
まえがき
私は、ユーザーが自分の意見で美しい写真を時々追加する墓地を1つ持っています。
ユーザー自身がモデレートします。
また、同じ画像が複数回追加される場合があります。 通常、ポストモデレーションとともに決定されたもの。
しかし、類似または同じ画像がすでにロードされているかどうかを確認することが毎回困難になるときが来ました。
そして、重複の自動検索を詳しく調べる時が来たという考えが浮上しました。
調査
最初は、 SURF記述子に目が向けられ、非常に良い結果が得られました。
しかし、写真のコレクションとの一致を確認するのは複雑であるため、私は急いで他のソリューションを検討しないことにしました。
直観的に、SIFT / SURF記述子に似ているが、偶然の一致を迅速にチェックできる機能を備えた写真のいくつかの兆候を強調したいと思います。
少し努力して、 知覚ハッシュのアイデアに出会いました。
それらは、データベースの作成と検索の両方に十分に単純なように見えました。
要するに、知覚的ハッシュは、画像を説明するいくつかの記号の畳み込みです。
このようなハッシュの主な利点は、 ハミング距離を使用して他のハッシュと比較しやすいことです 。
理想的には、2つの画像のハッシュ距離がゼロの場合。 次に、これらの写真が(ほとんどの場合)同一であることを意味します。
この距離がそれほど複雑ではないSQLクエリを使用して計算できることは特に魅力的でした。
SELECT * FROM image_hash WHERE BIT_COUNT( 0x2f1f76767e5e7f33 ^ hash ) <= 10
そのようなハッシュをより良くする方法を理解することは残っています。
後続の記事では 、このタイプのハッシュを分離する3つの方法について説明しました。
aHash(平均ハッシュ)と呼ばれる平均値をチェックするための最も単純なアルゴリズムと、オープンソースプロジェクトpHash (知覚ハッシュ)に実装されている最も関連するオプションに加えて、 David Oftedalによって提案された別の説明-dHash(差分ハッシュ)つまり、平均ピクセル値ではなく、前のピクセル値との比較です。
いくつかのテストの後、それが判明した
aHashは動作不能であり、大量の誤検知を引き起こします。
dHashは1桁上手く機能しますが、それでも多くのエラーは満足のいくものではありません。
pHashは、最も関連性の高い結果を得るのに最適であることが判明しましたが、画像の変更に対してより敏感です。
一般に、pHashは小さな著作権マークが適用されている場合でも、写真の身元を確認できます。 色、コントラスト、明るさ、サイズ、さらにはわずかな幾何学的な変化にも反応しません。
これらのすべての利点には、完全に正当な制限があります。ハッシュは全体像を表し、完全な複製を検索するように設計されています。
言い換えれば、そのようなハッシュは、クロップのある重複画像、スケールの変更、画像の側面のサイズ、または画像の内容に対する直接的な部分的または深刻な干渉を見つけるタスクには無関係です。
解決しよう
状況を少し分析した結果、ユーザーがコンテンツに変更を加えた写真を追加する可能性は低いという結論に達しました。
たとえば、花、巨大な濡れたタグを描く、または何らかの方法で写真を変更します。
しかし、切り抜き付きの写真を追加するのは非常に現実的です。 たとえば、重要な部分を切り取ったり、アスペクト比を変更したり、何かを増やしたりします。
したがって、完全一致または部分一致のチェックに加えて、少なくとも小さなもののトリミングをチェックする必要がありました。
ピクチャごとに1つのハッシュで同様の問題を解決することはできません。
しかし、このようなハッシュを実装するのは簡単であるため、この制限を回避し、それらの助けを借りて画像の一部を見つける方法について少し考えたいと思いました。
1つのハッシュは適切ではないため、ハッシュのリストを取得する必要があります。 各ハッシュは画像の一部のみを記述します。
しかし、どこでどのように写真を切り取るかをどのようにして知るのでしょうか?
これは、SURFでローカル属性を取得するのに便利な場所です。
言い換えれば、発見されたポイントによって何らかの形で写真を切り抜く必要がありました。
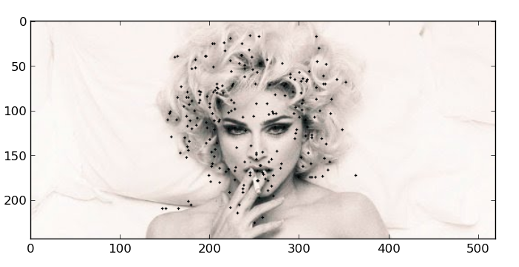
図1.要求された画像から見つかったポイント。

図2.保存された画像から見つかったポイント
(少なくともわずかに)同様の領域が一致するように画像をカットする必要があるため、キーポイント(特徴)のk-meansクラスタリングを試みました。
画像の内容があまり変わらず、見つかったローカルフィーチャがほとんど変わらない場合、おそらくこれらのローカルポイントのクラスタリング後の重心もほぼ一致するはずです。
これがこのアプローチの主なアイデアです。

