第1種および第2種のエラーが依存する決定を行うためのしきい値が決定されます。
しない方法
最初に、これらのパラメーターを見て、差分ベクトルのノルム、つまりコンポーネントの平方和のルートを見つけたいだけです。
 。 つまり、パラメーターが座標と見なされる場合、サンプル間のユークリッド距離として。 小さいほど、これら2つのオブジェクトは「類似」している、つまり、同じである可能性が高くなります。 これは正しいですが、いくつかの制限があります。すべてのパラメーターは無相関(相互に独立)でなければならず、それらは同じ分布でなければなりません(それらは同等でなければなりません)。 通常、これは当てはまりません(たとえば、身長と体重は独立していると見なされるべきではなく、鼻の形は口の形や髪の長さよりもはるかに信頼性の高い特性です)。 次に、より重要なパラメーターを強化し、重要性の低いパラメーターを弱めるために、異なるコンポーネントに異なる重みを選択しましょう。
。 つまり、パラメーターが座標と見なされる場合、サンプル間のユークリッド距離として。 小さいほど、これら2つのオブジェクトは「類似」している、つまり、同じである可能性が高くなります。 これは正しいですが、いくつかの制限があります。すべてのパラメーターは無相関(相互に独立)でなければならず、それらは同じ分布でなければなりません(それらは同等でなければなりません)。 通常、これは当てはまりません(たとえば、身長と体重は独立していると見なされるべきではなく、鼻の形は口の形や髪の長さよりもはるかに信頼性の高い特性です)。 次に、より重要なパラメーターを強化し、重要性の低いパラメーターを弱めるために、異なるコンポーネントに異なる重みを選択しましょう。  。
。
ここで非常に正しい考えに至ります。すべての種類の係数を頭からではなく、実践から、つまりデータセットでうまく機能するように選択する必要があります。 機械学習では、これは「教師による学習」と呼ばれます:一連のデータ(異なるクラスと同一のクラスのオブジェクト、それらがどのクラスに属するかを最初に知る)が取得され、「トレーニングサンプル」と呼ばれます。可能な限り最適に機能しました(これを「トレーニング」と呼びます)。 次に、「テストサンプル」と呼ばれる別のデータセットにモデルを適用することで、モデルがどのように機能するかを確認し、どの程度うまくいったかを結論付けることができます。
そのため、重みを決定します。 これを行うには、テストサンプルからオブジェクトのすべてのペアを調べ、各コンポーネントについて、同じペアと異なるペアの平均値と分散を計算します。 しかし、これで次に何をするかは明確ではありません。 重みは大きくする必要があり、平均値間の距離は大きくなります(
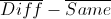 )さらに、分散が非常に大きい場合、つまり、情報よりもコンポーネントの方がノイズである可能性が高い場合、それらを小さくする必要があります。 この段階での私の最適化の試みはすべて、最も重要なコンポーネントの1つを使用する必要があり、残りを考慮する必要がないという事実につながりました。これは明らかに良い結果をもたらさないでしょう。 最後に、分散をスコアし、各コンポーネントについてカウントしました
)さらに、分散が非常に大きい場合、つまり、情報よりもコンポーネントの方がノイズである可能性が高い場合、それらを小さくする必要があります。 この段階での私の最適化の試みはすべて、最も重要なコンポーネントの1つを使用する必要があり、残りを考慮する必要がないという事実につながりました。これは明らかに良い結果をもたらさないでしょう。 最後に、分散をスコアし、各コンポーネントについてカウントしました  、指数kは経験的に選択され、さまざまなパラメーターのセットに対して、最良のインジケーターは0.01と4の両方に等しくなることが判明しました。
、指数kは経験的に選択され、さまざまなパラメーターのセットに対して、最良のインジケーターは0.01と4の両方に等しくなることが判明しました。
はい、そのような方法は、単にベクトルのノルムを計算するよりもはるかに良い結果をもたらしました。 しかし、彼には少なくとも2つの重大な欠点があります。 最初に目を引くのは、指から吸い込まれる重みの公式です。これは、最適性に疑問の余地がないことを意味します。 第二に、すべてのコンポーネントは別々に独立して考慮されます。つまり、それらの非相関が暗示されますが、これは一般に正しくありません。
線形回帰
正しいアプローチは、問題を数学的に形式化し、ある意味で最適なソリューションを見つけることです。 ご存知のように、最も単純な関数は線形関数ですので、次の形式の関数を探します。
 (はい、見た目は同じ重量に非常に似ています)。
(はい、見た目は同じ重量に非常に似ています)。  そのような関数を見つけることを線形回帰と呼びます。 係数b 0 、b 1 、... b nは、最小二乗法によるこの関数がテストサンプルの正しい値に最適になるように選択します。 正しい値は、同一のオブジェクトの場合はY = 0、異なるオブジェクトの場合はY = 1です。 ゼロ差分ベクトルでは同じオブジェクトが保証されているため、b 0の値は0に等しくなるように直感的に思われます。 しかし、推測ゲームをプレイして、b 0を正直に計算しません。 したがって、基本的には、n次元空間で方向を決定します。この方向では、同じペアと異なるペアが最も強く異なります。