図3.点は1つのクラスターの中心を示しています。

図4.点は3つのクラスターの中心を示します。 よく見ると、上部の重心は図3の中心とほぼ一致しています。
ほぼ収束するような重心を見つけるには、クラスターの数を変更して、たとえば20回クラスタリングを実行する必要がありました。
そして、各クラスターの極値で切断することができました。
20クラスターの制限では、21 * 20/2 = 210の重心が取得されます。 そして、1つの画像あたりの合計ハッシュ210 +全画像のハッシュ= 211ハッシュ。
しかし、32ピクセル未満のクリッピングを破棄し、最終的には、たとえば191ハッシュを取得します。
このアプローチは、写真全体のハッシュを比較するよりも良い結果を示しましたが、明らかなミスのためにまだ満足のいくものではないことが判明しました。 視覚的にスライスは一致しているように見えますが、ハッシュのチェックは失敗します。
ここで、アイデアはすでにこのベンチャーをやめ、別の方向に掘るために忍び寄っています。
しかし最後に、固定された側面または座標の形式がどのような役割を果たしているかを確認することにしました。 そして、これにより一致の数を増やすことができることが判明しました。
切り取った画像の座標が8の倍数になるように、私は突く方法を使用してそれをピックアップしました。

図5.クラスタリングによる一致する画像の切り取り
試作機
次に、実際にそのようなモデルの操作性を検証する必要がありました。
すべてがすぐに写真とともに墓地に転送され、データベース全体のインデックスが作成されました。
データベースには1,235枚の写真と194,710枚のハッシュがありました。
そして、BIT_COUNT(hash1 ^ hash2)はかなり高価な操作であり、さらに注意が必要であることが判明しました。
また、200のハッシュすべてを一度に実行する1つの大きなリクエストよりも、200のリクエストを実行する方が時間がかかります。
私の弱いサーバーでは、このような大きな要求には少なくとも2秒かかります。
合計で、1つの画像の検索には、ハミング距離を計算するために200 * 194 710 = 38 942 000操作が必要です。
したがって、MySQLで距離を計算する実装を作成した場合の違いを確認することにしました。
違いは取るに足らないものであり、さらに、カスタム関数を支持しないことが判明しました。
興味のために、C ++でハッシュのコレクションで検索を実装しようとしました。
考えが信じられないほど単純な場合:ハッシュのリスト全体をデータベースから取得し、それらを調べて、距離を手動で計算します。
C ++でハミング距離を計算する例
typedef unsigned long long longlong; inline longlong hamming_distance( longlong hash1, longlong hash2 ) { longlong x = hash1 ^ hash2; const longlong m1 = 0x5555555555555555ULL; const longlong m2 = 0x3333333333333333ULL; const longlong h01 = 0x0101010101010101ULL; const longlong m4 = 0x0f0f0f0f0f0f0f0fULL; x -= (x >> 1) & m1; x = (x & m2) + ((x >> 2) & m2); x = (x + (x >> 4)) & m4; return (x * h01)>>56; }
そして、そのようなアイデアは、SQLクエリを使用した場合の2倍の速度で実現します。
さらに、ハッシュの数が多いため、重複を決定するためのルールを策定する必要がありました。
たとえば、200個の一致のハッシュが1つある場合、その写真は重複していると見なしますか? おそらくない。
ハッシュの20%以上が一致した場合もありましたが、写真は間違いなく複製ではありません。
また、10%の一致がありますが、重複しています。
したがって、合計数に対して検出されたハッシュの数は、検証の保証ではありません。
明らかに誤った一致を除外するために、見つかった画像のSURF記述子の計算を使用し、要求された画像との一致の数をカウントしました。
関連する結果を表示できましたが、追加の処理時間が必要です。 ほとんどの場合、より最適なオプションがあります。
エピローグ
このアプローチにより、満足のいく時間内に適切な範囲でトリミングされた写真を見つけることができました。
最適とはほど遠いものであり、操作や最適化の余地が多くあります(たとえば、クラスタリング後にハッシュを確認し、重複を破棄することをお勧めします。これにより、ハッシュの数が2つまたはそれ以上に減ります)。
しかし、私は、学問的ではないにせよ、単純な好奇心にとって興味深いことを願っています。
参照資料
habrahabr.ru/post/120562-ハッシュの説明、翻訳
en.wikipedia.org/wiki/Hamming_Distance-ハミング距離
en.wikipedia.org/wiki/SURF-サーフキーポイント
en.wikipedia.org/wiki/K-means-クラスタリング
phash.org -pHashプロジェクト
www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html-ハッシュタイプの比較
01101001.net/differencehash.php-差分ハッシュ
github.com/valbok/img.chk/blob/master/bin/example.py-画像からのハッシュ抽出の実装
github.com/valbok/leie/blob/master/classes/image/leieImage.php-ハッシュの別のバリエーションですが、PHP