そのような関数を見つけることを線形回帰と呼びます。 係数b 0 、b 1 、... b nは、最小二乗法によるこの関数がテストサンプルの正しい値に最適になるように選択します。 正しい値は、同一のオブジェクトの場合はY = 0、異なるオブジェクトの場合はY = 1です。 ゼロ差分ベクトルでは同じオブジェクトが保証されているため、b 0の値は0に等しくなるように直感的に思われます。 しかし、推測ゲームをプレイして、b 0を正直に計算しません。 したがって、基本的には、n次元空間で方向を決定します。この方向では、同じペアと異なるペアが最も強く異なります。
(ソース)二乗誤差の合計は次のように決定されます。
 。 以下、Mはテストサンプル内のオブジェクトの数、上付き文字はサンプル内のオブジェクトの数、下付き文字はオブジェクトのコンポーネントの数を示します。 この誤差は、各成分に関する導関数がゼロに等しくなる点で最小化されます。 初等数学は、システムAb = fに導きます。ここで、Aは行列(n + 1)*(n + 1)です。
。 以下、Mはテストサンプル内のオブジェクトの数、上付き文字はサンプル内のオブジェクトの数、下付き文字はオブジェクトのコンポーネントの数を示します。 この誤差は、各成分に関する導関数がゼロに等しくなる点で最小化されます。 初等数学は、システムAb = fに導きます。ここで、Aは行列(n + 1)*(n + 1)です。  、
、 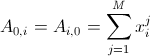 、
、  、i、k = 1..n。
、i、k = 1..n。 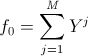 、
、 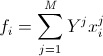 。 テストサンプルから行列要素を計算し、システムを解き、係数を取得し、関数を作成します。
。 テストサンプルから行列要素を計算し、システムを解き、係数を取得し、関数を作成します。
係数b iの一部がゼロ未満であることが判明するのは奇妙に思えるかもしれません。つまり、オブジェクトがこのパラメータでより強く異なる場合、それらはより類似しています。 実際、これには何の問題もありません。異なるパラメーター間の相関を調べただけです(たとえば、大まかに言えば、このパラメーターは別のパラメーターでのみ成長し、3番目のパラメーターを補正します)。
私の経験では、このような関数は、ランダムに選択された重みよりも、同一のオブジェクトと異なるオブジェクトのペアを区別することを示しています。 この機能はある意味で最適であるため、これは驚くことではありません。
問題?
どのような問題が発生する可能性がありますか?
最初に、n個のパラメーターの関数の係数を決定するには、サイズ(n + 1)*(n + 1)の行列を計算する必要があります。つまり、256x256画像のすべてのピクセルを個別のパラメーターとして表示することはできません。十分なメモリがありません。 ここでは、次元、特にPCAを縮小する従来の方法に頼ることができます。
 または、いくつかの最も重要なパラメーターを選択することができます(たとえば、異なる平均値が同じ、または大きすぎる分散の平均値を超えないパラメーターをふるいにかけます)。 そして、誰も記事を完全に読んでいないので、例えば7で終わるような、最も美しい数字を持つオプションを選ぶことをお勧めします。
または、いくつかの最も重要なパラメーターを選択することができます(たとえば、異なる平均値が同じ、または大きすぎる分散の平均値を超えないパラメーターをふるいにかけます)。 そして、誰も記事を完全に読んでいないので、例えば7で終わるような、最も美しい数字を持つオプションを選ぶことをお勧めします。
別の問題は、線形近似では不十分で、関数のクラス分離が不十分すぎる場合です。 その後、より複雑な分類子-adaboost 、 SVM +カーネルトリック( トピックに関する記事 )などを適用できます。
「教師による指導」のすべてのシステムの別の重要な問題は、 再訓練です。 大まかに言って、多くの異なるパラメーターがある場合、トレーニング中に、実際にはそうではないパターン(ランダムな変動)を見つけることができます。 次に、トレーニングセットの外側をチェックすると、この疑似パターンは存在しなくなり、認識結果に悪影響を及ぼします。 ウィキペディアでは、正規化、相互検証など、これに対処する方法に言及しています。

エラーのあるサンプルで学習すると、結果が悪化する可能性もあります。 トレーニングサンプルに多くの誤った値がある場合、最終結果に大きく影響する可能性があります。 従来、これは次のように解決されます。トレーニングが行われ、その後、このモデルで大きなエラーを生成するオブジェクトはトレーニングサンプルから破棄されます。 新しい「間引かれた」トレーニングサンプルが再びトレーニングされます。 必要に応じて、手順を数回繰り返すことができます。
結論
アウトラインの比較、テールの検出、または指のカウントのためのトリッキーなシステムを思いついたとしても、おそらく評価関数を構築して決定を下す必要があるパラメーターのベクトルがあり、有用な機械学習が必要になります。 そして、最も単純な数学的モデルでさえ、何らかの方法で最適であるため、「一般的な考慮事項」よりもはるかに良い結果をもたらします。